Spring的自定义Schema是如何解析生效的
随着 Spring Boot 的日渐流行,应用里的大部分配置都被隐藏了起来,我们仅需要关心真正的业务内容, Controller, Service, Repository,拿起键盘就是一通业务代码的Coding,具体的 Component Scan,View,PlaceHolder ... 都可以抛在脑后。但其实这种零配置在 Java 应用开发中,还真不太久。 「由奢入俭难」,不少开发者都经历过 Spring XML 配置的冗长,再回到这种配置确实不好受。
但有些时候,由于配置的内容在 Spring Boot这种零配置中并不能很好的实现,就需要我们仍使用 XML 的配置形式,然后再 ImportSource进来。或者一些项目受环境等影响,未使用Boot进行开发,此时也需要对配置有一定的了解。
那这次让我们往回看一些,看看在 XML 配置中,一些自定义的 Schema 内容,是如何融合到 Spring 中进行配置的。例如:
Spring data es

dubbo
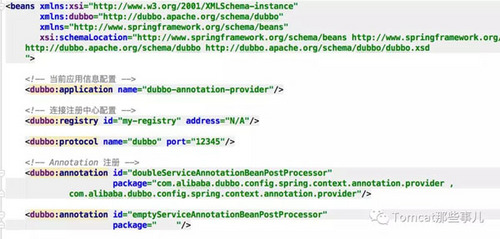
还有许多这样的例子,我们不再一一罗列。但通过上述两个图,我们发现一个共同的特点:
- 都是通过schemaLocation将对应的schema引入
- 在对应的beans元素中增加更具体的自定义配置
那这些自定义的配置,是在什么时候工作的呢?如何校验是否配置正确?
我们来看 Spring 中包含一个名为 spring.handlers的文件,所有的自定义扩展,都是通过这个文件生效的。spring 官方的aop, tx 也都是这个原理。
这个文件在哪呢?
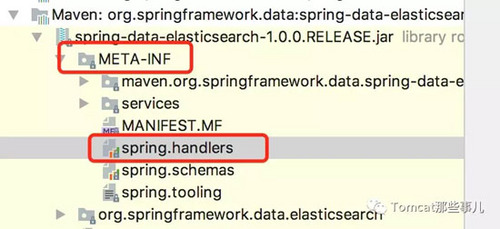
如上图所示,是META-INF/spring.handlers。文件内容也超级简单:
http/://www.springframework.org/schema/data/elasticsearch=org.springframework.data.elasticsearch.config.ElasticsearchNamespaceHandler
前面是各个schema前缀,后面是schema 对应的解析类。这个spring.handlers文件是什么时候加载的呢?
这个也是发生在解析自定义配置文件过程中,有一个resolve的过程,此时会将当前classLoader对应的所有包含spring.handlers文件加载过来。
我们再来看这个解析类,内容如下:
public class ElasticsearchNamespaceHandler extends NamespaceHandlerSupport {
public ElasticsearchNamespaceHandler() {
}
public void init() {
RepositoryConfigurationExtension extension = new ElasticsearchRepositoryConfigExtension();
RepositoryBeanDefinitionParser parser = new RepositoryBeanDefinitionParser(extension);
this.registerBeanDefinitionParser("repositories", parser);
this.registerBeanDefinitionParser("node-client", new NodeClientBeanDefinitionParser());
this.registerBeanDefinitionParser("transport-client", new TransportClientBeanDefinitionParser());
}
}
首先是继承自NamesapceHandlerSupport
然后在重写的init方法中注册了一系列的parser,每个parser对应一个字符串,就是我们在xml配置文件是使用的自定义内容,比如上面的es的配置
<elasticsearch:transport-client id="client" cluster-nodes="192.168.73.186:9300" cluster
这里的配置最终就会通过 TransportClientBeanDefinitionParser 来进行解析
而上面提到的各个parser,在init方法中,保存在了一个Map中
private final Map<String, BeanDefinitionParser> parsers = new HashMap();
所谓注册parser,就是在向这个parsers的map进行put操作。
那回过头来,在Spring中,最核心的内容是什么呢? 是Bean。而实际上我们配置到XML里的这些内容,最终也会生在一个对应的Bean,所有的配置,只是为了生成Bean,这些自定义的配置,都称之为BeanDefinition。
所以,Spring 在解析配置文件是,会有如下的判断,是否是defaultNamespace,不是的话就走customElementParse
protected void parseBeanDefinitions(Element root, BeanDefinitionParserDelegate delegate) {
if(delegate.isDefaultNamespace(root)) {
NodeList nl = root.getChildNodes();
for(int i = 0; i < nl.getLength(); ++i) {
Node node = nl.item(i);
if(node instanceof Element) {
Element ele = (Element)node;
if(delegate.isDefaultNamespace(ele)) {
this.parseDefaultElement(ele, delegate);
} else {
delegate.parseCustomElement(ele);
}
}
}
} else {
