AI 之 TensorFlow
AI
(Artificial Intelligence)人工智能及机器学习(Machine Learning)最近大热,Google - Deep Mind的AlphaGo踢馆人类所向披靡,最终宣布正式进入智能时代1.0。我们今天也来体验学习一下Google的人工智能项目。
1. Jeff Dean
老传统,我们先来看看这位Google TensoFlow的主要负责人,在加州山景城除了拉里佩奇Larry Page和布林Sergey Brin,Google数一数二,被用来打造下一代Google核心大脑的(Google Brain)的头号人物Jeff Dean。

列一下大神的大作,颤抖一下吧:
-
Google MapReduce
-
Google BigTable
-
Google Spanner
-
Google AdSense
-
Google Translate
-
Google Brain
-
LevelDB
-
TensorFlow
够重量级了吧,说其影响了第三代互联网及第四代也不夸张,开启了互联网大数据及人工智能时代。
Jeff Dean于2009年当选美国工程院院士。
2. Artificial Neural Networks, ANNs
在开始介绍TensorFlow之前我们先看一个TensorFlow的Online Playground,在线神经网络(Artificial Neural Networks,ANNs)!
http://playground.tensorflow.org
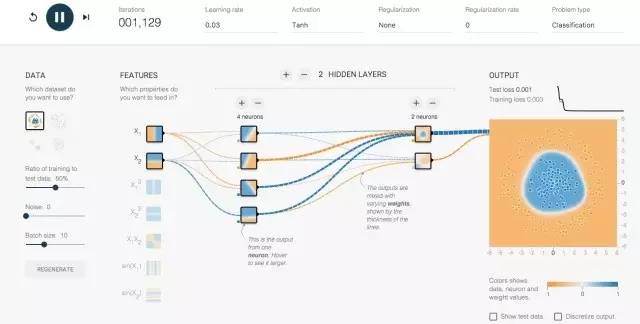
神经网络(NNs)主要模仿动物神经网络,进行分布式并行算法的数学模型。
神经网络最大的魔力,在于不需要用各种特征用来输入给机器学习系统,如上图事例,只需要输入最基本的x1, x2, 只要给予足够多层的神经网络和神经元,神经网络会自己组合出 最有用 的特征。
总体来说,神将网络需要大量神经元(节点)及:
-
每个神经元可以通过输出/激励函数(Activation Function)来计算来自其它相邻神经元的加权输入值
-
计算模型可以依靠大量数据训练
-
成本函数(Cost Function):定量评估对于给定输入值的输出结果离正确值的偏移,用于评估计算的精准
-
学习算法(Learning Algorithm):根据Cost Function的结果,自学,纠错
有了上述的核心,就有点智能感觉了,可以计算评估,并且可以递归自我学习。
3. TensorFlow Overview
TensorFlow是Google研发的第二代人工智能学习系统。官网描述,TensorFlow™ 是一个采用数据流图(data flow graphs),用于数值计算的开源软件库。节点(Nodes)在图中表示数学操作,图中的线(edges)则表示在节点间相互联系的多维数据数组,即张量(tensor)。
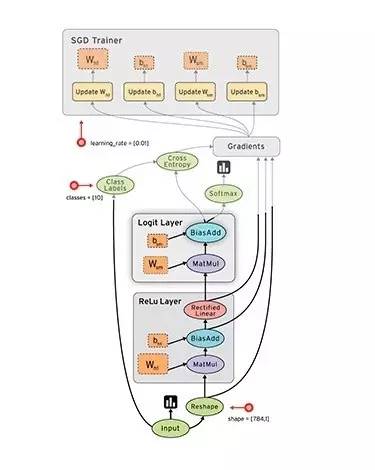
Tensor即张量,N维数组,Flow代表基于数据流图的计算,TensorFlow的计算就是张量从图的一端流动到另一端的并行计算。
张量:

TensorFlow架构灵活,可做到多平台并行计算,如台式机,服务器,云端,移动设备等,同时又可以充分发挥多核CPU或者GPU的强大并行计算能力。
