从JDK源码看StringBuffer
Java 中处理字符串时经常使用的 String 是一个常量,一旦创建后不能被改变。为了提供可修改的操作,引入了 StringBuilder 类,可看前面的文章《 从JDK源码看StringBuilder 》。但它不是线程安全的,只用在单线程场景下。所以引入了线程安全的 StringBuffer 类,用于多线程场景。
总的来说主要是通过在必要的方法上加 synchronized 来实现线程安全。
三种字符串类关系
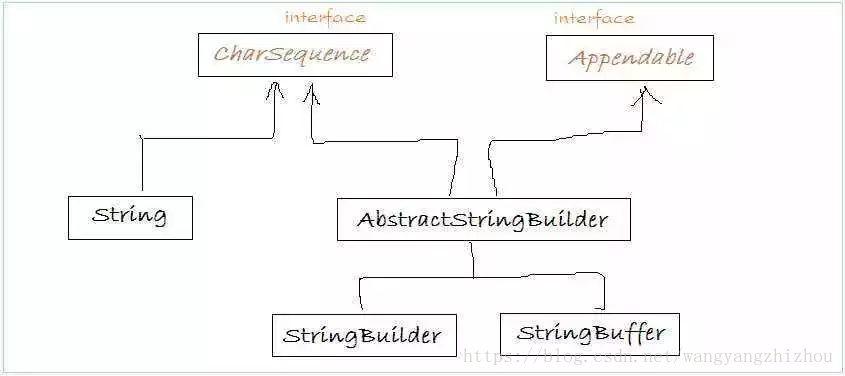
继承结构
--java.lang.Object
--java.lang.AbstractStringBuilder
--java.lang.StringBuffer
类定义
public final class StringBuffer extends AbstractStringBuilder implements java.io.Serializable, CharSequence
StringBuffer 类被声明为 final,说明它不能再被继承。同时它继承了 AbstractStringBuilder 类,并实现了 Serializable 和 CharSequence 两个接口。
其中 Serializable 接口表明其可以序列化。
CharSequence 接口用来实现获取字符序列的相关信息,接口定义如下:
length() charAt(int index) subSequence(int start, int end) toString() chars() codePoints()
public interface CharSequence {
int length();
char charAt(int index);
CharSequence subSequence(int start, int end);
public String toString();
public default IntStream chars() {
省略代码。。
}
public default IntStream codePoints() {
省略代码。。
}
}
主要属性
private transient String toStringCache; byte[] value; byte coder; int count;
toString
构造方法
有若干种构造方法,可以指定容量大小参数,如果没有指定则构造方法默认创建容量为16的字符串对象。如果 COMPACT_STRINGS 为 true,即使用紧凑布局则使用 LATIN1 编码(ISO-8859-1编码),则开辟长度为16的 byte 数组。而如果是 UTF16 编码则开辟长度为32的 byte 数组。
public StringBuffer() {
super(16);
}
AbstractStringBuilder(int capacity) {
if (COMPACT_STRINGS) {
value = new byte[capacity];
coder = LATIN1;
} else {
value = StringUTF16.newBytesFor(capacity);
coder = UTF16;
}
}
public StringBuffer(int capacity) {
super(capacity);
}
如果构造函数传入的参数为 String 类型,则会开辟长度为 str.length() + 16 的 byte 数组,并通过 append 方法将字符串对象添加到 byte 数组中。
public StringBuffer(String str) {
super(str.length() + 16);
append(str);
}
类似地,传入参数为 CharSequence 类型时也做相同处理。
public StringBuffer(CharSequence seq) {
this(seq.length() + 16);
append(seq);
}
主要方法
为了实现线程安全,其实最简单也可能是最没效率的方法就是通过对某些方法进行同步,以此允许并发操作。所以 StringBuffer 和 StringBuilder 其实实现逻辑几乎都一样,并且抽象到 AbstractStringBuilder 抽象类中来实现,只是 StringBuffer 将一些必要的方法进行同步处理了。
StringBuffer 中大多数方法都只是加了 synchronized。
比如下面该方法加了同步来保证计数的准确性。此外还包含很多其他方法,比如 codePointCount 、 capacity 、 ensureCapacity 、 codePointAt 、 codePointBefore 、 charAt 、 getChars 、 setCharAt 、 substring 、 subSequence 、 indexOf 、 lastIndexOf 、 getBytes 。
@Override
public synchronized int length() {
return count;
}
@Override
public synchronized void setLength(int newLength) {
toStringCache = null;
super.setLength(newLength);
}
trimToSize方法
该方法用于将该 StringBuffer 对象的容量压缩到与字符串长度大小相等。重写了该方法,主要是添加了同步,保证了数组复制过程的准确性。
@Override
public synchronized void trimToSize() {
super.trimToSize();
}
public void trimToSize() {
int length = count << coder;
if (length < value.length) {
value = Arrays.copyOf(value, length);
}
}
append方法
有多个 append 方法,都只是传入的参数不同而已,同样是使用了 synchronized,另外它还会清理缓存 toStringCache,这是因为 append 后的字符串的值已经变了,所以需要重置缓存。重置缓存的方法还包括: appendCodePoint 、 delete 、 deleteCharAt 、 replace 、 insert 、 reverse 。
@Override
public synchronized StringBuffer append(String str) {
toStringCache = null;
super.append(str);
return this;
}
toString方法
使用同步操作,先判断缓存是否为空,如果为空则先根据编码(Latin1 或 UTF16)创建对应编码占位的 String 对象,然后创建新 String 对象并返回。
@Override
public synchronized String toString() {
if (toStringCache == null) {
return toStringCache =
isLatin1() ? StringLatin1.newString(value, 0, count)
: StringUTF16.newString(value, 0, count);
}
return new String(toStringCache);
}
writeObject方法
该方法是序列化方法,分别将 value、count、shared 字段的值写入。
private synchronized void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException {
java.io.ObjectOutputStream.PutField fields = s.putFields();
char[] val = new char[capacity()];
if (isLatin1()) {
StringLatin1.getChars(value, 0, count, val, 0);
} else {
StringUTF16.getChars(value, 0, count, val, 0);
}
fields.put("value", val);
fields.put("count", count);
fields.put("shared", false);
s.writeFields();
}
readObject方法
该方法是反序列方法,分别读取 value 和 count,并且初始化对象内的字节数组和编码标识。
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
java.io.ObjectInputStream.GetField fields = s.readFields();
char[] val = (char[])fields.get("value", null);
initBytes(val, 0, val.length);
count = fields.get("count", 0);
}
void initBytes(char[] value, int off, int len) {
if (String.COMPACT_STRINGS) {
this.value = StringUTF16.compress(value, off, len);
if (this.value != null) {
this.coder = LATIN1;
return;
}
}
this.coder = UTF16;
this.value = StringUTF16.toBytes(value, off, len);
}
-------------推荐阅读------------
我的2017文章汇总——机器学习篇
我的2017文章汇总——Java及中间件
我的2017文章汇总——深度学习篇
我的2017文章汇总——JDK源码篇
我的2017文章汇总——自然语言处理篇
我的2017文章汇总——Java并发篇
跟我交流,向我提问:

公众号的菜单已分为“读书总结”、“分布式”、“机器学习”、“深度学习”、“NLP”、“Java深度”、“Java并发核心”、“JDK源码”、“Tomcat内核”等,可能有一款适合你的胃口。
为什么写《Tomcat内核设计剖析》
欢迎关注:

正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

