Scrapy学习(三) 爬取豆瓣图书信息
前言
-
Scrapy学习(一) 安装
-
Scrapy学习(二) 入门
有了前两篇的基础,就可以开始互联网上爬取我们感兴趣的信息了。因为暂时还没有学到如何模拟登陆,所以我就先抓像豆瓣这样不需要登陆的网站上的内容。
我的开发环境是 Win7 + PyChram + Python3.5 + MongoDB
爬虫的目标是豆瓣的日本文学标签下的所有书籍基本信息
创建项目
scrapy startproject douban
接着移动到 douban 目录下
scrapy genspider book book.douban.com
在spider目录下生成相应的BookSpider模板
编写Item
在items.py中编写我们需要的数据模型
class BookItem(scrapy.Item):
book_name = scrapy.Field()
book_star = scrapy.Field()
book_pl = scrapy.Field()
book_author = scrapy.Field()
book_publish = scrapy.Field()
book_date = scrapy.Field()
book_price = scrapy.Field()
编写Spider
访问豆瓣的 日本文学 标签,将url的值写到 start_urls 中。接着在Chrome的帮助下,可以看到每本图书是在 ul#subject-list > li.subject-item
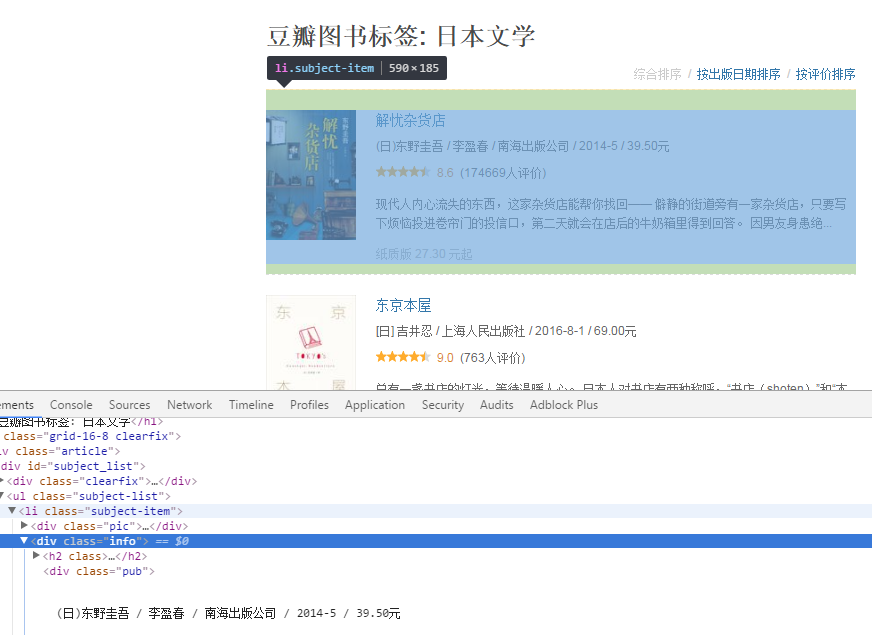
class BookSpider(scrapy.Spider):
...
def parse(self, response):
sel = Selector(response)
book_list = sel.css('#subject_list > ul > li')
for book in book_list:
item = BookItem()
item['book_name'] = book.xpath('div[@class="info"]/h2/a/text()').extract()[0].strip()
item['book_star'] = book.xpath("div[@class='info']/div[2]/span[@class='rating_nums']/text()").extract()[
0].strip()
item['book_pl'] = book.xpath("div[@class='info']/div[2]/span[@class='pl']/text()").extract()[0].strip()
pub = book.xpath('div[@class="info"]/div[@class="pub"]/text()').extract()[0].strip().split('/')
item['book_price'] = pub.pop()
item['book_date'] = pub.pop()
item['book_publish'] = pub.pop()
item['book_author'] = '/'.join(pub)
yield item
测试一下代码是否有问题
scrapy crawl book -o items.json
奇怪的发现,items.json内并没有数据,后头看控制台中的DEBUG信息
2017-02-04 16:15:38 [scrapy.core.engine] INFO: Spider opened
2017-02-04 16:15:38 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2017-02-04 16:15:38 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
2017-02-04 16:15:39 [scrapy.core.engine] DEBUG: Crawled (403) <GET https://book.douban.com/robot... (referer: None)
2017-02-04 16:15:39 [scrapy.core.engine] DEBUG: Crawled (403) <GET https://book.douban.com/tag/%... (referer: None)
爬取网页时状态码是403。这是因为服务器判断出爬虫程序,拒绝我们访问。
我们可以在settings中设定 USER_AGENT 的值,伪装成浏览器访问页面。
USER_AGENT = "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)"
再试一次,就发现items.json有值了。但仔细只有第一页的数据,如果我们想要爬取所有的数据,就需要爬完当前页后自动获得下一页的url,以此类推爬完所有数据。
所以我们对spider进行改造。
...