CPU v.s. GPU
科普一下CPU与GPU的差别吧,为什么GPU会在深度学习时代又火了起来。
设计架构:
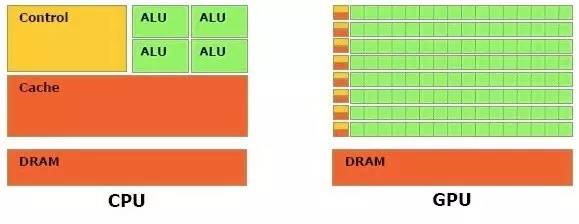
可以看出CPU的设计目标是处理不同数据类型,支持大量逻辑判断,分之跳转及中断处理;而GPU则诞生于目标处理大量图形图像(游戏),即大规模类型统一,相互依赖的数据,同时不需要被打断的纯计算环境,所以在架构设计上,GPU采用了数量众多的计算单元和超长流水线,仅保留简单控制逻辑,甚至省去了Cache。
所以,GPU天生具备大规模精良并发计算能力,而CPU的计算能力则只是很小一部分。大多数台式机甚至包括服务器,其CPU多核也没有超过2位数,每个核也包含了大量缓存及逻辑运算单元;GPU则称之为重核,如512核甚至上千之多。CPU被称之为Latency Oriented Cores, 而GPU则称之为Throughput Oriented Cores。
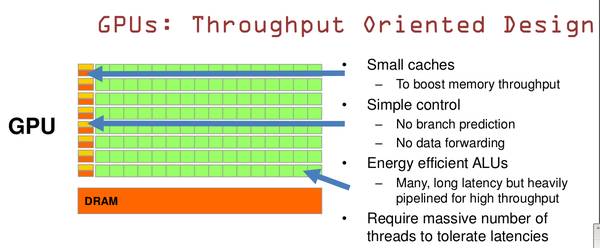
所以,不难看出为什么在深度学习领域,GPU为何能炙手可热,GPU最适合:
-
计算密集型程序(Compute-Intensive),其大部分时间花在寄存器,几乎没有延时,而内存及SSD的延时则不可同日而语(达上百倍,千倍差异)
-
并行计算程序,上百核同时做同样事情
有了上述的铺垫,不能看出对于Tensor张量的计算处理,GPU简直是张量计算的天堂。
TensorFlow特征
TensorFlow并不是一个严格的神经网络,只要你可以抽象为数据流图,便可以使用TensorFlow来构建计算。
TensorFlow用C++来编写,目前版本提供的API相对低阶,确实是C/C++风格,任君打造。当然也提供暴露了深度学习中流行的Python接口,及其它Google自己的Go, Java, Lua, Javascript, R等。
开源神器
Goolge近年来突然意识到开源的威力,赶紧跟上。
官网当然是官言,其实在这个互联网,深度学习时代,除了秀肌肉,研发产品,占领市场,最重要的是占领程序员,程序员是未来世界的缔造者,通过开源直接输出核心思想到程序员大脑,甚至让程序员反向输入。
4. 机器学习之-MNIST
接下来正式展开TensorFlow的介绍,注意,其中涉及大量数学,请自行脑补。
简单来说,机器学习即通过经验自动改进的算法程序。
MNIST
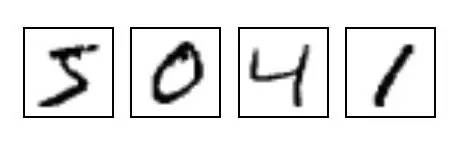
MNIST则为机器学习领域的一个经典问题,解决28*28像素的灰度手写数字图片识别,数字范围0-9,即人类的3-4岁左右水平,别小看。
人类的视觉系统是一大奇迹,我们可以毫秒级别轻易识别上述手写数字为5041,而我们的大脑则通过视觉皮层V1的包含1.4亿个神经元及与其他视觉皮层V2,V3,V4,V5构成数百亿神经元网络 - 超级计算机。
所谓学习,必然有学习的教程,官网提供了大概6万多训练图片,5千图片用语迭代验证及另外1万图片用语最终测试。
MNIST的数据集可以从官网下载Yann LeCun's website, 此人目前就职于Facebook。
Softmax Regression模型
数字如何和向量挂钩?又如何TensorFlow?
