Android 消息机制:Handler、MessageQueue 和 Looper
在这篇文章中,我们将会讨论 Android 的消息机制。提到 Handler,有过一些 Android 开发经验的都应该很清楚它的作用,通常我们使用它来通知主线程更新 UI。但是 Handler 需要底层的 MessageQueue 和 Looper 来支持才能运作。这篇文章中,我们将会讨论它们三个之间的关系以及实现原理。
在这篇文章中,因为涉及线程方面的东西,所以就避不开 ThreadLocal。笔者在之前的文章中有分析过该 API 的作用,你可以参考笔者的这篇文章来学习下它的作用和原理,本文中我们就不再专门讲解: 《Java 并发编程:ThreadLocal 的使用及其源码实现》 。
1、Handler 的作用
通常,当我们在非主线程当中做了异步的操作之后使用 Handler 来在主线程当中更新 UI。之所以这么设计无非就是因为 Android 中的 View 不是线程安全的。之所以将 View 设计成非线程安全的,是因为:1).对 View 进行加锁之后会增加控件使用的复杂度;2).加锁之后会降低控件执行的效率。但 Handler 并非只能用来在主线程当中更新 UI,确切来说它有两个作用:
- 任务调度:即通过 post() 和 send() 等方法来指定某个任务在某个时间执行;
- 线程切换:你也许用过 RxJava,但如果在 Android 中使用的话还要配合 RxAndroid,而这里的 RxAndroid 内部就使用 Handler 来实现线程切换。
下文中,我们就来分别看一下它的这两个功能的作用和原理。
1.1 任务调度
使用 Hanlder 可以让一个任务在某个时间点执行或者等待某段时间之后执行。Handler 为此提供了许多方法,从方法的命名上,我们可以将其分成 post() 和 sned() 两类方法。post() 类的用来指定某个 Runnable 在某个时间点执行,send() 类的用来指定某个 Message 在某个时间点执行。
这里的 Message 是 Android 中定义的一个类。它内部有多个字段,比如 what 、 arg1 、 arg2 、 replyTo 和 sendingUid 来帮助我们指定该消息的内容和对象。同时, Message 还实现了 Parcelable 接口,这表明它可以被用来跨进程传输。此外,它内部还定义了一个 Message 类型的 next 字段,这表明 Message 可以被用作链表的结点。实际上 MessageQueue 里面只存放了一个 mMessage ,即链表的头结点。所以, MessageQueue 内部的消息队列,本质上是一个单链表,每个链表的结点就是 Message 。
当调用 post() 类型的方法来调度某个 Runnable 的时候,首先会将其包装成一个 Message,然后再使用 send() 类的方法进行任务分发。所以,不论是 post() 类的方法还是 send() 类的方法,最终都会使用 Handler 的 sendMessageAtTime() 方法来将其加入到队列中:
public boolean sendMessageAtTime(Message msg, long uptimeMillis) {
MessageQueue queue = mQueue;
if (queue == null) {
// ... 无关代码
return false;
}
return enqueueMessage(queue, msg, uptimeMillis);
}
复制代码
使用 Handler 进行任务调度是非常简单的。下面的代码就实现了让一个 Runnable 在 500ms 之后执行的逻辑:
new Handler().postDelayed(new Runnable() {
@Override
public void run() {
// do something
}
}, 500);
复制代码
上面的任务执行方式在主线程中执行不会出现任何问题,如果你在非主线程中执行的话就可能会出现异常。原因我们后面会讲解。
既然每个 Runnable 被 post() 发送之后还要被包装成 Message,那么 Message 的意义何在呢?
