流式处理框架storm浅析(下篇)
本文来自网易云社区
作者:汪建伟
-
举个栗子
1 实现的目标
设计一个系统,来实现对一个文本里面的单词出现的频率进行统计。
2 设计Topology结构:
这是一个简单的例子,topology也非常简单。整个topology如下:

整个topology分为三个部分:
WordReader :数据源,负责发送sentence
WordNormalizer :负责将sentence切分
Wordcounter:负责对单词的频率进行累加
3 代码实现
1. 构建maven环境,添加storm依赖
<repositories> <!-- Repository where we can found the storm dependencies --> <repository> <id>clojars.org</id> <url>http://clojars.org/repo</url> </repository> </repositories> <dependencies> <dependency> <groupId>storm</groupId> <artifactId>storm</artifactId> <version>0.7.1</version> </dependency> </dependencies>复制代码
2. 定义Topology
public class TopologyMain {
public static void main(String[] args) throws InterruptedException {
//Topology definition
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("word-reader",new WordReader());
builder.setBolt("word-normalizer", new WordNormalizer())
.shuffleGrouping("word-reader");
builder.setBolt("word-counter", new WordCounter(),1)
.fieldsGrouping("word-normalizer", new Fields("word"));
//Configuration
Config conf = new Config();
conf.put("wordsFile", args[0]);
conf.setDebug(false);
//Topology run
conf.put(Config.TOPOLOGY_MAX_SPOUT_PENDING, 1);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("Getting-Started-Toplogie", conf, builder.createTopology());
Thread.sleep(1000);
cluster.shutdown();
}
}复制代码
3. 实现WordReader Spout
public class WordReader extends BaseRichSpout {
private SpoutOutputCollector collector;
private FileReader fileReader;
private boolean completed = false;
public void ack(Object msgId) {
System.out.println("OK:"+msgId);
}
public void close() {}
public void fail(Object msgId) {
System.out.println("FAIL:"+msgId);
}
public void nextTuple() {
if(completed){
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
}
return;
}
String str;
BufferedReader reader = new BufferedReader(fileReader);
try{
while((str = reader.readLine()) != null){
this.collector.emit(new Values(str),str);
}
}catch(Exception e){
throw new RuntimeException("Error reading tuple",e);
}finally{
completed = true;
}
}
public void open(Map conf, TopologyContext context,
SpoutOutputCollector collector) {
try {
this.fileReader = new FileReader(conf.get("wordsFile").toString());
} catch (FileNotFoundException e) {
throw new RuntimeException("Error reading file ["+conf.get("wordFile")+"]");
}
this.collector = collector;
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("line"));
}
}复制代码
第一个被调用的spout方法都是public void open(Map conf, TopologyContext context, SpoutOutputCollector collector)。它接收如下参数:配置对象,在定义topology对象是创建;TopologyContext对象,包含所有拓扑数据;还有SpoutOutputCollector对象,它能让我们发布交给bolts处理的数据。
4. 实现WordNormalizer bolt
public class WordNormalizer extends BaseBasicBolt {
public void cleanup() {}
public void execute(Tuple input, BasicOutputCollector collector) {