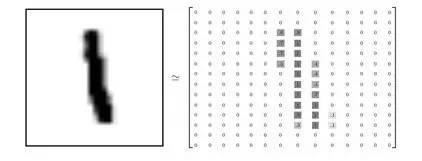
显然,对于上述28*28像素的图片,我们可以用数组表示,展成向量即, 28*28=784。
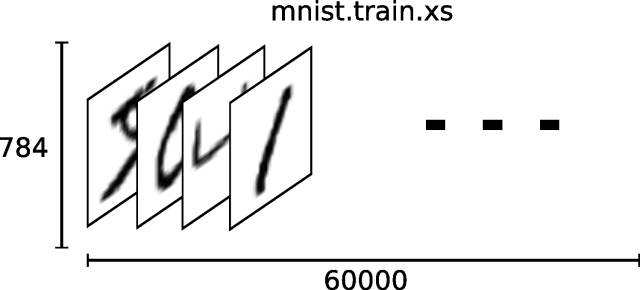
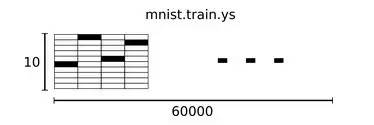
整个算法我们把MNIST分成两个数据集,图片训练数据集 xs ,每个图片对应标签 ys 。
所以在MNIST训练集 xs 中,张量为[60000, 784],第一个维度索引图片6w张训练图片,第二个维度则索引像素点28*28,在此张量的每个元素都表示某个像素的强度介于0-1之间:
而其对应的标签 ys 数据集是介于0-9的数字,为了简化这里使用了“one-hot vectors”。
one-hot即只有一位编码有效,如使用n位状态寄存器来对n个状态编码,任意时候只有其中一位有效。
在MNIST标签数据集中,我们用10维向量来表示某0-9的数字,如数字n(0-9)表示只有在第n维为数字1,其余维度都是0,如数字0,表示为:
[1,0,0,0,0,0,0,0,0,0]。
:warning: : 官网貌似写成11维,多了个0,所以众多copy模式也copyright。
这样,MNIST数据集标签组成一个[60000,10]的数字矩阵。
好了,有了上述的数据结构抽象,接下来整体算法就是要得出给定图片代表每个数字的概率,如模型推算一张包含9的图片代表数字9的概率为80%,而判断它代表数字8的概率为5%(上半部分小圆),给予其他数字更小概率值。
Softmax模型可以用来给不同对象分配概率,通常分为两步:
-
对图片像素值进行加权求和,如果这个像素具有很强证据证明这张图片不属于该类,则权值为负数,相反则为正数。

上图红色表示正,蓝色表示负数。
-
偏置量(bias),用于排除干扰
则图片x代表数字i的evidence表示为:
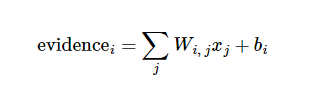
其中,wi为权重,bi为i的偏置量,j 代表给定图片 x 的像素索引用于像素求和。然后用softmax函数可以把这些证据转换成概率 y:
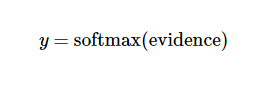
概率论登场,把softmax转换为, normalize的概率值,
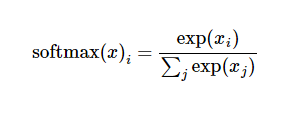
上述见证了数学建模功力,把给定的线性函数转换为10个数字的概率分布,通常这种转换通过把输入值当成幂指数求值,再正则化处理。幂运算则对应假设模型中的权重值,softmax的正则化使得总权重为1,即有效概率分布。
上述过程用图像化来描述的话:
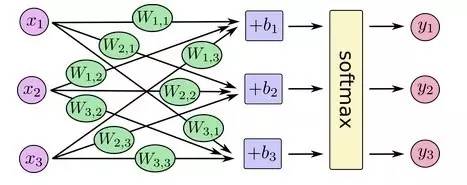
数学抽象处理:
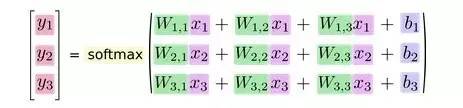
整理向量,用线性代数的矩阵乘法与向量相加:

在解释一下上面的 softmax 函数,
softmax function is a generalization of logistic function that maps a length-p vector of real values to a length-K vector of values.