delegate.parseCustomElement(root);
}
}
而是不是defaultNameSpace的判断更直接:namespace的uri有没有内容,或者是不是spring 的beans的声明
public boolean isDefaultNamespace(String namespaceUri) {
return !StringUtils.hasLength(namespaceUri) || "http://www.springframework.org/schema/beans".equals(namespaceUri);
}
所以请求都走到了parseCustomElement里,这里开始进行配置的解析, parse的时候,通过uriResolver查到对应的Handler
public BeanDefinition parseCustomElement(Element ele, BeanDefinition containingBd) {
String namespaceUri = this.getNamespaceURI(ele);
NamespaceHandler handler = this.readerContext.getNamespaceHandlerResolver().resolve(namespaceUri);
if(handler == null) {
this.error("Unable to locate Spring NamespaceHandler for XML schema namespace [" + namespaceUri + "]", ele);
return null;
} else {
return handler.parse(ele, new ParserContext(this.readerContext, this, containingBd));
}
}
那此时返回的仅仅是spring.handlers里配置的Handler,而每个Handler又注册了不少的parse,还得需要一个获取parser的过程
public BeanDefinition parse(Element element, ParserContext parserContext) {
return this.findParserForElement(element, parserContext).parse(element, parserContext);
}
private BeanDefinitionParser findParserForElement(Element element, ParserContext parserContext) {
String localName = parserContext.getDelegate().getLocalName(element);
BeanDefinitionParser parser = (BeanDefinitionParser)this.parsers.get(localName);
if(parser == null) {
parserContext.getReaderContext().fatal("Cannot locate BeanDefinitionParser for element [" + localName + "]", element);
}
return parser;
}
这个获取的过程,就是通过传入的string,在我们开始声明的Map里 get对应的parser,再使用它进行配置的解析啦。
有了parser,后面就是生成BeanDefinition的过程。
我们看,这些parser,都是继承自AbstraceBeanDefinitionParser,或者实现了BeanDefinitionParser 的接口,统一解析的入口处,是接口的parse方法。
public class TransportClientBeanDefinitionParser extends AbstractBeanDefinitionParser {
public TransportClientBeanDefinitionParser() {
}
protected AbstractBeanDefinition parseInternal(Element element, ParserContext parserContext) {
BeanDefinitionBuilder builder = BeanDefinitionBuilder.rootBeanDefinition(TransportClientFactoryBean.class);
this.setConfigurations(element, builder);
return this.getSourcedBeanDefinition(builder, element, parserContext);
}
}
在重写的parseInternal方法中,返回解析配置后对应的BeanDefinition。这里也是各个框架自由抽象的地方。比如有些框架是简单直接一个类,而有些在此处会应用一些类似策略、装饰器等设计模式,提供更多的灵活性。
具体获取到BeanDefinition之后,放到整个Context中如何生成 Spring Bean的内容,以后我们再做分析。
【本文为51CTO专栏作者“侯树成”的原创稿件,转载请通过作者微信公众号『Tomcat那些事儿』获取授权】
戳这里,看该作者更多好文
正文到此结束
- 本文标签: 开发 ACE spring Spring Boot find CTO build Service node UI list strace id CEO schema BeanDefinition ssl 配置 equals XML http AOP https 设计模式 dubbo Transport root map HashMap parse src IO tomcat 代码 final 微信公众号 java Elasticsearch cat 解析 client bean db 开发者
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

