结合jenkins以及PTP平台的性能回归测试
此文已由作者余笑天授权网易云社区发布。
欢迎访问网易云社区,了解更多网易技术产品运营经验。
1背景简介
1.1 jenkins
Jenkins是一个用Java编写的开源的持续集成工具。在与Oracle发生争执后,项目从Hudson项目复刻。Jenkins提供了软件开发的持续集成服务。它运行在Servlet容器中(例如Apache Tomcat)。它支持软件配置管理(SCM)工具(包括AccuRev SCM、 CVS 、 Subversion 、 Git 、 Perforce 、 Clearcase 和RTC),可以执行基于Apache Ant和Apache Maven的项目,以及任意的Shell脚本和Windows批处理命令。Jenkins的主要开发者是川口耕介。Jenkins是在MIT许可证下发布的自由软件。可以通过各种手段触发构建。例如提交给版本控制系统时被触发,也可以通过类似Cron的机制调度,也可以在其他的构建已经完成时,还可以通过一个特定的URL进行请求。
1.2 PTP平台
性能测试一直是业界重点关注的部分,但是复杂的性能测试过程却让很多人望而生畏:管理测试用例、收集测试数据、进行数据分析、编写测试报告,每一项都需要耗费很多心血。
于是,PTP平台就这样应运而生了,它是网易自主开发的自动化性能测试平台,致力于将性能测试过程自动化、标准化、一体化,并且将性能测试过程持续起来,进行更多数据分析。
2自动化流程
2.1创建任务
QA管理员拥有新建节点权限,如需增加新节点,请找各自的QA管理员。QA管理员在Jenkins上添加一个新节点步骤如下:
(1)点击链接进入
(2)输入节点名称,节点名称通常以服务器hostname或者机器描述命名,比如qa10.server,ddb-23.photo,QA_AutoTest_1等。
(3)选择Dumb Slave选项,点击OK按钮
(4)输入以下设置:
a.# of executors:输入执行器的个数(一个或者多个):这个值控制着Jenkins并发构建的数量, 因此这个值会影响Jenkins系统的负载压力。使用处理器个数作为其值会是比较好的选择。
b.Remote FS root:输入slave机器作为持续集成Home的路径
c.Labels:用来对多节点分组,在目前杭研的应用中,我们一般设置其跟节点名称一样
d.用法:一般选只运行绑定到这台机器的job
e.Launch Method选择Launch slave agents via Java Web Start
(5)保存
Node Properties可设置环境变量,如果不设置就会使用jenkins主机上全局定义的环境变量,如下图所示:

更详细的创建教程可参见wiki:http://doc.hz.netease.com/pages/viewpage.action?pageId=36463105
2.2 自动化环境部署
Jenkins上添加配置好的节点,如下所示:
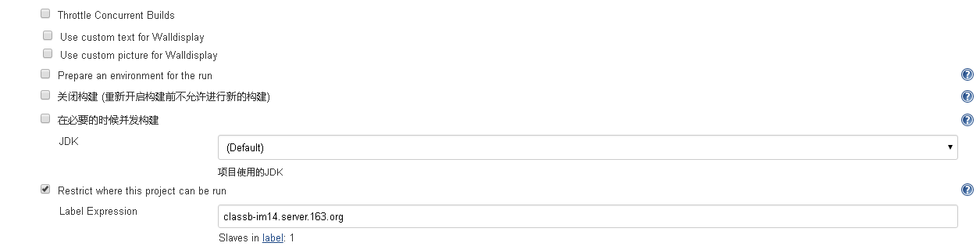
编写自动化部署脚本:
import requests
import time
import os
import sys
# web is deployed on two servers,the arguments in url:moduleId,envId,instanceId
test_web_arg_1 = ('***','***','***')
basi_url = 'http://omad.hz.netease.com/api'
productId = '***'
envName='urs-regzj-perftest'
branch='perftest_jenkins'
def get_token(appId, appSecret):
r = requests.get(basi_url + '/cli/login?appId=%s&appSecret=%s' % (appId, appSecret)).json
return r['params']['token']
def deploy_web(appId, appSecret,moduleId,envId):
test_web_url = '/cli/deploy?token=%s&moduleId=%s&envId=%s'%(get_token(appId, appSecret),moduleId, envId)
r = requests.get(basi_url + test_web_url).json
print 'Deploy result:'
def get_status(appId, appSecret,envId,instanceId):
status_url = '/cli/istatus?token=%s&envId=%s&instanceId=%s'%(get_token(appId, appSecret), envId, instanceId)
r = requests.get(basi_url + status_url).json
return r['deployStatus'],r['status']
def check_deploy_result(appId, appSecret,envId,instanceId):
status = get_status(appId, appSecret,envId,instanceId)
print 'building .......'