Runnable 被包装的过程依赖于 Handler 内部的 getPostMessage() 方法。下面是该方法的定义:
private static Message getPostMessage(Runnable r) {
Message m = Message.obtain();
m.callback = r;
return m;
}
复制代码
可见,我们的 Runnable 会被赋值给 Message 的 callback。这种类型的消息无法做更详细的处理。就是说,我们无法利用消息的 what 、 arg1 等字段(本身我们也没有设置这些字段)。如果我们希望使用 Message 的这些字段信息,就需要:
- 首先,要使用 send() 类型的方法来传递我们的 Message 给 Handler;
- 然后,我们的 Handler 要覆写 handleMessage() 方法,并在该方法中获取每个 Message 并根据其内部的信息依次处理。
下面的一个例子用来演示 send() 类型的方法。首先,我们要定义 Handler 并覆写其 handleMessage() 方法来处理消息:
private final static int SAY_HELLO = 1;
private static Handler handler = new Handler() {
@Override
public void handleMessage(Message msg) {
switch (msg.what) {
case SAY_HELLO:
LogUtils.d("Hello!");
break;
}
}
};
复制代码
然后,我们向该 Handler 发送消息:
Message message = Message.obtain(handler); message.what = SAY_HELLO; message.sendToTarget(); 复制代码
这样,我们的 Handler 接收到了消息并根据其 what 得知要 SAY_HELLO ,于是就打印出了日志信息。除了调用 Message 的 sendToTarget() 方法,我们还可以直接调用 handler 的 sendMessage() 方法(sendToTarget() 内部调用了 handler 的 sendMessage())。
1.2 线程切换
下面我们用了一份示例代码,它会先在主线程当中实例化一个 Handler,然后在某个方法中,我们开启了一个线程,并执行了某个任务。2 秒之后任务结束,我们来更新 UI。
// 在主线程中获取 Handler
private static Handler handler = new Handler();
// 更新UI,会将消息发送到主线程当中
new Thread(() -> {
try {
Thread.sleep(2000);
handler.post(() -> getBinding().tv.setText("主线程更新UI"));
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
复制代码
上面之所以能够在主线程当中更新 UI,主要是因为我们的 Handler 是在主线程当中进行获取的。随后,我们调用 handler 的 post() 方法之后,传入的 Runnable 会被包装成 Message ,然后加入到主线程对应的消息队列中去,并由主线程对应的 Looper 获取到并执行。所以,就使得该 Runnable 的操作最终在主线程中完成。
也许你会觉得先在主线程当中获取到 Handler 然后再使用比较麻烦。别担心,我们还有另一种方式来解决这个问题。我们可以直接使用 Looper 的 getMainLooper() 方法来获取主线程对应的 Looper,然后使用它来实例化一个 Handler 并使用该 Handler 来处理消息:
new Handler(Looper.getMainLooper())
.post(() -> getBinding().tv.setText("主线程更新UI"));
复制代码
本质上,当我们调用 Handler 的无参构造方法,或者说不指定 Looper 的构造方法的时候,会直接使用当前线程对应的 Looper 来实例化 Handler。每个线程对应的 Looper 存储在该线程的局部变量 ThreadLocal 里。当某个线程的局部变量里面没有 Looper 的时候就会抛出一个异常。所以,我们之前说直接使用 new 来实例化一个 Handler 的时候可能出错就是这个原因。
主线程对应的 Looper 会在 ActivityThread 的静态方法 main() 中被创建,它会调用 Looper 的 prepareMainLooper() 静态方法来创建主线程对应的 Looper。然后会调用 Looper 的 loop() 静态方法来开启 Looper 循环以不断处理消息。这里的 ActivityThread 用来处理应用进程中的活动和广播的请求,会在应用启动的时候调用。ActivityThread 内部定义了一个内部类 H ,它继承自 Handler ,同样运行在主线程中,用来处理接收到的来自各个活动、广播和服务的请求。
除了使用主线程对应的 Looper,我们也可以开启我们自定义线程的 Looper。下面的代码中,我们开启了一个线程,并在线程中先调用 Looper 的 prepare() 静态方法,此时 Looper 会为我们当前的线程创建 Looper,然后将其加入到当前线程的局部变量里面。随后,当我们调用 Looper 的 loop() 方法的时候就开启了 Looper 循环来不断处理消息:
new Thread(() -> {
LogUtils.d("+++++++++" + Thread.currentThread());
Looper.prepare();
new Handler().post(() -> LogUtils.d("+++++++++" + Thread.currentThread()));
Looper.loop();
}).start();
复制代码
从以上的内容我们可以看出,Handler 之所以能够实现线程切换,主要的原因是其内部的消息队列是对应于每一个线程的。发送的任务会在该线程对应的消息队列中被执行。而成功获取到该线程对应的消息队列就依靠 ThreadLocal 来对每个线程对应的消息队列进行存储。
2、源码解析
以上,我们分析了 Handler 的主要的两种主要用途,并且在这个过程中,我们提及了许多 Handler、MessageQueue 和 Looper 的底层设计。在上面的文章中,我们只是使用了文字来进行描述。在下文中,我们来通过源码来验证我们上面提到的一些内容。
2.1 实例化 Handler
Handler 了提供了多个重载的构造方法,我们可以将其分成两种主要的类型。一种在构造方法中需要明确指定一个 Looper,另一种在构造方法中不需要指定任何 Looper,在构造方法内部会获取当前线程对应的 Looper 来初始化 Handler。
第一种初始化的方式最终都会调用下面的方法来完成初始化。这个方法比较简单,是基本的赋值操作:
public Handler(Looper looper, Callback callback, boolean async) {
mLooper = looper;
mQueue = looper.mQueue;
mCallback = callback;
mAsynchronous = async;
}
复制代码
第二种初始化的方式最终会调用下面的方法。这里使用 Looper 的静态方法 myLooper() 来获取当前线程对应的 Looper。如果当前线程不存在任何 Looper 就会抛出一个异常。
public Handler(Callback callback, boolean async) {
// 潜在内存泄漏的检查
if (FIND_POTENTIAL_LEAKS) {
final Class<? extends Handler> klass = getClass();