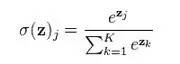
看了数学公式,应该会比较清楚了,是该元素的对数值,与所有元素对数值和的比值。其实softmax regression是一个将目标变量分成k类的算法,建模使用的是多项式分布。
再说透彻点,max针对两个输入,a和b,且a>b,则max则返回a;而softmax则考虑到了样本的概率权重来返回(避免垄断市场)。
如果考虑特殊的仅分两类的逻辑回归,则退化为伯努利分布,
下图举例说明softmax,以3个输入为例:
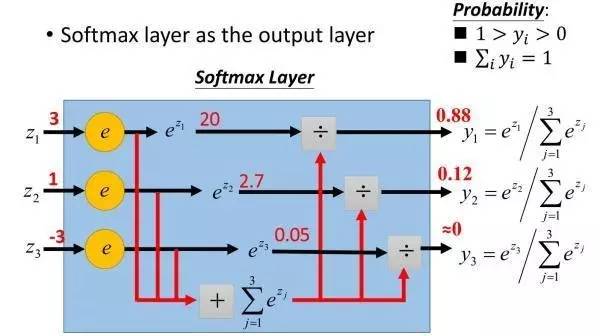
数学真是神奇的东西,不愧为众科学之魁宝,金字塔之尖。
各位程序大牛如果头晕,可以直接忽略,对于学数学分析的各位,请自行点赞。
5. 神经网络
官网给出的算法对于比较熟悉神经网络,softmax regression, 或者手写数字识别算法的可能比较简单,我们在稍微回顾梳理一下。
Sigmoid神经元
AI的智能体现在自动学习,对于神经网络如何引入学习算法则至关重要。
通过引入人工神经元sigmoid神经元,对于细微调整它的权重和偏移,只会很细小的影响输出结果,从而达到抗干扰,不断学习过程。
sigmoid:
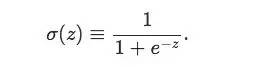
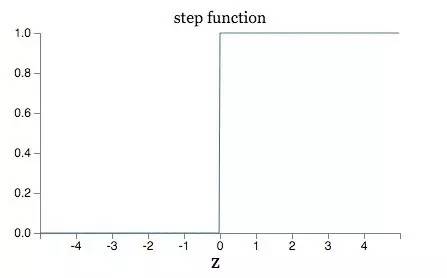
其本质是一个阶跃函数step的平滑版本:
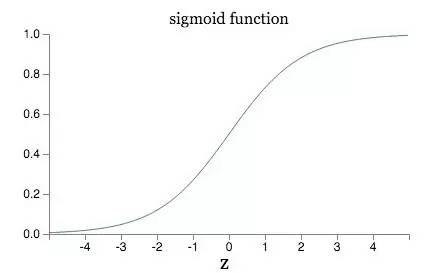
平滑处理:
其平滑度其实是微积分中的偏导数,对于权重微调,对于输出的微小改变:
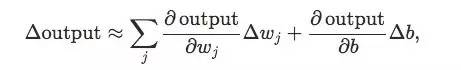
神经网络体系
有了神经元,接下来引入神经网络。同样,对于上述数字识别,如识别数字9,网络设计的自然方式是把图像像素强度编码作为输入进入神经元,而每一个输入值则介于0-1的强度,输出则根据某一阀值,如输出值大于0.5则表示神经网络分析该数字为9,否则不是。
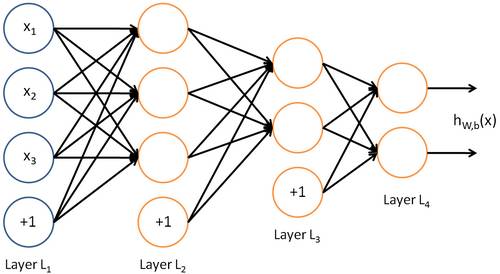
如下图所示,我们引入三层神经网络:
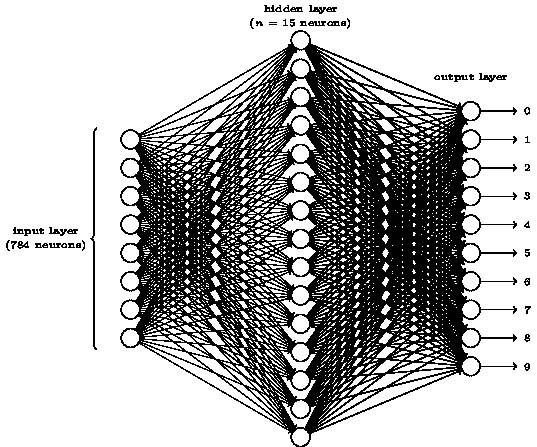
