唯一 ID 生成原理与 PHP 实现
snowflake算法
虽然PHP提供了一个生成唯一ID的函数uniqid(),但这个函数真的可以生成唯一ID吗?我们来看看uniqid()的具体实现:
PHP_FUNCTION(uniqid)
{
...
gettimeofday((
struct timeval *) &tv, ( structtimezone *) NULL);
sec = (
int) tv.tv_sec;
usec = (
int) (tv.tv_usec % 0x100000);
spprintf(&uniqid, 0,
"%s%08x%05x", prefix, sec, usec);
RETURN_STRING(uniqid, 0);
}
从代码可以看出,uniqid()是通过微妙级时间戳来实现的,在分布式高并发的情况下,ID的重复率是很高的,所以我们不能使用uniqid()来生成唯一ID。
snowflake算法
既然不能单纯靠时间戳来保证唯一性,那么是不是可以增加以下特征值来保证呢?为此,Twitter公司发明了snowflake算法。snowflake算法的核心原理是把一个64位的整数分为3个部分,如下图:
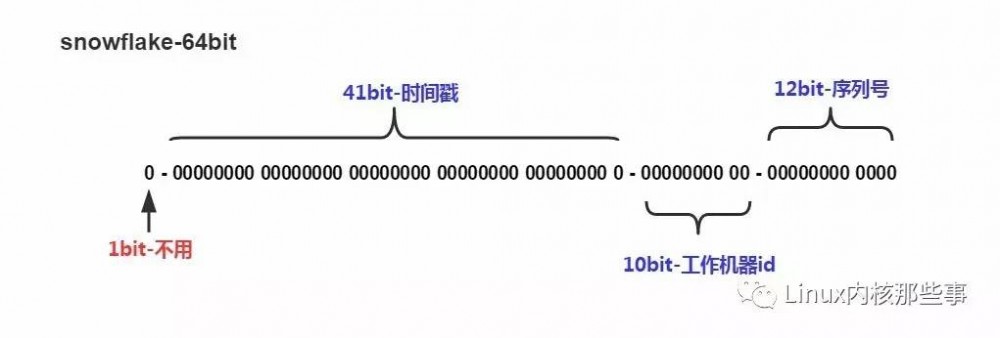
如上图所示,高端的第一位不使用,接着的41位字节用于存储毫秒级的时间戳,紧跟着时间戳的10位作为机器ID,而最后12位为序列号。
-
对于不同的机器来说,可以为每一台机器分配一个唯一的机器ID,这样就可以保证每台机器锁生成的ID不会重复。
-
对于同一台机器,如果同一时刻多个客户端并发请求,那么可以通过增加序列号来保证ID唯一性。
默认情况下41位的时间戳可以支持该算法使用到2082年(需要通过减去一个起始时间戳),10位的工作机器ID可以支持1023台机器,12位的序列号支持1毫秒产生4095个自增序列ID。
也就是说1台机器1秒可以承受4095000个并发,可以胜任任何场景。snowflake算法的代码实现大概如下:
static
uint64_t last_ts = 0;
staticuint64_t sequence = 0;
staticuint64_t datacenter_id = 0;
// 获取毫秒时间戳
uint64_t current_timestamp()
{
structtimeval tv;
uint64_t retval;
if(gettimeofday(&tv, NULL) == -1) {
return0ULL;
}
retval = (u64_t)tv.tv_sec * 1000ULL +
(u64_t)tv.tv_usec / 1000ULL;
returnretval;
}
// 如果在同一毫秒内超过了并发现在, 那么等待下一毫秒
uint64_t skip_next_millis()
{
uint64_t ts;
while(1) {
ts = current_timestamp();
if(ts > last_ts) {
break;
}
}
returnts;
}
// 获取下一个ID
uint64_t get_next_id()
{
uint64_t retval, ts;
ts = current_timestamp();
if(ts == last_ts) { // 同一毫秒内多个并发
sequence = (sequence + 1) & 0xFFF; // 增加序列号计数器
if(sequence == 0) { // 计数器用完
ts = skip_next_millis(); // 等待下一毫秒
}
}
else{
sequence = 0; // 清空序列号计数器
}
last_ts = ts;
retval = (ts << 22) | (datacenter_id << 12) | sequence;
returnretval;
}
PHP实现唯一ID生成函数
严格来说使用PHP是不能实现snowflake算法的,这是因为PHP的运行机制导致的。一般一台机器会启动多个PHP进程,而且进程之间是不能共享内存的,就是说多个PHP进程之间不能使用同一个序列号,这样就会导致不同进程生成的ID可能会重复。而且每次请求完,PHP都会释放本次请求的所有资源,那么就不能记录最后一次时间戳和序列号计数器的值(虽然可以使用文件或者memcached之类实现,当这样性能就会降低很多)。所以说使用PHP是不能实现snowflake算法的。
不能使用PHP代码实现snowflake算法,但是可以通过PHP扩展来实现,下图是PHP-FPM的运行机制:
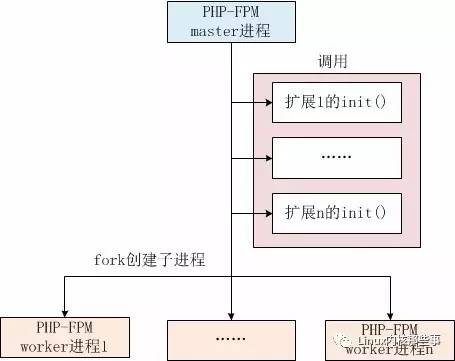
从上图可以看出,在创建worker进程之前先会调用每个扩展的init()函数(PHP_MINIT_FUNCTION函数),所以我们可以在init()函数创建一块共享内存,然后每个worker进程就可以共用这块内存(因为fork之前创建的共享内存可以在子进程中共用)。
因为不同的进程并发访问共享内存可能会导致数据不一致的问题,所以必须解决资源竞争的问题,解决资源竞争最常用的方法就是使用锁。
进程间一般使用的锁有:信号量和自旋锁。信号量与自旋锁的不同之处是,信号量会发生进程上下文切换,而自旋锁不会。
当然这两种锁都可以解决资源竞争问题,但是相对于生成唯一ID这种场景,使用自旋锁会有更好的性能,这是因为生成ID这个过程非常短,而自旋锁锁不需要切换上下文。
自旋锁
自旋锁的原理是不断测试锁是否能够被上锁,如果能够上锁就进行上锁操作,否则就不断重复上面的操作。下面代码是一个简单的实现:
void
spin_lock(atomic_t *
lock
,
int
id)
{
inti, n;
for( ;; ) {
if (* lock== 0 &&
__sync_bool_compare_and_swap(
lock, 0, id)) {
return;
}
if(ncpu > 1) {
for(n = 1; n < 129; n << 1) {
for(i = 0; i < n; i++) {
__asm(
"pause");
}
if (* lock== 0 &&
__sync_bool_compare_and_swap(
lock, 0, id)) {
return;
}
}
}
sched_yield();
}
}
__sync_bool_compare_and_swap(var, old, new)函数是一个原子性操作,作用就是比较var与old的值,如果相等就把var的值改为new,如果不相等就继续进行这个操作直到成功为止。这里有个小技巧,就是当长时间获取不到锁的情况下,我们会调用sched_yield()系统调用让出CPU,从而避免过度使用CPU资源。
总结
snowflake算法可以有效的生成唯一ID,而且通过配置机器ID可以很好地支持分布式环境。本文介绍了怎么使用PHP扩展来实现 snowflake算法,具体实现可以参考本人所写的Atom扩展: https://github.com/liexusong/atom
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