times = 0
while status[0] == 'success':
status = get_status(appId, appSecret,envId,instanceId)
times += 1复制代码
该过程主要是调用OMAD接口实现了自动化部署,分为以下几个步骤:
(1)调用/api/cli/login接口获取个人token信息;
(2)调用/api/cli/vcchange接口对指定产品的指定环境切换成指定分支;
(3)调用/api/cli/ls接口获取当前用户有权限的所有产品的所有工程的信息;
(4)调用/api/cli/deploy接口对指定环境的指定分支进行构建部署。
执行方式为python omad.py AccessKeyAccessSecret,其中$AccessKey和$AccessSecret为登录OMAD后的个人认证信息。
2.3 自动化脚本调试
在脚本执行前,我们需要脚本调试这个过程,该过程用来验证脚本是否能被正确执行,若脚本本来就存在问题等到执行时再去发现问题就可能浪费大量执行时间,因此在这个阶段,我们需要执行一次脚本,并验证脚本是否正确。
首先我们需要将所有的脚本上传到节点上,并保证该节点机安装有一些压测工具,这里以grinder为例,首先需要配置grinder.properties文件,以我的例子来说明:
script1 = createUser script2 = updateUinfo script3 = updateToken script4 = getUserInfo script5 = setSpecialRelation script6 = updateUserID script7 = getToken script8 = addFriend script9 = getFriendRelation script10 = updateRelationship script11 = addGroup script12 = queryTeam script13 = queryTeamNoUser script14 = joinTeams script15 = sendTeamMsg script16 = SendCustomMessage script17 = sendGroupMessage script18 = sendBatchAttachMsg script19 = sendBatchMsg script20 = kick grinder.script = Serial.py grinder.processes = 1 grinder.threads = 1 grinder.runs = 1复制代码
script.*代表是待调试脚本的名称,Serial.py是主脚本名,grinder.processes ,grinder.threads,grinder.runs 分别是grinder的进程,线程,以及运行次数,因为这部分主要是调试脚本,这里的参数全部设置为1。Serial.py实际是一个串行脚本,它负责顺序执行各脚本,代码如下所示:
from net.grinder.script.Grinder import grinder
from java.util import TreeMap
# TreeMap is the simplest way to sort a Java map.
scripts = TreeMap(grinder.properties.getPropertySubset("script"))
# Ensure modules are initialised in the process thread.
for module in scripts.values():
exec("import %s" % module)
def create_test_runner(module):
x=''
exec("x = %s.TestRunner()" % module)
return x
class TestRunner:
def __init__(self):
self.testRunners = [create_test_runner(m) for m in scripts.values()]
