2018年俄罗斯世界杯之Java数据爬虫(一)
好久没写文章了,总想写点什么东西,刚好最近俄罗斯世界杯开幕了,所以仔细想了想,写一写Java爬取俄罗斯世界杯的数据吧,有需要的可以依照此方法可以对世界杯的数据进行数据分析。我计划写几篇的文章来仔细的说下Java爬取俄罗斯世界杯的相关经验。本篇文章不涉及相关代码说明,后续将会涉及相关代码说明,目前这种数据的采集时比较简单的。
一、 数据来源
既然要爬虫,首先我们需要找到上哪里去找俄罗斯世界杯相关的数据,目前很多的门户网站都提供了相关的世界杯的数据展示页面,我们可以从一些新浪、网易等去爬取我们需要的数据,目前我选中了新浪体育中的页面,来爬取俄罗斯世界杯的数据。
二、 数据页面
1、首先登录新浪体育的世界杯的专题首页面(http://2018.sina.com.cn/),如下所示:

2、接下来我们主要从【积分】、【射手】、【数据】等页签,进行数据的抓取,其中各个界面的效果图如下:
【积分】地址: http://2018.sina.com.cn/scoreboard/page.shtml,界面效果图:

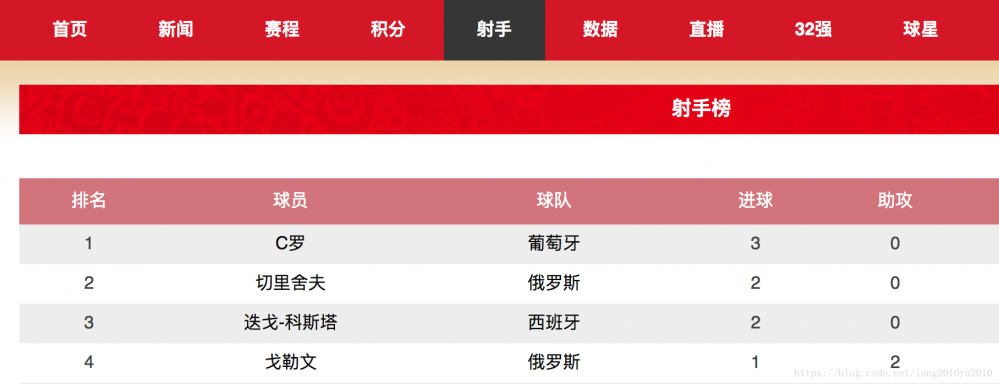
