2018年俄罗斯世界杯之Java数据爬虫(二)
最近比较忙,所以第二篇文章稍微较晚了些,本篇文章将会对新浪体育的世界杯专题界面中的【积分】页面中的数据进行分析与数据采集,希望通过这个过程,可以帮助到需要的朋友们。
一、内容抓取
看过上一篇博客的朋友们都知道,我们通过对积分界面的相关分析,找到了请求积分页面页面数据的接口,通过该接口我们可以进行相关数据的获取,本文将从积分页面入手,进行相关的数据分析与解析。
以下为经过分析后,获取的积分页面的数据请求地址:
http://api.sports.sina.com.cn/?p=sports&s=sport_client&a=index&_sport_t_=football&_sport_s_=opta&_sport_a_=teamOrder&type=108&use_type=group&callback=cb_1da9fd2f_5595_4563_ab46_0570c721f313&dpc=1
从中可以看到请求的地址为:
http://api.sports.sina.com.cn/
请求的参数列表如下:
| 参数名称 | 参数值 | 参数含义 |
| _sport_a_ | teamOrder | 请求的功能,即Action |
| _sport_s_ | opta | 未知 |
| _sport_t_ | football | 足球 |
| a | index | 未知 |
| callback | cb_1da9fd2f_5595_4563_ab46_0570c721f313 | json |
| dpc | 1 | 未知 |
| p | sports | 用于API请求 |
| s | sport_client | 用于API请求 |
| type | 108 | 未知 |
| use_type | group | 用途,值为group时分组返回 |
有没有人会说,这个参数的含义是我是怎么知道的。
一般调用接口时,最简单的办法就是在测试接口时,不传递某个参数,然后观察返回的结果,在结合访问其他接口,观察几次,很容易发现某些参数的真实含义了。
例如:
不传递这个_sport_a参数,返回的数据提示信息为:
{"result":{"status":{"code":11,"msg":"sport action is invalid"},"data":[]}}
不传递这个_sport_s参数,返回的数据提示信息为:
{"result":{"status":{"code":11,"msg":"sport source is invalid"},"data":[]}}
传递use_type这个参数并且值为group后,返回的数据格式是这样的:
{
"result":{
"status":{
"code":0,"msg":""
},
"data":{
"A":[
{"type_id":"4","league_id":"2017"},
{"type_id":"4","league_id":"2017"}
]
}
}
当不传递use_type这个参数以后,返回结构是这样的:
{
"result":{
"status":{
"code":0,"msg":""
},
"data":[
{"type_id":"4","league_id":"2017"},
{"type_id":"4","league_id":"2017"}
]
}
我们知道当发送一个请求时,服务器返回来的基本都是字符串格式的数据,那么我们用HttpClient去请求这个地址后,返回来也是字符串结构,在未更改任何请求参数的情况下,我们可以看到服务器返回来的内容加上了一层包装,这对于我们的解析需要多处理一步,如下图所示:
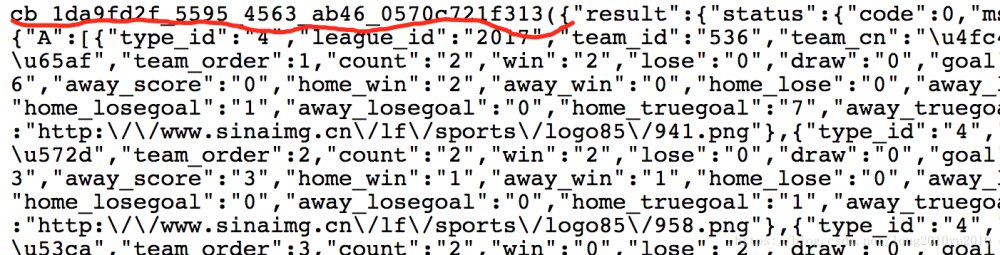
尝试去掉callback 这个请求参数以后,发现时正常的JSON格式字符串的信息,如下所示:

以上是我们简单分析的一个过程。接下来写个程序采集下来,这个程序时去掉callback这个参数。程序用HttpClient发送请求,使用了一个已经封装好的工具类,主要代码如下所示:
public class TestFootball {
public static final String CSS_URL = "http://n2.sinaimg.cn/products/worldcup2018/latest/css/base.css";
public static final String PAGE_URL = "http://2018.sina.com.cn/scoreboard/page.shtml";
public static final String PARAMS = "p=sports&s=sport_client&a=index&_sport_t_=football&_sport_s_=opta&_sport_a_=teamOrder&type=108&dpc=1";
public static final String URL = "http://api.sports.sina.com.cn/?" + PARAMS;
public static Map<String,String> NAME_MAP = new HashMap<String,String>();
static {
NAME_MAP.put("team_id", "球队ID");
NAME_MAP.put("team_cn", "球队名称");
NAME_MAP.put("team_order", "球队排名");
NAME_MAP.put("count", "场次");
NAME_MAP.put("win", "胜");
NAME_MAP.put("lose", "负");
NAME_MAP.put("draw", "平");
NAME_MAP.put("goal", "进球");
NAME_MAP.put("losegoal", "失球");
NAME_MAP.put("truegoal", "净胜球");
