pinpoint 使用和相关源码解析
架构
对原生的pinpoint进行了一些二次开发,大致流程如下
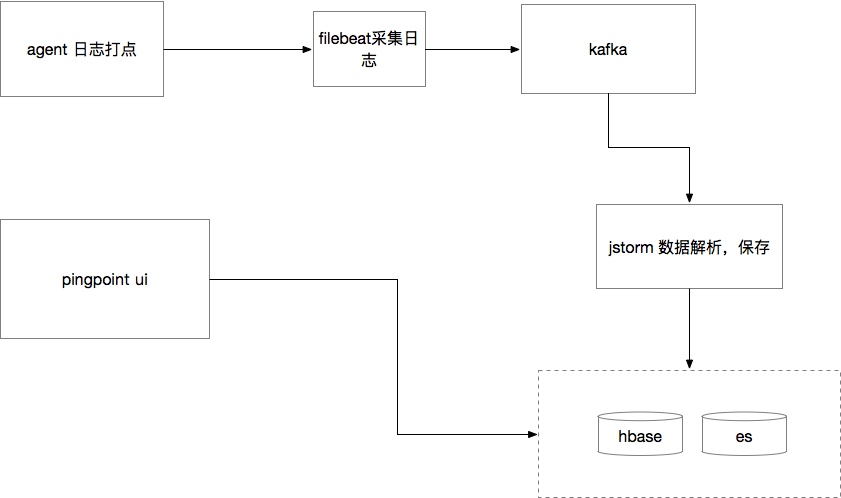
agent 收集数据
pinpoint默认数据collector是用的netty方式,agent是netty client端,进行抽样采集,发送数据到netty server端collector,collector在进行处理写入到hbase,包括agent本身的一些信息,内存,线程信息还有trace信息,但是这样性能就会损失很多,如果100%采集的话,会对应用和服务器都会造成很大负荷是,所有需要进行改造
我们将agent的netty通信方式改成了打日志的形式,在pinpoint spi获取对应实例的时候写死数据发送方式, 比如ApiMetaDataServiceProvider这个povider,判断config是storm的方式,直接使用了自定义的dataSender
@Override
public ApiMetaDataService get() {
final EnhancedDataSender enhancedDataSender;
if (PinpointConstants.AGENT_SENDER_TYPE_LOGGING.equals(profilerConfig.getAgentSenderType())) {
enhancedDataSender = new StormEnhanceLoggingDataSender();
} else {
enhancedDataSender = this.enhancedDataSenderProvider.get();
}
return new DefaultApiMetaDataService(agentId, agentStartTime, enhancedDataSender);
}
agent加载初始化
核心类入口是PinpointBootStrap的premain方法,这个是agent的标准
每个应用会配置pinpoint的一些启动参数,例如agentId和日志位置,之后在启动过程中会加载bootstrap-*.jar的这些jar包,还有通过日志目录进行截取,获取到插件的对应路径,加载插件的所有jar,并添加到bootstrap的classloader中,并通过spi的方式加载插件META-INF中配置的对应的类,加载其中的setup方法,将一些常量放到上下文中去,数据都加载到了TraceMetadataLoader中的annotationKeys和serviceTypeInfos这两个list集合中
java -Dpinpoint.log=/Users/walis/work/dwb/dapoint/logs -Dpinpoint.agentId=rider-fund-service -Dpinpoint.applicationName=rider-fund-service -javaagent:/Users/walis/work/dwb/dapoint/agent/target/pinpoint-agent-1.7.2-1.0.0-SNAPSHOT/pinpoint-bootstrap-1.7.2-1.0.0-SNAPSHOT.jar -jar rider-service.jar

对象实例化
pinpoint这货使用了很多spi和ioc方式,guice,spring ioc,类似serviceLoader的方式,有点多,很多重要的类都在spi中进行初始化了, 不去细看的话,很多类什么时候初始化还真不好找。
-
guice
pinpoint-profile模块中的 ApplicationContextModule 这个类中加载大多的核心的provider
``` configure(){
bindTraceComponent() bindDataTransferComponent() bindServiceComponent() bindAgentInformation() bindAgentStatComponent()
... } ```
- spring ioc
主要是collector模块中的applicationContext-collector.xml, 这边是collector接收到agent发送的数据进行处理一些核心类,包括hbase的存储 例如
核心类DefaultAgent启动
agent的start方法调用了DeafultApplicationContext,这个context类加载所有guice module生成,然后获取重要的核心类,比如AgentInfoSender和AgentStatMonitor,然后调用这两个类的start方法,启动agent数据打点
