从源码的角度来谈一谈HashMap的内部实现原理
HashMap可以说是我们一个熟悉又陌生的Java中常用的存储数据的API。说他熟悉,是因为我们经常使用他,而说他陌生是因为我们大部分时间是只知道他的使用,而并不知道他内部的原理,但是在面试考察的时候又最喜欢去问这个原理。今天,我就来从源码的角度,谈谈对HashMap的理解。
HashMap概述
hashMap的底层其实是基于一个数组来进行数据的存储和取出。他继承于Map这个接口来实现,通过put和get方法来操作数据的存和取。具体对于hashMap的使用,这里不在具体举例说明,使用起来并不困难。不过在谈到HashMap的内部原理之前,我们需要了解一下几个名称的意思。
1. initialCapacity。 这个翻译为初始化容量。为hashMap的存储的初始化空间的大小,我们可以通过构造方法来指定其大小,也可以不指定采用 默认大小16 。这里需要说明一下,一般来说,容器的大小为2的幂次方。至于为什么会是2的幂次方,具体原因可以参考这篇文章。 为什么hashmap的初始化大小为2的幂次方
2. loadFactor。 加载因子。当hashmap的存储容量达到了一定上限之后,如果还需要进行数据的存储,则会利用加载因子对其进行扩容操作。一般而言,扩容大小为现在容量的0.75倍。举个例子,假设现在的hashMap的初始化大小为16,但是现在由于容量已满又要插入新的元素,所以先进行扩容操作,将容量扩充为16*0.72=12,也就是说扩大了12个容量。
3. threadshold: 扩容阀值。即扩容阀值 = HashMap总容量*加载因子。当hashMap的容量大于或者等于扩容阀值的时候就会去执行扩容。扩容的容量为当前HashMap总容量的两倍。
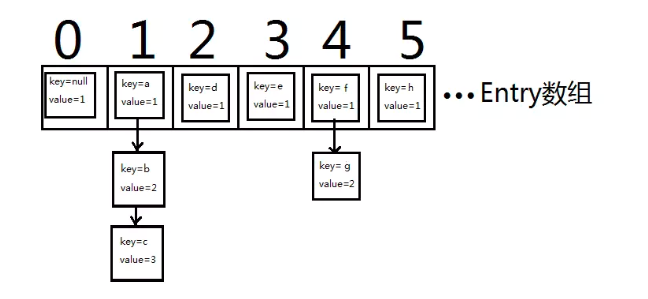
这里有一张网上找来的图,来说明hashMap内部存储原理。
源码解析
我们在使用hashMap的时候,一般来说都是用put和get方法,所以我们分析源码,就从这两个方法着手分析内部原理。
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
int hash = sun.misc.Hashing.singleWordWangJenkinsHash(key);
int i = indexFor(hash, table.length);
for (HashMapEntry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
复制代码
我们先来看看put方法。从代码可以看出,put方法主要做了这么几件事。
1.当我们在将key和value添加进入hashMap的时候,首先其会去判断table是否为空(EMPTY_TABLE)。这里需要说明下,这个table其实是一个数组,我们前面提到过,hashmap内部其实是一个数组来对数据进行存储,所以这个table其实可以写成table[ ]。当判断这个table数组为空的时候,他会去调用infalteTable()方法。而这个方法是做什么的呐,我们在跳进去看看。
private void inflateTable(int toSize) {
// Find a power of 2 >= toSize
int capacity = roundUpToPowerOf2(toSize);
// Android-changed: Replace usage of Math.min() here because this method is
// called from the <clinit> of runtime, at which point the native libraries
// needed by Float.* might not be loaded.
float thresholdFloat = capacity * loadFactor;
if (thresholdFloat > MAXIMUM_CAPACITY + 1) {
thresholdFloat = MAXIMUM_CAPACITY + 1;
}
threshold = (int) thresholdFloat;
table = new HashMapEntry[capacity];
}
复制代码
可以看到,其实这个inflateTable方法是在对hashmap进行初始化容量操作。其初始化容量为capacity * loadFacctor。也就是我们前面说过的 初始化容量 * 加载因子。
2.之后hashmap回去判断你储存的key是否为空, if(key == null) ,如果为空,则调用putForNullKey()方法来进行空key的操作。 这里可以说是hashMap与hashTable的一个最大不同的地方,hashMap允许key为空,他有相应的处理key为空的操作方法,但是hashTable却不能允许key为空,他没有相应的操作方法。
3.之后对key进行一次hashcode的计算并且计算其index。紧接着遍历整个table数组,判断是否有相同的key,如果发现有相同的key,则将key所携带的新的value替换掉之前旧的value,从而确保key的唯一性。之后进行addEntry方法中。
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? sun.misc.Hashing.singleWordWangJenkinsHash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
复制代码
我们进入到addEntry方法中查看。发现里面会先对数组需要存储的大小和阀值进行一次比较,如果发现要存储的已经超过了threshold阀值,那么就要调用resize对其进行扩容操作。 扩容的小大为2*table.length。之后从新计算hash,将结果存储到bucket桶里面。
那么resize()方法中又做了那些操作呐?
void resize(int newCapacity) {
HashMapEntry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
HashMapEntry[] newTable = new HashMapEntry[newCapacity];
transfer(newTable);
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
复制代码
我们可以看到resize里面仅仅只是初始化了一个新的更大的table数组,并且把老的数据从新添加进入了新的table里面去。
最后我们回到creatEntry方法中,查看发现如果在bucket桶内发生了hash的碰撞,则将其转化为链表的形式来进行存储,不过在Java1.8之后会将其变为红黑树的形式存储。在此将put方法源码分析完成。
我们再来看下get()方法。
public V get(Object key) {
if (key == null)
return getForNullKey();
Entry<K,V> entry = getEntry(key);
return null == entry ? null : entry.getValue();
}
复制代码
get方法一开始和put类似,都是先判断key是否为空,如果为空,则调用相应的getForNullKey方法去进行处理。不为空,调用getEntry去进行查找。我们再来看看getEntry里面又做了什么操作。
final Entry<K,V> getEntry(Object key) {
if (size == 0) {
return null;
}
int hash = (key == null) ? 0 : sun.misc.Hashing.singleWordWangJenkinsHash(key);
for (HashMapEntry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
复制代码
我们可以看到,里面也是先对key进行了一次hash操作,之后通过这个hash值来进行查找,如果发现hash值相等,则再通过比较key的值来进行查找,最终找到我们想要的e将其return返回,不然则返回为空,代表找不到此元素。
到此hashMap的整体原理讲解完毕。
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