def parse(self, response):
sel = Selector(response)
book_list = sel.css('#subject_list > ul > li')
for book in book_list:
item = BookItem()
try:
item['book_name'] = book.xpath('div[@class="info"]/h2/a/text()').extract()[0].strip()
item['book_star'] = book.xpath("div[@class='info']/div[2]/span[@class='rating_nums']/text()").extract()[0].strip()
item['book_pl'] = book.xpath("div[@class='info']/div[2]/span[@class='pl']/text()").extract()[0].strip()
pub = book.xpath('div[@class="info"]/div[@class="pub"]/text()').extract()[0].strip().split('/')
item['book_price'] = pub.pop()
item['book_date'] = pub.pop()
item['book_publish'] = pub.pop()
item['book_author'] = '/'.join(pub)
yield item
except:
pass
nextPage = sel.xpath('//div[@id="subject_list"]/div[@class="paginator"]/span[@class="next"]/a/@href').extract()[0].strip()
if nextPage:
next_url = 'https://book.douban.com'+nextPage
yield scrapy.http.Request(next_url,callback=self.parse)
其中 scrapy.http.Request 会回调parse函数,用try...catch是因为豆瓣图书并不是格式一致的。遇到有问题的数据,就抛弃不用。
突破反爬虫
一般来说,如果爬虫速度过快。会导致网站拒绝我们的访问,所以我们需要在settings设置爬虫的间隔时间,并关掉COOKIES
DOWNLOAD_DELAY = 2
COOKIES_ENABLED = False
或者,我们可以设置不同的浏览器UA或者IP地址来回避网站的屏蔽
下面用更改UA来作为例子。
在middlewares.py,编写一个随机替换UA的中间件,每个request都会经过middleware。
其中 process_request ,返回 None ,Scrapy将继续到其他的middleware进行处理。
class RandomUserAgent(object):
def __init__(self,agents):
self.agents = agents
@classmethod
def from_crawler(cls,crawler):
return cls(crawler.settings.getlist('USER_AGENTS'))
def process_request(self,request,spider):
request.headers.setdefault('User-Agent',random.choice(self.agents))
接着道 settings 中设置
DOWNLOADER_MIDDLEWARES = {
'douban.middlewares.RandomUserAgent': 1,
}
...
USER_AGENTS = [
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)",
...
]
再次运行程序,显然速度快了不少。
保存到MongoDB
接下来我们要将数据保存到数据库做持久化处理(这里用MongoDB举例,保存到其他数据库同理)。
这部分处理是写在 pipelines 中。在此之前我们还要先安装连接数据库的驱动。
pip install pymongo
我们在 settings 写下配置
# MONGODB configure MONGODB_SERVER = 'localhost' MONGODB_PORT = 27017 MONGODB_DB = 'douban' MONGODB_COLLECTION = "book"
class MongoDBPipeline(object):
def __init__(self):
connection = MongoClient(
host=settings['MONGODB_SERVER'],
port=settings['MONGODB_PORT']
)
db = connection[settings['MONGODB_DB']]
self.collection = db[settings['MONGODB_COLLECTION']]
def process_item(self, item, spider):
self.collection.insert(dict(item))
log.msg("Book added to MongoDB database!",
level=log.DEBUG, spider=spider)
return item
其他
将运行项目的时候控制台中输出的DEBUG信息保存到log文件中。只需要在 settings 中设置
LOG_FILE = "logs/book.log"
项目代码地址: 豆瓣图书爬虫
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