 * AgentInfoSender
* AgentInfoSender
AgentInfoSender内部会创建一个schedule,定时发送agent的信息,agent的信息主要是每个应用的id,ip,名称,端口,进程号,vm版本,agent版本, jvm信息的话都是从RuntimeMxBean获取的
 * AgentStatsMonitor
* AgentStatsMonitor
agentStatusMonitor收集各种agent相关的信息,比如cpu,jvm内存,trace响应时间等数据,AgentStatMetricCollector接口对应很多实现类,一部分调用的是metric包下面的包,像内存,cpu这些数据都是从RuntimeMBean中去拿的数据,

trace 过程
trace的过程主要涉及到traceId,span和spanEvent,接着就是spansender
traceId默认生成方式是agentId + agent启动时间 + 自增的id
一次调用是由很多span组成,最终形成一个id它们公用一个traceId
SpanRecorder 添加跟span相关联的spanEvent,包括服务的ip,参数信息,类型,返回值或者异常等等
trace的大致过程类似如下:
createTrace -> currentTraceObject -> traceBlockBegin -> traceBlockEnd -> close
close结束后,就会调用对应sender将span信息进行打点或者发送给对应的collector

字节码织入
plugin结构
-
ProfilerPlugin
每个插件需要实现ProfilerPlugin, TransformTemplateAware接口,提供设置servicetype,annotationKey
覆盖setup方法,设置需要处理的class,对特定拦截对象比如方法,添加拦截器,进行字节码植入,这个调用了ASMMethod的addScopedInterceptor方法,有兴趣的可以去看下,底层还是到asm的insertBefore方法
例如
``` for (InstrumentMethod m : target.getDeclaredMethods(MethodFilters.name("fromJson"))) {
m.addScopedInterceptor("com.navercorp.pinpoint.plugin.gson.interceptor.FromJsonInterceptor", GSON_SCOPE);
}
```
-
TraceMetadataProvider 每个插件需要实现TraceMetadataProvider,覆盖setup方法,设置serviceTye和annotationKey
-
Config 因为插件不一定开启,还要附件的其他一些自定义的配置项,这些都是放到pinpoint.config中去配置的
-
Intercepter
实现AroundInterceptor1接口,在before方法和after后植入代码,进行trace操作
获取字节码处理引擎
InstrumentEngineProvider, 默认使用的是asm, 生成ASMEngine类,getClass方法返回
ASMClass,这个类中的所有方法是对asm的封装,便于更方便使用的,每个ProfilerPlugin实现类都有会实现TransformCallback接口,最终调用的的都是ASMClass的方法
ProfilePlugin加载
PluginContextLoadResultProvider在创建DefaultPluginContextLoadResult实例的时候,会找到所有plugin的jar,加载实现ProfilerPlugin接口,调用其setUp方法和设置
jdk加载注册
按照jdk标准加载agent里面的代码的话需要实现ClassFileTransformer接口,实现transform方法,然后在jvm应用启动,然后在类的字节码载入jvm前会调用,这个方法,从而实现修改原来方法的功能
pinpoint实现了是通过ClassFileTransformerDispatcher这个最上层的类,TransformTemplate的transform方法会将抽象出来的模板类TransformCallback,ClassFileTransformerLoader会将将这个callback包装为MatchableClassFileTransformerGuardDelegate(同样实现了jdk标准的ClassFileTransformer接口)然后,添加到自己的一个内部集合中去,之后ClassFileTransformerDispatcher会获取这个集合做后续处理。