【射手】界面地址:http://2018.sina.com.cn/scorer/page.shtml,效果图如下:
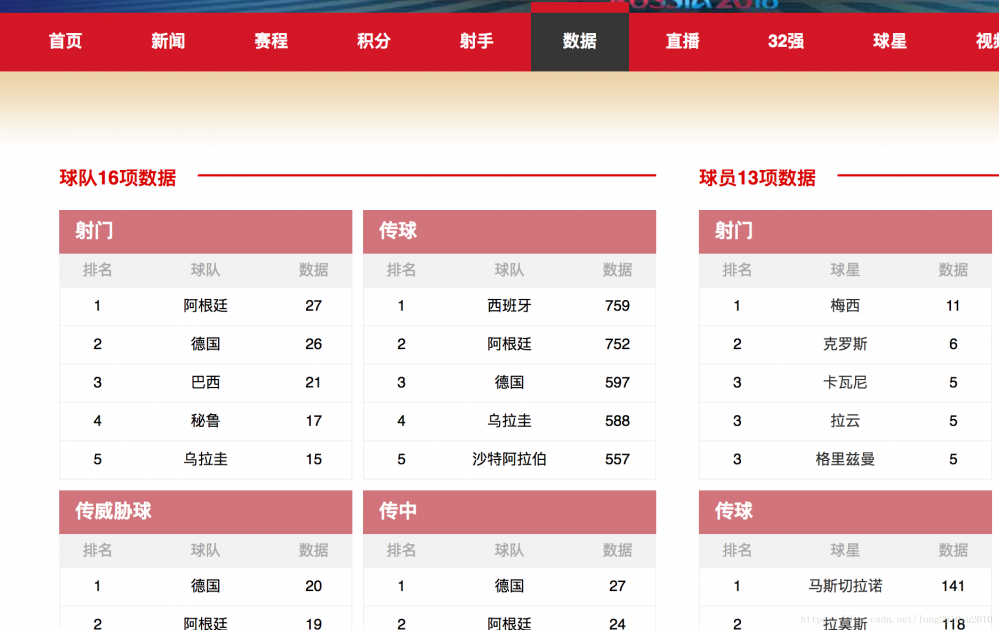
【数据】界面地址:http://2018.sina.com.cn/data/data.shtml,效果图如下:
这三个界面其实都是很不错的数据:
其中【积分】页面,可以知道俄罗斯世界杯32强的基本情况,比如分组、球队名、比赛场次、胜平负、积分等内容。
其中【射手】页面,可以知道俄罗斯世界杯进球的球员的基本信息,比如球员名、球队、进球、助攻等内容。
其中【数据】页面,可以知道俄罗斯世界球队与球员的基本信息,比如球队的射门次数、球队的传球次数,球员的射门次数,球员的助攻次数等内容。
三、数据发现
既然我们已经确定待采集数据的界面,下面我们需要分析一下和这个数据上的界面是怎么渲染出来,是服务器端渲染,还是客户端渲染。
这里我为什么要提到服务器端渲染和客户端渲染呢?
根据我的经验,一般网页的内容主要就是这两种渲染的方式:
如果新浪体育的俄罗斯世界杯的数据是服务器端渲染的,那么该网页的源代码中自然有我们需要的数据;