String sentence = input.getString(0);
String[] words = sentence.split(" ");
for(String word : words){
word = word.trim();
if(!word.isEmpty()){
word = word.toLowerCase();
collector.emit(new Values(word));
}
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}复制代码
bolt最重要的方法是void execute(Tuple input),每次接收到元组时都会被调用一次,还会再发布若干个元组。
5. 实现WordCounter bolt
public class WordCounter extends BaseBasicBolt {
Integer id;
String name;
Map counters;
@Override
public void cleanup() {
System.out.println("-- Word Counter ["+name+"-"+id+"] --");
for(Map.Entry entry : counters.entrySet()){
System.out.println(entry.getKey()+": "+entry.getValue());
}
}
@Override
public void prepare(Map stormConf, TopologyContext context) {
this.counters = new HashMap();
this.name = context.getThisComponentId();
this.id = context.getThisTaskId();
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {}
@Override
public void execute(Tuple input, BasicOutputCollector collector) {
String str = input.getString(0);
if(!counters.containsKey(str)){
counters.put(str, 1);
}else{
Integer c = counters.get(str) + 1;
counters.put(str, c);
}
}
}复制代码
6. 使用本地模式运行Topology
在这个目录下面创建一个文件,/src/main/resources/words.txt,一个单词一行,然后用下面的命令运行这个拓扑:mvn exec:java -Dexec.main -Dexec.args=”src/main/resources/words.txt”。
如果你的words.txt文件有如下内容: Storm test are great is an Storm simple application but very powerful really Storm is great 你应该会在日志中看到类似下面的内容: is: 2 application: 1 but: 1 great: 1 test: 1 simple: 1 Storm: 3 really: 1 are: 1 great: 1 an: 1 powerful: 1 very: 1 在这个例子中,每类节点只有一个实例。
-
附-Storm记录级容错的基本原理
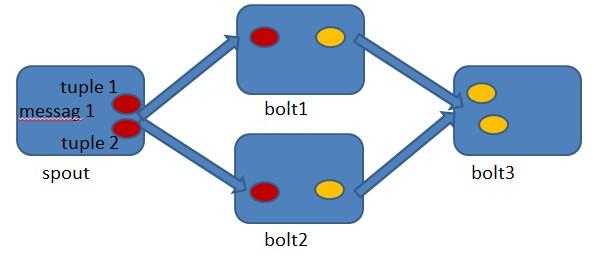
首先来看一下什么叫做记录级容错?storm允许用户在spout中发射一个新的源tuple时为其指定一个message id, 这个message id可以是任意的object对象。多个源tuple可以共用一个message id,表示这多个源 tuple对用户来说是同一个消息单元。storm中记录级容错的意思是说,storm会告知用户每一个消息单元是否在指定时间内被完全处理了。那什么叫做完全处理呢,就是该message id绑定的源tuple及由该源tuple后续生成的tuple经过了topology中每一个应该到达的bolt的处理。举个例子。在图4-1中,在spout由message 1绑定的tuple1和tuple2经过了bolt1和bolt2的处理生成两个新的tuple,并最终都流向了bolt3。当这个过程完成处理完时,称message 1被完全处理了。
在storm的topology中有一个系统级组件,叫做acker。这个acker的任务就是追踪从spout中流出来的每一个message id绑定的若干tuple的处理路径,如果在用户设置的最大超时时间内这些tuple没有被完全处理,那么acker就会告知spout该消息处理失败了,相反则会告知spout该消息处理成功了。在刚才的描述中,我们提到了”记录tuple的处理路径”,如果曾经尝试过这么做的同学可以仔细地思考一下这件事的复杂程度。但是storm中却是使用了一种非常巧妙的方法做到了。在说明这个方法之前,我们来复习一个数学定理。
A xor A = 0.
A xor B…xor B xor A = 0,其中每一个操作数出现且仅出现两次。
storm中使用的巧妙方法就是基于这个定理。具体过程是这样的:在spout中系统会为用户指定的message id生成一个对应的64位整数,作为一个root id。root id会传递给acker及后续的bolt作为该消息单元的唯一标识。同时无论是spout还是bolt每次新生成一个tuple的时候,都会赋予该tuple一个64位的整数的id。Spout发射完某个message id对应的源tuple之后,会告知acker自己发射的root id及生成的那些源tuple的id。而bolt呢,每次接受到一个输入tuple处理完之后,也会告知acker自己处理的输入tuple的id及新生成的那些tuple的id。Acker只需要对这些id做一个简单的异或运算,就能判断出该root id对应的消息单元是否处理完成了。下面通过一个图示来说明这个过程。
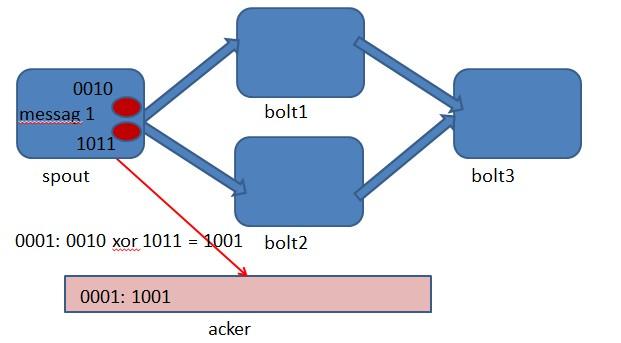
上图 spout中绑定message 1生成了两个源tuple,id分别是0010和1011.