# This method is called for every run.
def __call__(self):
#create_test_runner()
for testRunner in self.testRunners: testRunner()复制代码
执行完该脚本后需要验证该脚本的正确性,我的做法是验证classb-im14-0-data.log下的日志信息,读取error列的值,具体代码如下:
info = []
f = open('result.txt', 'w')
path = os.getcwd()
#print path
path+='/logs'
os.chdir(path)
path = os.getcwd()
#print path
file=open('classb-im14-0-data.log','r')
count=len(file.readlines())
while(count!=interfaceNum):
count=len(file.readlines())
file=open('classb-im14-0-data.log','r')
for line in file:
info.append(line.strip())
if line.find("Thread")>=0:
continue
else:
vec=line.split(',')
if vec[5].strip()!='0':
#print vec[5]
str=testIdToScene(vec[2].strip())
if str==None:
f.write('testId does not exit')
excuteflag=False
break
else:
str+=(' Error/n')
f.write(str)
flag=False
if flag==True and excuteflag==True:
f.write('All interfaces have been successfully executed')
f.close()
file.close()复制代码
以上脚本实现了读取error值的功能,但是在jenkins上即使执行过程中产生错误,只要构建过程中每个程序的退出状态是正常的,仍然会显示构建成功,为此需要编写以下脚本,使脚本执行失败时保证该构建过程同时失败:
#!/bin/bash
if grep "All interfaces have been successfully executed" result.txt
then
echo "result is right"
exit 0
else
echo "result is wrong"
exit 1
fi复制代码
该脚本在有脚本执行失败的情况下会强制退出状态为1,从而使得构建失败。
2.4 自动化脚本执行以及结果收集
脚本执行需要借助ptp平台的插件,具体如图所示:
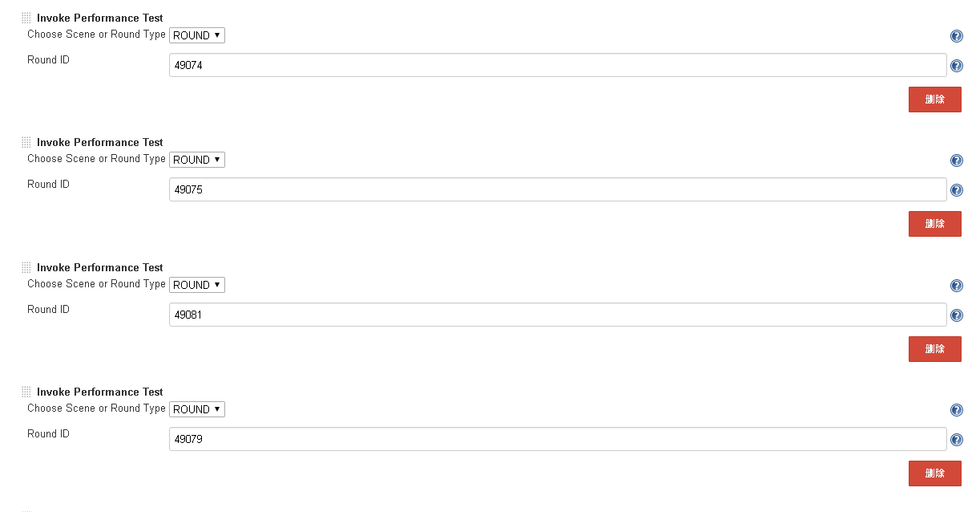
执行完成后,需要获取PTP平台的执行结果,判断执行过程中是否有错误产生,具体脚本如下所示:
import os
flagSucess=True
path = os.getcwd()
path_pertest=path
path+='/projects'
path_curr=path
f=open("/home/qatest/monitorTools/conf/topnFilesRes.txt")
file = open('result.txt', 'w')
info=[]
for line in f:
tmp=line.strip()
path+="/"+tmp
info.append(path)
path=path_curr
for i in info:
i+="/logs"
os.chdir(i)
fileSize = os.path.getsize("error_grinder.log")
if fileSize!=0:
flagSucess=False
os.chdir(path_pertest)
i += " make an error"
file.write(i)
if flagSucess:
file.write("All rounds have been successfully executed")复制代码
完成该部分后需要将测试结果持久化到数据库,这部分的思路是调用平台的/api/v1.0/round/${roundId}/summary接口,解析json数据,然后插入到数据库,具体代码如下。
首先需要利用httpclient获取该接口的结果然后进行解析:
public class GetRoundsAndJasonParse
{
@SuppressWarnings("finally")
public String getJasonRes(String roundID) throws HttpException
{
String res=null;
String prefix="http://perf.hz.netease.com/api/v1.0/round/";
prefix+=roundID;
prefix+="/summary";
HttpClient client = new HttpClient();
GetMethod getMethod = new GetMethod(prefix);
try
{
client.executeMethod(getMethod);
//res = new String(getMethod.getResponseBodyAsString());
BufferedReader reader = new BufferedReader(new InputStreamReader(getMethod.getResponseBodyAsStream()));
StringBuffer stringBuffer = new StringBuffer();
String str = "";
while((str = reader.readLine())!=null)
{