NAME_MAP.put("score", "积分");
NAME_MAP.put("group", "小组");
NAME_MAP.put("sl_id", "唯一标识ID");
NAME_MAP.put("logo", "国家图片");
}
public static void main(String[] args) throws IOException {
/*BasicHeader[] reqHeaders = new BasicHeader[2];
reqHeaders[0] = new BasicHeader("If-Modified-Since", " Wed, 06 Jun 2018 04:28:24 GMT");
reqHeaders[1] = new BasicHeader("Accept-Encoding", "gzip, deflate");*/
List<Map<String,Object>> rList = new ArrayList<Map<String,Object>>();
CloseableHttpResponse response = HttpClientRequestUtil.getHttpResponse(URL, "get", null, null);
if(response == null){
System.out.println("服务器无响应");
return;
}
int statusCode = response.getStatusLine().getStatusCode();
if(statusCode == 200){
//打印网页的响应头的信息
Header[] resHeaders = response.getAllHeaders();
if(resHeaders != null){
for(Header header : resHeaders){
System.out.println(header.getName() + " : " + header.getValue());
}
}
HttpEntity entity = response.getEntity();
String returnResult = null;
if (entity != null) {
returnResult = EntityUtils.toString(entity);
} else {
return;
}
//根据返回结果进行处理
JSONObject result = JSONObject.parseObject(returnResult);
JSONObject rObj = result.getJSONObject("result");
JSONObject statusObj = rObj.getJSONObject("status");
int code = statusObj.getIntValue("code");
if( code == 0){
//请求数据格式正确
JSONArray datas = rObj.getJSONArray("data");
Set<String> mapKeySet = NAME_MAP.keySet();
if(datas != null && datas.size() > 0){
for(int i = 0;i < datas.size();i++){
JSONObject jsonObject = datas.getJSONObject(i);
Map<String,Object> map = new HashMap<String,Object>();
for(String key : mapKeySet){
map.put(NAME_MAP.get(key), jsonObject.get(key));
}
rList.add(map);
}
}
}
}else if(statusCode == 304){
//网页未修改
System.out.println("网页未修改!");
}
System.out.println(JSON.toJSONString(rList));
}
}
程序最后的输出结果如下:
[
{"进球":"3","球队排名":"1","净胜球":"2","唯一标识ID":"952","失球":"1","球队ID":"614","小组":"E","球队名称":"巴西","场次":"2","胜":"1","国家图片":"http://www.sinaimg.cn/lf/sports/logo85/952.png","负":"0","积分":"4","平":"1"},
{"进球":"4","球队排名":"1","净胜球":"1","唯一标识ID":"944","失球":"3","球队ID":"118","小组":"B","球队名称":"西班牙","场次":"2","胜":"1","国家图片":"http://www.sinaimg.cn/lf/sports/logo85/944.png","负":"0","积分":"4","平":"1"}
]
这样就可以把相关数据存储到数据库中了。由于我在请求时去掉了use_type=group这个参数,返回的data数据的顺序不是正常的数据顺序,如需排序需要在代码里面进行手动排序。
二、304状态码说明
有没有人发现我为什么要判断HTTP的状态吗等于304呢?其实,爬虫时或进行数据抽取时的一个典型的需求了,经常为了提高采集的效率,往往考虑增量去采集网页。而一般的增量采集的条件,则是根据某个时间点,去查询这个时间点之后产生的数据。
当做数据库的增量采集时,通常是在SQL中传入某一个时间点,而这个时间点从上一次的采集时间获取。
当做FTP文件数据的增量采集时,通常是根据文件在FTP服务器上的修改时间来判断是否是新增的文件。
那么对于网页来说,我们可以在下载网页时,记录网页的下载的某个时间点,增量采集这个网页时,把时间点传入到某个地方。
那么怎么知道网页是否进行修改了呢?