按照我们上文给出的28*28像素784作为左边的输入神经元,最右边则为输出的判断结果,而中间的隐藏层则主要通过计算判断,可以引入检测像素的重叠。
梯度下降学习算法
梯度下降算法是一个用于最优化的算法,求解无约束优化问题。梯度下降法的计算过程就是沿梯度下降的方向求解极小值,通常用负梯度方向为搜索方向,接近目标值,步长越小,前进越慢。
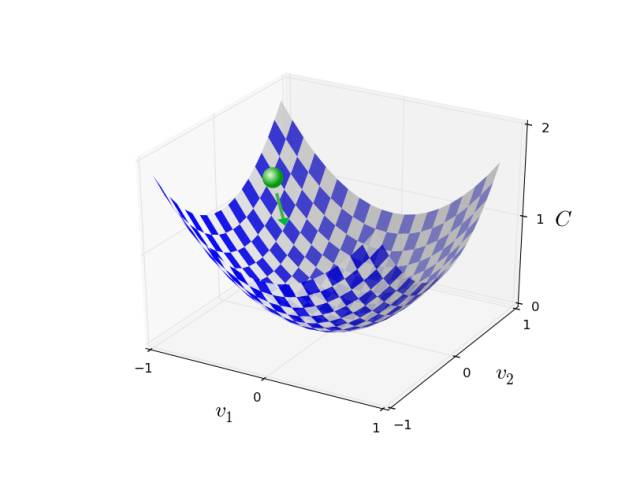
如上图梯度下降算法通过不断计算梯度∇C∇C,然后向着梯度相反的方向小步移动的方式让小球不断顺着坡面滑向谷底。为了充分发挥作用,我们通常选择一个足够小的学习率。
6. 数字识别算法
数字识别算法有很多种,如官网用到的加权法,简单的如灰度法,精度较高的如向量机等。
灰度法:
这个算法比较简单易懂,准确率较低,只有22%左右。大体思路是,直接根据提供像素的黑白强度,如2比1有更多的像素,所以2比1图像灰度更暗。所以,我们可以用训练数据来计算每个数字的平均暗度值。对于一张新图,我们就计算这张图有多暗,然后根据那个数字的平均暗度值和这张图的暗度值最接近,来猜测这张图是什么数字。
加权法(weighing evidence):
对于给定模版的像素进行重加权,而其它像素则轻加权,从而快速进行判断。为了并行计算,可以把一个图分解成4个神经元分别并行计算判断,如果4神经元都一起被触发,则给出判断结论,如我们判断0:


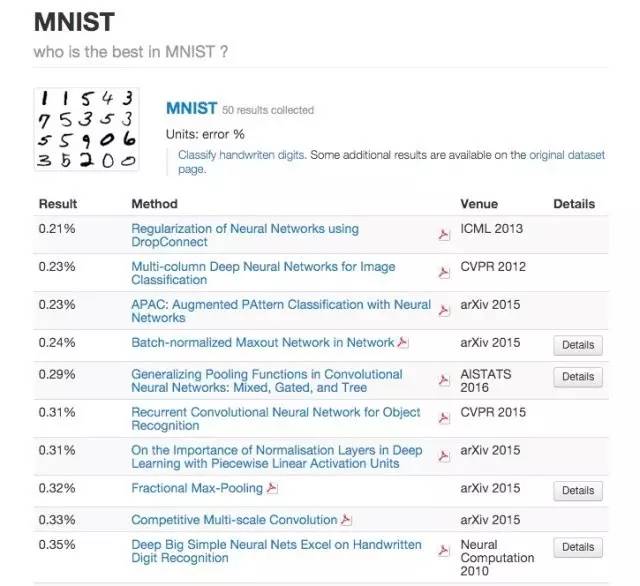
其他一些经典算法大家可以自行研究,下面列出了一些精准度排名算法:
7. TensorFlow数字识别实现
实现回归模型
官网使用极为简洁的代码:
import tensorflow as tf
import input_data
mnist=input_data.read_data_sets(" MNIST_data /", one_hot=True
x = tf.placeholder(" float ", [ None , 784])
W = tf.Variable(tf.zeros([784,10]))
b = tf.Variable(tf.zeros([10]))
y = tf.nn. softmax (tf.matmul(x,W) + b)
x和w都只是一个占位符,可以在TensorFlow运行某一计算时根据该占位符输入具体的值。