stringBuffer.append(str);
}
res = stringBuffer.toString();
} catch (HttpException e)
{
e.printStackTrace();
}
finally
{
getMethod.releaseConnection();
return res;
}
}
public ArrayList<Perf> getValue(JsonObject json,String[] key)
{
FormattingPerf fp = new FormattingPerf();
ArrayList<Perf> res=new ArrayList<Perf>();
ArrayList<String> values=new ArrayList<String>();
String machine_name=null;
String test_id=null;
String tmp=null;
try
{
//if(json.containsKey(key))
String resStr = json.get("success").getAsString();
if(resStr.equals("false"))
System.out.println("Check your roundID");
else
{
JsonArray array=json.get("data").getAsJsonArray();
for(int i=0;i<array.size();i++)
{
JsonObject subObject=array.get(i).getAsJsonObject();
machine_name=subObject.get("machine_name").getAsString();
test_id=subObject.get("test_id").getAsString();
if(machine_name.equals("all")&&!test_id.equals("0"))
{
for(int j=0;j<key.length;j++)
{
tmp=subObject.get(key[j]).getAsString();
values.add(tmp);
}
Perf perf=new Perf(values);
fp.formatPerf(perf);
res.add(perf);
values.clear();
}
}
}
}
catch (Exception e)
{
e.printStackTrace();
}
return res;
}
@SuppressWarnings("finally")
public ArrayList<Perf> parseJason(String jasonbody) throws JsonIOException, JsonSyntaxException
{
//ArrayList<String> res=new ArrayList<String>();
ArrayList<Perf> res=new ArrayList<Perf>();
JsonParser parse =new JsonParser();
try
{
JsonObject json=(JsonObject) parse.parse(jasonbody);
String[] key={"test_id","perf_round_id","tps","response_ave","response90","err_rate","mean_response_length"};
res=getValue(json,key);
} catch (JsonIOException e)
{
e.printStackTrace();
}
catch (JsonSyntaxException e)
{
e.printStackTrace();
}
finally
{
return res;
}
}复制代码
然后需要进行进行数据持久化的操作,这部分的代码实现的方式有多重,就不在此赘述,至此完成了自动化回归的部分过程,后续的结合哨兵监控以及对资源、性能数据进行进一步分析可以做更多的工作,欢迎有兴趣的同学一起来讨论。
免费体验云安全(易盾)内容安全、验证码等服务
更多网易技术、产品、运营经验分享请点击。
相关文章:
【推荐】 收集、分析线上日志数据实战——ELK
正文到此结束
- 本文标签: 并发 js 软件 运营 云 压力 处理器 windows 调试 token tomcat json grep 开源 python web map executor db 代码 stream https 插件 进程 src message 认证 开发者 ELK servlet parse find final ACE apache 安全 ORM node API Agent git list 线程 client Job 测试 UI id maven 解析 tar 开发 http update cat Action remote 管理 equals ip value 数据库 build 免费 服务器 配置 IO jenkins App 参数 主机 java 产品 Property cvs 数据 ArrayList shell key Oracle Connection 文章 root 安装 NIO 自动化 时间
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
https://www.newcmy.com/register?aff=HBVX
建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。 -
出现OpenClaw "device signature expired"。the Gateway rejects if Math.abs(Date.now() - signedAt) > 10 * 60 * 1000 (10 minutes)
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