首先我们请求一下这个新浪体育的地址,并获取响应头的信息:
http://2018.sina.com.cn/news/
响应头信息如下:
Server : nginx Date : Sat, 23 Jun 2018 14:48:31 GMT Content-Type : text/html Connection : keep-alive Last-Modified : Sat, 23 Jun 2018 14:45:58 GMT Vary : Accept-Encoding X-Powered-By : shci_v1.03 Expires : Sat, 23 Jun 2018 14:48:57 GMT Cache-Control : max-age=60 Age : 34 Via : http/1.1 cnc.beixian.ha2ts4.214 (ApacheTrafficServer/6.2.1 [cHs f ]) X-Cache : HIT.214 X-Via-CDN : f=Edge,s=cnc.beixian.ha2ts4.214,c=123.126.157.206 X-Via-Edge : 1529765311820ff09757bde9d7e7b101d14b9
从响应的结果中,我们可以看见【Last Modified】响应头,这个响应头代表了网页的修改时间,【Date】返回的是Web服务器的当前时间。
304这个请求我们在用浏览器调试工具去观测某个请求是,经常会发现他会出现304状态码的提示,如下图所示:
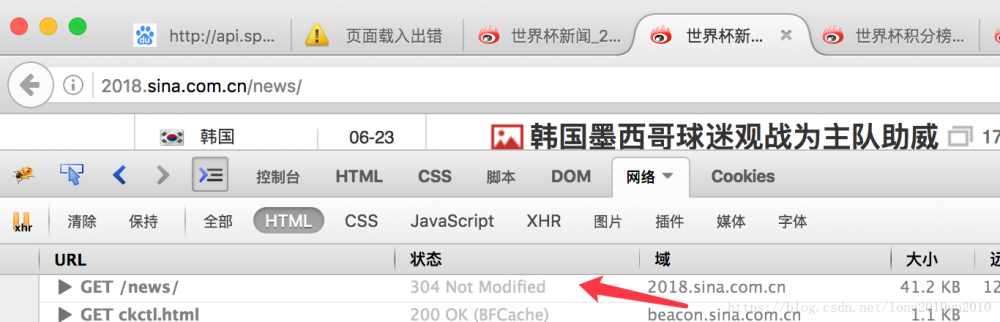
那么,他为什么会变成304状态呢?通过观察请求后我们会发现,当进行第二次请求时,浏览器会自动发送一个请求头【If-Modified-Since】,其中包含的时间是先前服务器发过来的【Last-Modified】最后修改的时间戳,这样让Web服务器端进行验证,通过这个时间戳判断爬虫上次抓过的页面是否有更新。如果有修改,则返回HTTP状态码200和新的内容。如果没有变化,则只返回HTTP状态码304,告诉爬虫没有变化,这样可以大大减少在网络上传输的数据,避免无所谓活多余的请求信息,同时也可以减轻被抓取服务器的负担。
例如我们可以用之前的代码去请求这个地址
String PAGE_URL = "http://2018.sina.com.cn/news/";
CloseableHttpResponse response = HttpClientRequestUtil.getHttpResponse(PAGE_URL, "get", null, null);
在未加【If-Modified-Since】这个请求头时,他的状态码是200。然后我们再请求时,如果未加上本次响应头里面的【Last-Modified】的值时,他还是200,若加上了【If-Modified-Since】这个请求头,且该请求头的值为上一次的【Last-Modified】的值时,他的状态就变成304了。
通过对304的判断,我们可以知道请求的网页是否做了修改,进而进行增量的数据的解析工作。后续我们可能去解析一下新浪体育世界杯新闻页面的数据。
我觉得爬虫是一项非常不错的学习内容,可以从中了解到HTTP协议的相关知识、各种JSON数据结构解析等。
本来计划用Jsoup去解析HTML格式获取世界杯数据的,不过目前这几个界面的数据都是发送JSON请求来获取数据的,后续会找一找相关的页面的数据。
总是觉得,这篇文章写的太简单了些。
正文到此结束
- 本文标签: 希望 SDN zip key src IBM Action UI ArrayList HTML FTP服务 参数 博客 CDN HTTP协议 API java json client tab 下载 map HashMap 时间 Nginx 分页 http js IO CSS logo parse ftp 测试 文章 sql Keep-Alive 需求 web list core https 图片 数据 解析 Connection 协议 朋友们 数据库 id 代码 apache value entity ip cache 调试 jsoup 服务器 final 排名
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