数据发送
核心数据结构
pinpoint涉及到的数据结构体都在thrift module下面,主要是Pinpoint.thift和Trace.thrift这两个文件
主要有TJvmInfo,TAgentInfo,TJvmGc,TJvmGcDetailed,TCpuLoad,TTransaction,TActiveTraceHistogram,TActiveTrace,TResponseTime,TAgentStat,TAgentStatBatch,TSpan,TSpanChunk,TApiMetaData等
发送实现
数据离不开agent和span,所有的sender都围绕这几个核心
数据发送调用provider产生的这些dataSender,以下几个3个核心的sender类的provider,由guice进行实例化
- SpanDataSenderProvider (span采集打点)
- StatDataSenderProvider (agent状态信息采集打点)
- AgentInfoSenderProvider (agent的信息采集打点)
数据聚合
所有sender打印的日志都写在pinpoint.log文件下,具体文件的位置是jar包启动的环境变量, 然后,运维会通过firebeats将日志进行实时搜集,发送到kafka, 由jstorm的topology消费,在将数据写入到hbase,自己基于pinpoint的tcp的receiver进行改造,数据写入到hbase
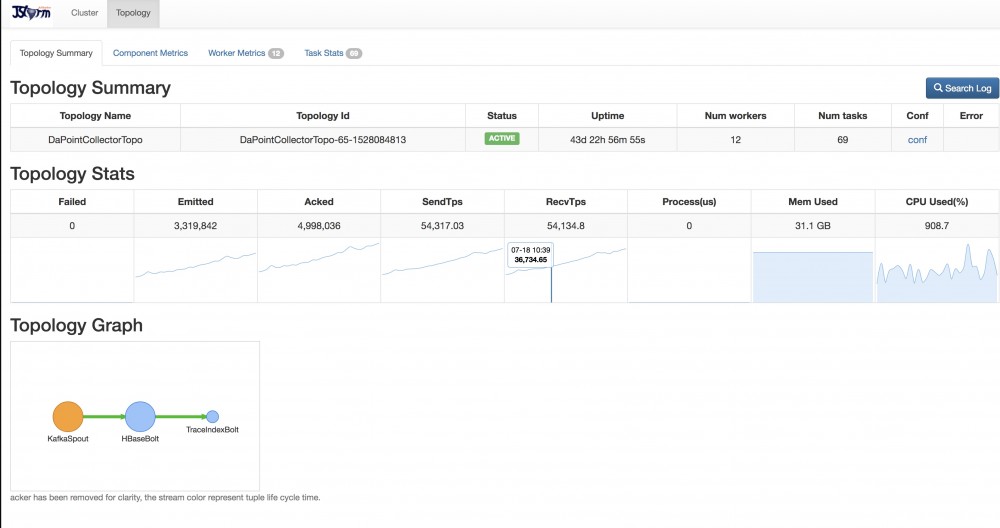
数据存储
数据存储包含agent的和span的数据,直接写入到hbase的,没有使用pheonix,使用的是pinpoint自己封装的工具进行操作,原生的hbase的增删改查可读性不是很好的,没有标准的sql语法来的自然清晰。

为了能通过一些查询条件和服务名称和调用的方法查询,在stom处理的时候,将这些信息写入到es,只保留近7天的数据,像这种多条件查询的话还是es性能好点.
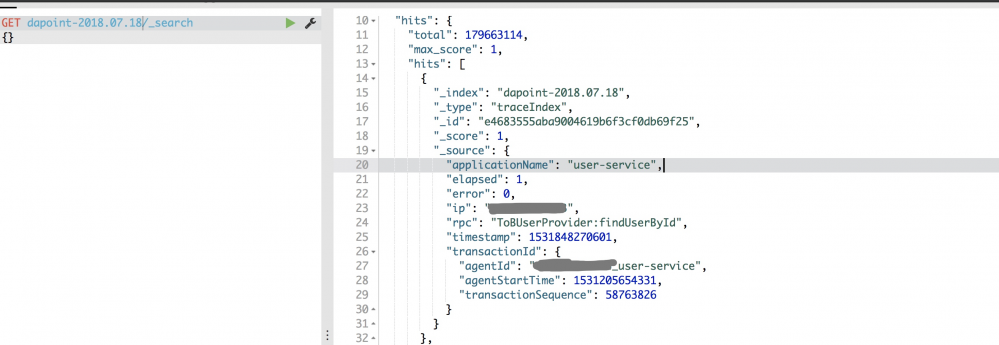
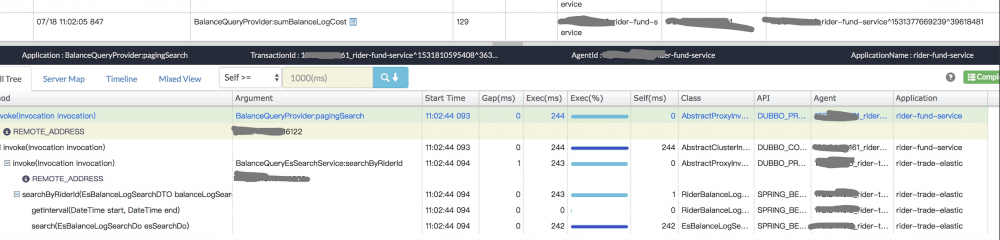
原有界面进行二次开发,加上这些条件,然后通过agentId,spanId,transactionId去查询链路信息, transactionId可以拿到所有相关的span,然后对所有的span根据关系串成一个属性结构的CallTreeNode
public class CallTreeNode {
private CallTreeNode parent;
private CallTreeNode child;
private CallTreeNode sibling;
private SpanAlign value;
public CallTreeNode(final CallTreeNode parent, SpanAlign value) {
this.parent = parent;
this.value = value;
}
正文到此结束
- 本文标签: apr http API plugin tag 服务器 实例 final UI Service equals TCP 端口 value cat src NSA ORM Agent java 解析 js 开发 配置 Action javaagent 时间 源码 key 进程 client Bootstrap ioc pinpoint spring App https 参数 sql Logging id 代码 启动过程 XML 线程 spring ioc IDE bean 字节码 目录 CTO ip 插件 HBase ACE IO Netty ssl json tar provider 数据 constant JVM CEO node list
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐








相关文章

近期评论
-
收到
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
-
-
-
https://pplx.ai/floraliu4199466 这个链接打不开是什么原因?
-
-
-
-
来看看,最近更新了一波,顺着友联过来的,几年过去了,网站越搞越好,厉害
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

