提取 Druid 的 SQL 解析器
认识 Druid
Druid 是阿里巴巴公司开源的一个数据库连接池,它的口号是: 为监控而生的数据库连接池
根据 官方 wiki 的介绍
Druid 是一个 JDBC 组件库,包括数据库连接池、SQL Parser 等组件,DruidDataSource 是最好的数据库连接池。
显然,官方有意无意地强调了 DruidDataSource 是最好的数据库连接池 -_- ...
Druid SQL 解析器
Druid 作为一个数据库连接池,功能很多,但我接触 Druid 的时候,却不是因为它有世界上最好的数据库连接池实现。而是因为有些开源项目(比如,mycat),借用了 Druid 的 SQL 解析功能。我需要研究这个开源项目,发现作为一个数据库中间件,它的 SQL 解析功能是直接引用的 Druid,Druid 包除了 SQL 解析模块的代码外,其它的代码并没有使用到。而这部分代码显然让人在研究 SQL 解析器代码时容易分心,产生厚重感和焦虑感。
Druid 本来的代码结构如下:
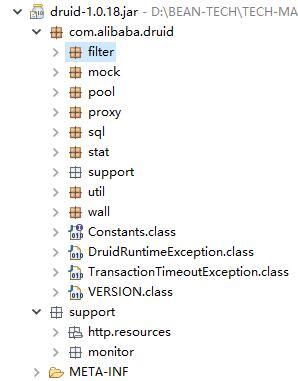
提取 Druid SQL 解析器
在确认我并不需要使用到全世界最好的数据库连接池后,我想把除了 SQL 解析部分的代码全部剔除,仅仅留下 SQL 解析器模块。
一开始的做法当然是“暴力删除”,通过对代码的整体浏览,大概判断出哪些 package 与 SQL 解析有关,其余的直接删除。这样做会有些问题,比如说直接删除后在 IDE 中会立马浮现一些小红叉叉,但令人感到愉悦的是,Druid 的模块分解做得十分优秀,SQL 解析模块基本上作为一个工具模块,与其它模块实际上是分离的。
因此虽然是“暴力删除”,却也得到了一个令人满意的结果。
由于我只关注的是 Druid 对 MySQL 方言的解析,并且也不想看到 Druid 解析其它数据库方言的内容,也不愿被 Druid 那些为了适应多种数据库的“兼容性代码”混淆视听,因此狠下心来,把对其它 SQL 方言的支持也全都剔除,只留下与 MySQL 相关的代码。
剔除其它 SQL 方言并不是一个麻烦事,这也得益于 Druid 优秀的代码层次结构,基本上,只是拿类似以下形式的代码动刀
if type is oracle:
do something;
else if type is db2:
do something;
else if type is H2:
do something;
else if type is MySQL:
do something;
把上面的代码,修改成:
if type is MySQL:
do something;
else:
throw some exception;
经过两层提取后,整个 Druid 就只剩下这些代码了
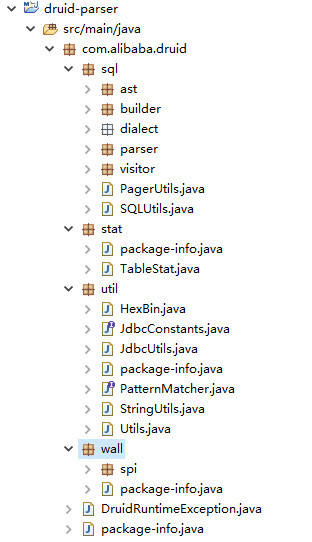
这是一个好的开始,着手研究并调试 SQL 解析器的代码也近在咫尺。
正文到此结束
热门推荐










相关文章

近期评论
-
主要用的是AI
-
博主的博客用的什么技术栈,内容都是干货,赞
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
-
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

