Apache Flink 1.6 Documentation: Distributed Runtime Environment
分布式运行时环境
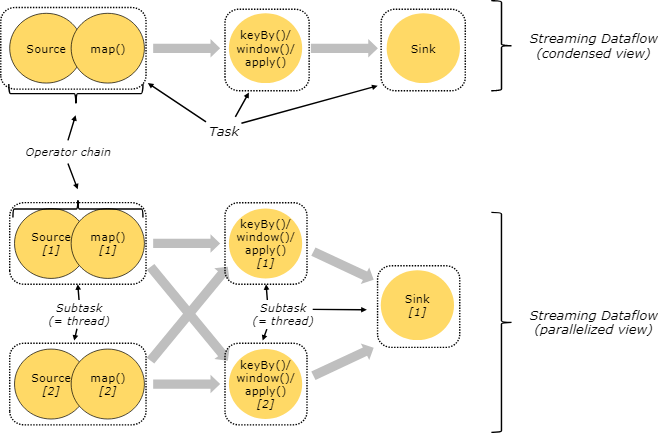
Tasks and Operator Chains 任务和操作链
Job Managers, Task Managers, Clients 作业管理器,任务管理器,客户端
Task Slots and Resources 任务执行槽和资源
State Backends 后端状态
Savepoints 保存点
Tasks and Operator Chains 任务和操作链
对分布式执行操作,Flink把操作子任务链起来放到任务中。每个任务由一个线程来执行。把操作链起来放入任务中是有助于优化的:它可以减少线程间交互和缓存的开销,减少延迟的同时提升整体的吞吐量。在链操作文档中有纤细的介绍 chaining docs ,以及如何配置链的操作方式。
下图中展示的数据流例子就是有五个子任务的一个执行,所以有5个并行的线程。
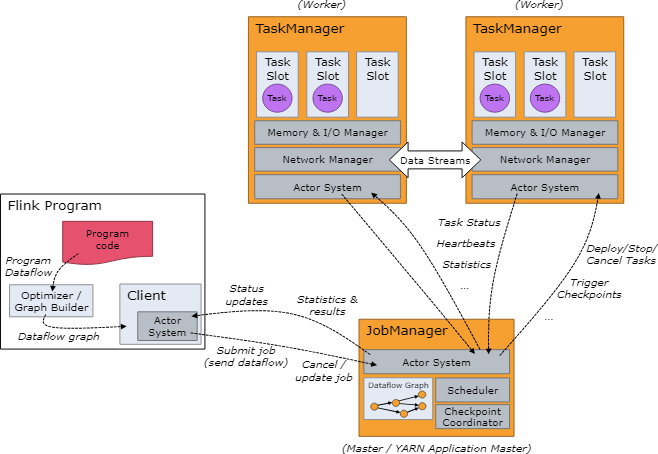
Job Managers, Task Managers, Clients 作业管理器,任务管理器和客户端
Flink的运行时环境包含两种类型的处理
- 作业管理(也叫做主节点)协调分布式执行,比如他调度任务,协调检查点,协调故障恢复。
- 一般至少有一个作业管理器,高可用配置会有多个作业管理器,其中一个是主服务,其它的都是备用服务。
- 任务管理器(也叫做工作者)执行数据流的任务(或者更具体的说是子任务),任务管理器也缓存和交换数据流。
- 运行时至少要有一个任务管理器。
启动作业管理器和任务管理器有多种方式:直接在机器上启动独立集群方式 standalone cluster , 在容器中启动,或者用像 YARN 或者 Mesos . 这样的资源管理框架启动。任务执行器主动连接作业管理器,并告知他们是否可用,再接受任务分派。
客户端不是执行程序和运行环境的一部分,但是它要来准备和向作业管理器发送数据流。在这之后,客户端可用断开连接或者保持连接来接收处理过程的信息。客户端可以作为触发执行的Java/Scala程序的一部分,也可以用命令行来执行,例如:./bin/flink run …。
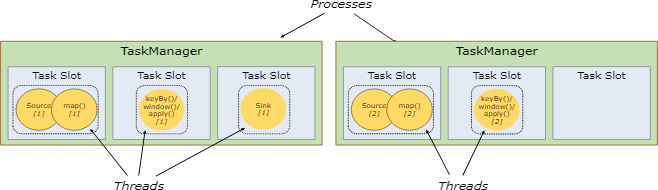
Task Slots and Resources 任务槽和资源
每个工作节点(任务执行器)是一个JVM的处理器,在单独的线的程可以执行一个或者多个子任务。为了控制一个工作节点可以接受的任务数量,工作节点提供了任务槽的机制(至少一个任务槽)。