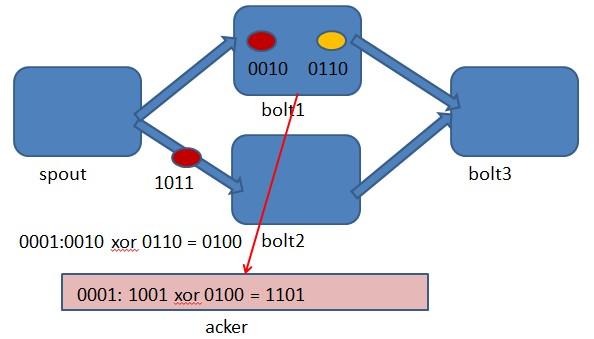
上图 bolt1处理tuple 0010时生成了一个新的tuple,id为0110.
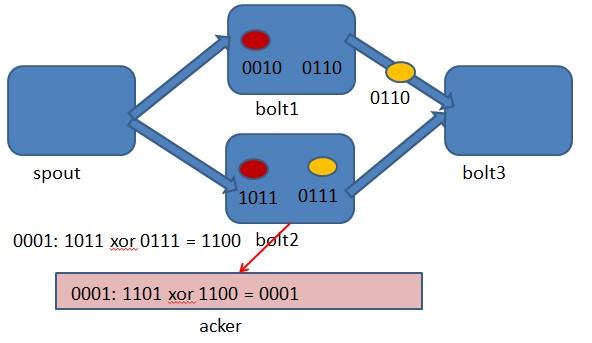
上图 bolt2处理tuple 1011时生成了一个新的tuple,id为0111.
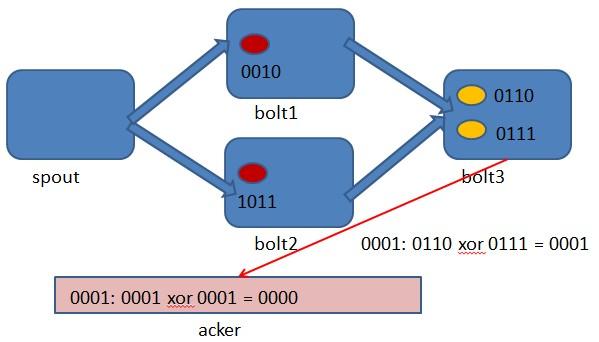
上图 bolt3中接收到tuple 0110和tuple 0111,没有生成新的tuple.
容错过程存在一个可能出错的地方,那就是,如果生成的tuple id并不是完全各异的,acker可能会在消息单元完全处理完成之前就错误的计算为0。这个错误在理论上的确是存在的,但是在实际中其概率是极低极低的,完全可以忽略。
相关阅读: 流式处理框架storm浅析(上篇)
网易云免费体验馆,0成本体验20+款云产品!
更多网易研发、产品、运营经验分享请访问网易云社区。
相关文章:
【推荐】 3分钟带你了解负载均衡服务
【推荐】 非对称加密与证书(上篇)
【推荐】 手游破解手段介绍及易盾保护方案
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