如果新浪体育的俄罗斯世界杯的数据是客户端渲染的,那么该网页的源代码中是看不见我们的数据的,只能通过浏览器调试工具查询实际生成的DOM树的信息。
那么对于新浪体育的2018年世界杯专题的【积分】页面是如何渲染的呢?
首页我们可以查看积分页面的源代码,可以看到相关的数据区域在源代码上是没有值的,所以这个积分页面中的数据是客户端JS渲染的,如下所示:
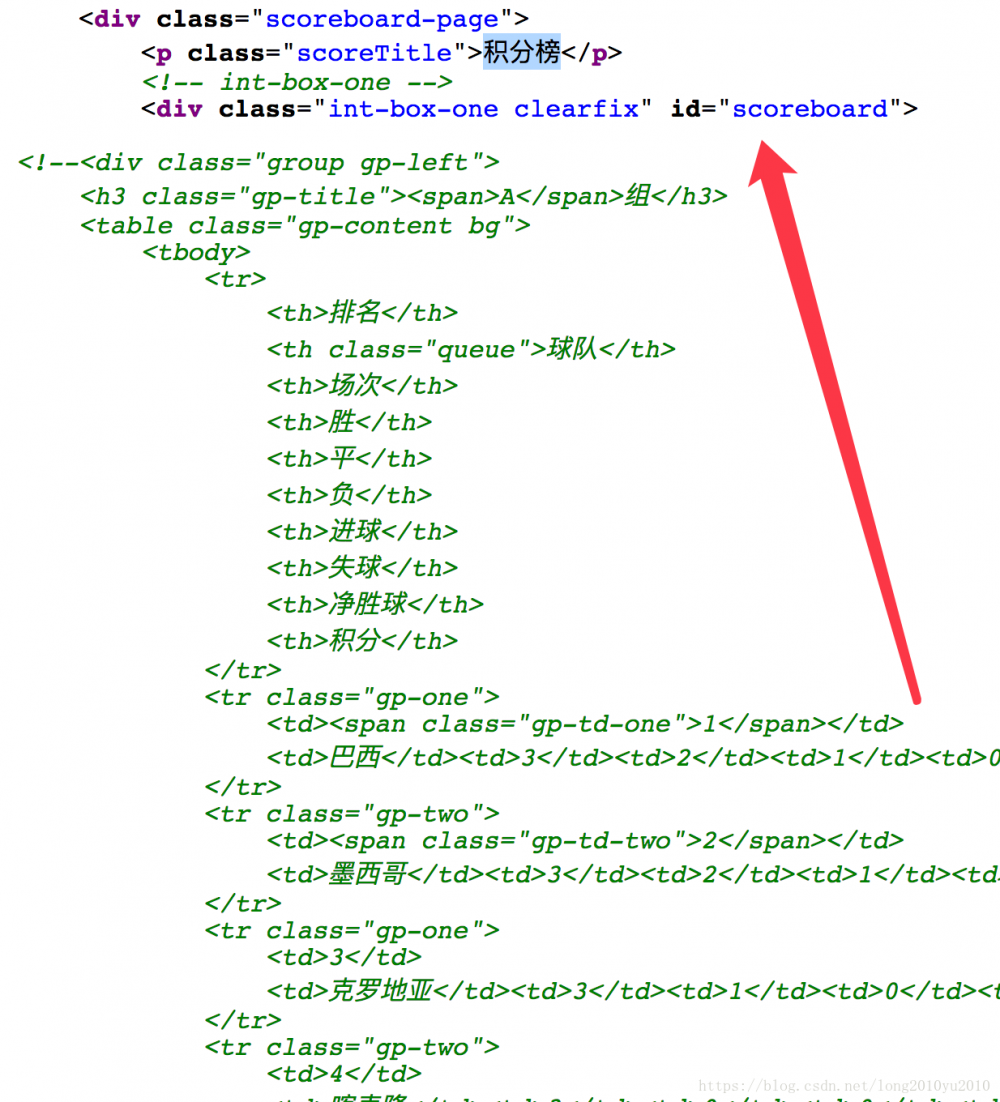
从图中可以看到这个ID名为scoreboard的区域是没有实际的数据的,只有相关的测试数据,所以我们可以确定该页面是通过JS技术进行客户端渲染, 既然知道了是客户端的渲染,那么我们如何找到实际数据的内容呢?
通常可以从以下途径找到实际的数据:
1、 源代码中的数据,某些网页会在服务器端把相关的数据写入到JS对象中。
2、 发送AJAX异步请求
3、 发送请求,请求后台的JS文件或某些接口来返回数据。
4、 查看调试工具的控制台,看是否有日志输出。
对于这个【积分】的页面,我们打开火狐浏览器的调试工具会发现,输出了一个JSON对象,而这个JSON对象的是从scoreboardPage.js中的57 行日志输出的,如下所示:
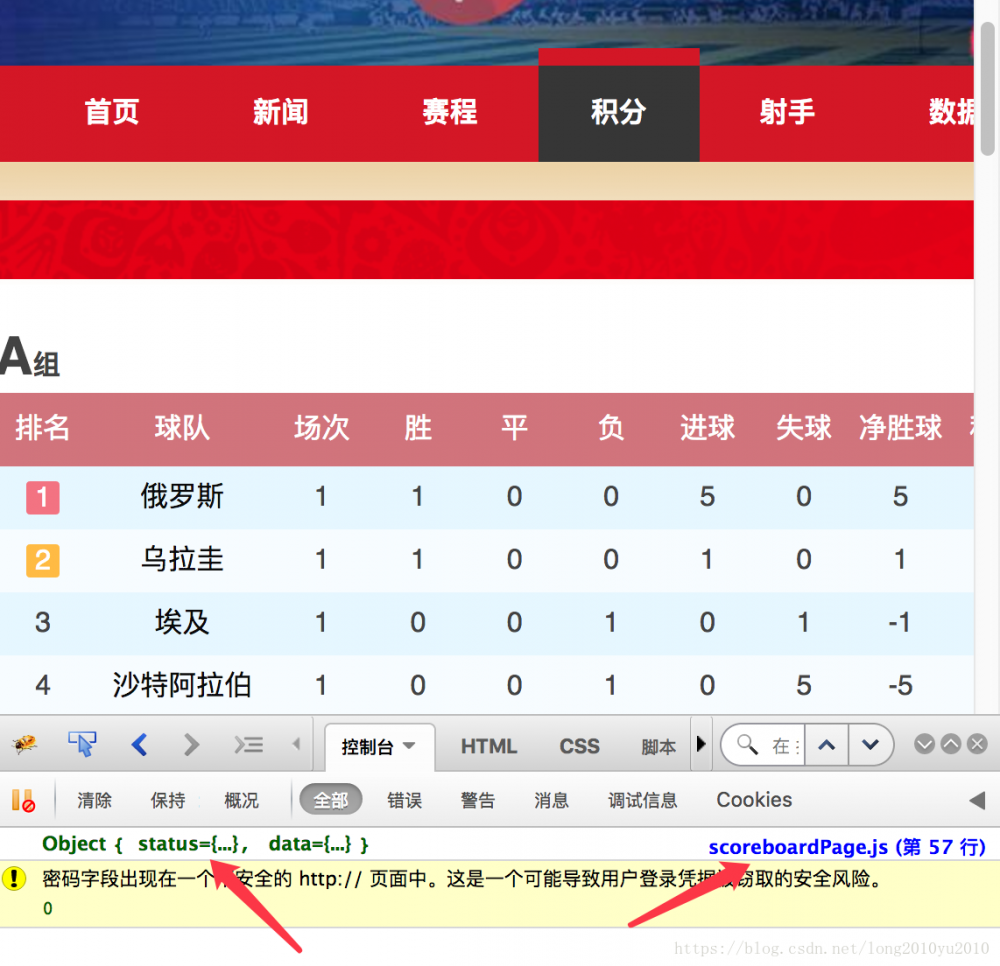
展开这个对象后,我们发现这个数据结构就是这个积分页面的需要的数据,如下图所示:
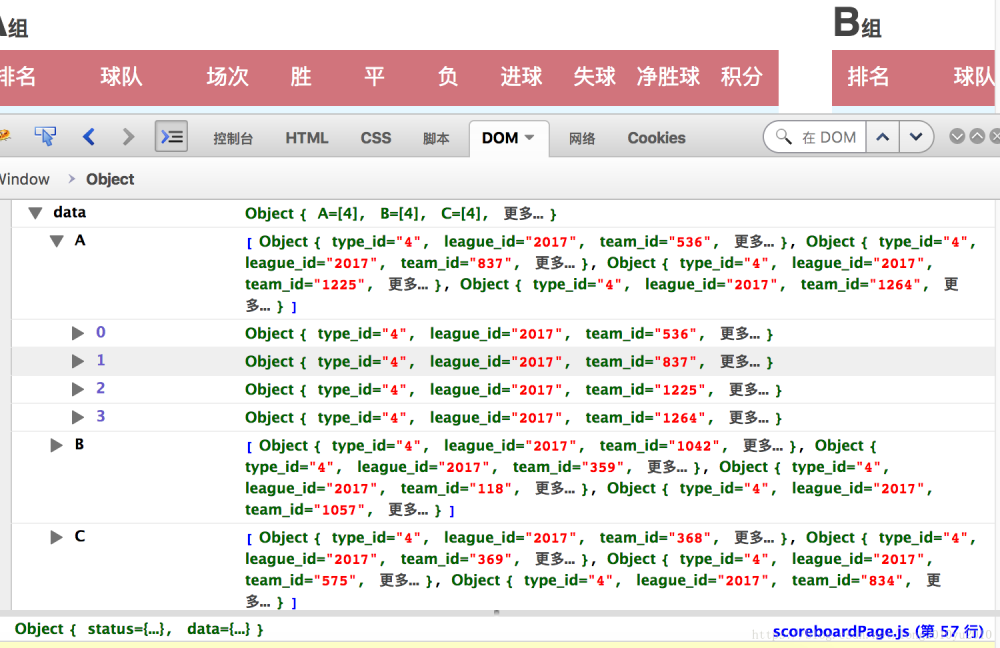
同时查看scoreboardPage.js中的57行的相关代码,如下图所示:
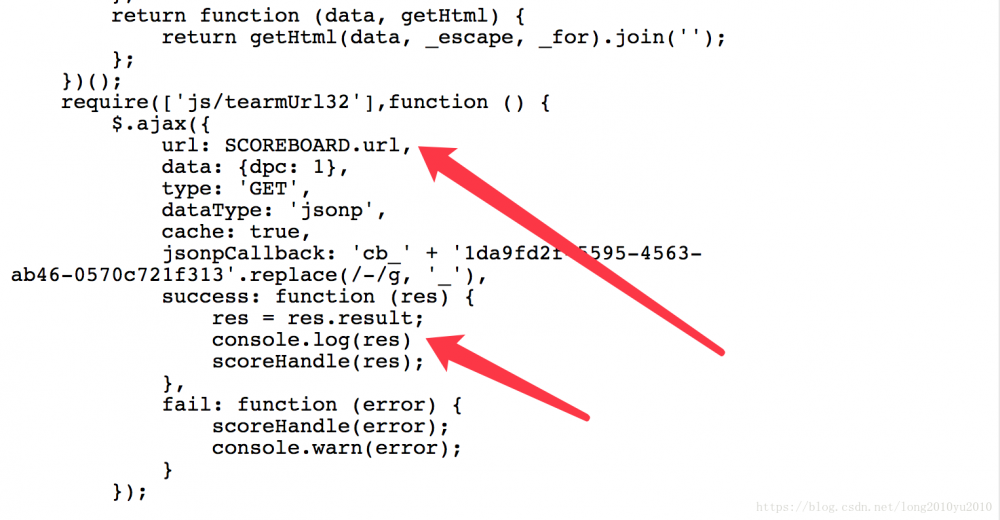
经过代码分析后,我们可以看见他调用一个ajax的方法,请求了一个地址,然后将返回的数据传给scoreHandle方法,进行页面的渲染,到这里详细有很多应该知道真么找到这个【积分】页面的数据了,通过浏览器调试工具监控发现,这个请求URL地址如下:
http://api.sports.sina.com.cn/?p=sports&s=sport_client&a=index&_sport_t_=football&_sport_s_=opta&_sport_a_=teamOrder&type=108&use_type=group&callback=cb_1da9fd2f_5595_4563_ab46_0570c721f313&dpc=1
请求了这个地址以后,就会返回【积分】页面的JSON结构数据,也就是我们需要的数据,同理,【射手】、【数据】页面也可以通过此种方式进行页面的获取。
如果想爬去这个网页的数据,后续我们将会用到HttpClient、Jsoup、HtmlUnit等Java包,来解析我们我们需要的数据。
目前这几个页面都为客户端渲染,在进行代码编码写时,可以用HttpClient去请求该接口地址,解析返回的JSON内容,这个是很好做的,如果不解析这个接口,我们可以通过Jsoup去解析网页的源代码,进行数据的爬取,不过前提要求是服务器端渲染的网页,对于这种客户端JS动态渲染的网页不太好进行爬虫获取,最近看到可以使用HtmlUnit进行爬取这种动态网页,最近也在研究这个东西。
目前我梳理了可以实现的两种方式进行新浪体育世界杯专题页面的相关数据的爬虫获取:
方式一:使用HttpClient请求数据的JSON格式接口进行获取。
方式二:通过使用浏览器调试工具,保存实际生成的HTML页面代码,使用Jsoup进行获取。
本篇文章就结束,后续将会进行进一步的说明。
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