在任务管理器中每个任务槽表示了一组固定的资源。例如:一个任务管理器有3个执行槽,那么就会把它管理内存的1/3分配给每个执行槽。用槽来隔离资源是为了让子任务执行时不用和其它作业的子任务竞争任务管理器管理的内存,而是给每个执行子任务预留了一定梳理的内存。提到的一点是这里没有CPU隔离。目前执行槽仅仅只为任务对内存进行隔离。
通过调整执行槽的个数,用户可以定义子任务之间是如何隔离的。每个作业管理器只有一个执行槽意味着每个任务组都是运行在隔离的JVM中(例如:可以在隔离的容器中启动)。作业管理器有多个执行槽意味着多个子任务共享了同一个JVM。任在同一个JVM中的任务共享了TCP链接(通过多路复用技术)和心跳消息。他们也可以共享数据集和数据结构,以此来减少每个任务的消耗。
默认情况下,Flink允许子任务共享执行槽,甚至不同任务的子任务之间都可以共享,只要他们是属于同一个作业的 。结果是一个执行槽可能有作业的两个全部数据流管道。允许执行槽共享有两个好处。
- 一个Flink集群需要和一个作业中的最高并行度一样多的任务执行槽。不用去计算一个程序总共有多少任务(变化的并行度)
- 更容易做到资源利用优化。没有执行槽共享,非密集子任务如source/map()会和资源密集型窗口子任务会阻塞一样多的资源。有了执行槽,在我们的例子中把基本并行度从2提升到6,可以充分利用槽的资源,同时确保繁重的子任务会被公平的分布执行。
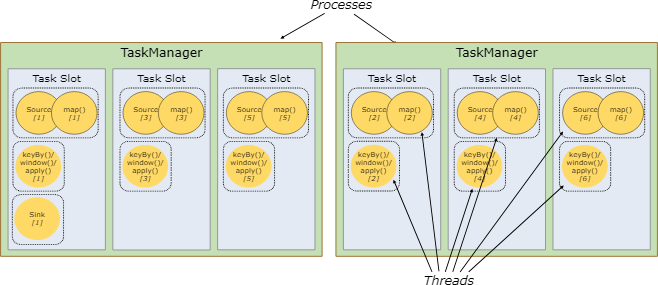
这个API也包含了一个资源组 resource group 的机制,可以防止不需要的执行槽共享。
一般来说,比较好的执行槽个数是和cpu核的个数一样的。有超线程的,每个执行槽会占2个或者多个硬件线程上下文。
State Backends 状态端
kv索引存储的的准确数据接口是依赖于所选择的状态端的 state backend 。一个状态端在内存中用hashmap来存储数据,另外一个状态端使用 RocksDB 作为kv存储。除了定义存储状态的数据接口,状态端也实现了获取kv状态时间点快照的逻辑,并且把这个快照存储作为检查点的一部分。
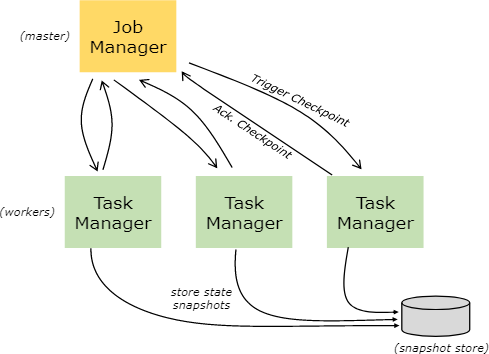
Savepoints 保存点
用数据流API写的程序可以从一个保存点恢复执行。保存点可以在不丢失状态的情况下更新你的程序和Flink集群。
保存点 Savepoints 是人工触发的检查点,保存点就是把程序的执行做个快照并且写入状态端。用唱过的检查点机制就可以做到这样的,在执行时,程序会被周期性的在工作节点上做快照,并且产生检查点。对恢复来说,只会用到最近的检查点,并且可以在新检测点做好之后就安全的丢弃早期的检查点。
保存点和周期性的检查点是类似,但是保存点是要被用户触发的并且在新检查点完成之后不会自动过期。保存点会在下面的情况下被创建:可以通过命令行或者用 REST API 消除一个作业的时候。
感觉有意思?来鼓励一下!

正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