最后一行代码把向量化后的图片x和权重矩阵W相乘(matmul),加上偏置b,然后计算每个分类的softmax概率值。
成本函数-交叉熵
在机器学习中,通常需要定义指标来表示一个模型的成效,这个指标称为成本(cost)或损失(loss)。
交叉熵(cross-entropy)作为一种常见成本函数。
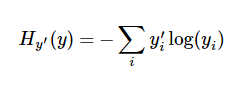
交叉熵是用来衡量我们的预测用于描述真相的低效性。具体数学公式及原理,请自行科普吧。
cross_entropy = -tf.reduce_sum(y_*tf.log(y))
注:机器学习及AI其实设计大量的数学推论,神经网络,这正是我华人的强项啊,希望华人可以在这个领域有所建树。
AI及TensorFlow的神奇之处,它会在学习中根据计算图,使用反向传播算法来预测估计目标最小化成本值,并用我们的优化算法不断演进以降低成本。
train_step = tf.train. GradientDescentOptimizer (0.01).minimize(cross_entropy)
其实就是我们上文提到的梯度下降算法。而TensorFlow的妙用就是,它在后台我们提供的计算图中,添加隐藏计算神经元,实现反向传播算法及梯度下降算法。
训练模式
接下啦就是启动session,开启10000训练模式:
sess = tf.Session()
sess.run(init)
for i in range(10000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
TensorFlow也提供了训练过程可视化,可以查看即时数据情况, TensorBoard。
8. 深度学习
神经网络中的权重和偏移是自动发现的,这些参数都是通过学习自动获得的。神经网络通过一系列的多层次结构抽象,把复杂问题逐步简化抽象,其中靠前的结构层响应简单问题,后层则响应复杂问题,多层的神经网络即深度神经网络。
总结
AI及神经网络,深度学习博大精深,设计非常多的专业知识,甚至考验数学功底。
我们抛砖引玉,入门了解。

公众号: 技术极客TechBooster

孪生公众号: 技术 + 金融 = 程序量化投资Venus

正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