if ((klass.isAnonymousClass() || klass.isMemberClass() || klass.isLocalClass()) &&
(klass.getModifiers() & Modifier.STATIC) == 0) {
Log.w(TAG, "The following Handler class should be static or leaks might occur: " +
klass.getCanonicalName());
}
}
// 使用 Looper 的静态方法 myLooper() 来获取当前线程的 Looper
mLooper = Looper.myLooper();
if (mLooper == null) {
throw new RuntimeException();
}
mQueue = mLooper.mQueue;
mCallback = callback;
mAsynchronous = async;
}
复制代码
而 Looper 的静态方法 myLooper() 会使用线程局部变量 sThreadLocal 来获取之前存储到该线程内部的 Looper:
public static @Nullable Looper myLooper() {
return sThreadLocal.get();
}
复制代码
2.2 Looper 的初始化
前面我们也说过 Looper 的创建过程。对于主线程的 Looper 会在 ActivityThread 的 main() 方法中被调用:
public static void main(String[] args) {
// ... 无关代码
Looper.prepareMainLooper();
// ... 无关代码
// 开启 Looper 循环
Looper.loop();
throw new RuntimeException("Main thread loop unexpectedly exited");
}
复制代码
这里调用了 Looper 的静态方法 prepareMainLooper() 来初始化主线程的 Looper:
public static void prepareMainLooper() {
prepare(false);
synchronized (Looper.class) {
if (sMainLooper != null) {
throw new IllegalStateException("The main Looper has already been prepared.");
}
sMainLooper = myLooper();
}
}
复制代码
其内部先调用了 prepare(boolean) 方法来初始化一个 Looper 并将其放在线程局部变量 sThreadLocal 中,然后判断 sMainLooper 是否之前存在过。这是一种基本的单例校验,显然,我们只允许主线程的 Looper 被实例化一次。
同样,非主线程的 Looper 也只允许被实例化一次。当我们在非主线程实例化一个 Looper 的时候会调用它的 prepare() 静态方法。它同样调用了 prepare(boolean) 方法来初始化一个 Looper 并将其放在线程局部变量 sThreadLocal 中。所以,主线程和非主线程的 Looper 实例化的时候本质上是调用同样的方法,只是它们实现的时机不同,并且,都只能被实例化一次。
public static void prepare() {
prepare(true);
}
private static void prepare(boolean quitAllowed) {
if (sThreadLocal.get() != null) {
throw new RuntimeException("Only one Looper may be created per thread");
}
sThreadLocal.set(new Looper(quitAllowed));
}
复制代码
经过上述分析,我们可以得知,对于一个线程只能实例化一个 Looper,所以当我们在同一个线程中多次创建 Handler 实例,它们是共享一个 Looper 的。或者说是一个 Looper 对应多个 Handler 也是可以的。
2.3 MessageQueue 的实例化
相比于 Looper 和 Handler,MessageQueue 就显得相对复杂一些。因为内部用到了 JNI 编程。初始化、销毁和入队等事件都用到了 native 的方法。你可以在 android_os_MessageQueue 查看其源码的定义。
每当我们实例化一个 Looper 的时候会调用它的构造方法,并在其中实例化一个 MessageQueue:
private Looper(boolean quitAllowed) {
mQueue = new MessageQueue(quitAllowed);
mThread = Thread.currentThread();
}
复制代码
在实例化 Handler 的小节中可以看出,每次实例化一个 Handler 的时候,会从当前线程对应的 Looper 中取出 MessageQueue。所以,这里我们又可以得出结论一个 Handler 对应一个 MessageQueue。
当我们实例化一个 MessageQueue 的时候会使用它的构造方法。这里会调用 native 层的 nativeInit() 方法来完成 MessageQueue 的初始化:
MessageQueue(boolean quitAllowed) {
mQuitAllowed = quitAllowed;
mPtr = nativeInit();
}
复制代码
在 native 层, nativeInit() 方法的定义如下:
static jlong android_os_MessageQueue_nativeInit(JNIEnv* env, jclass clazz) {
NativeMessageQueue* nativeMessageQueue = new NativeMessageQueue();
if (!nativeMessageQueue) {
jniThrowRuntimeException(env, "Unable to allocate native queue");
return 0;
}
nativeMessageQueue->incStrong(env);
return reinterpret_cast<jlong>(nativeMessageQueue);
}
复制代码
从上面我们可以看出,在该方法中实例化了一个 NativeMessageQueue 之后返回了 mPtr 作为是 Java 层 MessageQueue 与NativeMessesageQueue 的桥梁。这个 long 类型的成员保存了 native 实例,这是 jni 开发中常用到的方式。因此 MessageQueue 同样使用 mPtr 来表示 native 层的消息队列。 NativeMessageQueue 在 native 层的部分定义和其构造方法的定义如下。
class NativeMessageQueue : public MessageQueue, public LooperCallback {
// ... 无关代码
NativeMessageQueue::NativeMessageQueue() :
mPollEnv(NULL), mPollObj(NULL), mExceptionObj(NULL) {
mLooper = Looper::getForThread();
if (mLooper == NULL) {
mLooper = new Looper(false);
Looper::setForThread(mLooper);
}
}
复制代码
从上面我们可以看出, NativeMessageQueue 继承自 MessageQueue 。并且在其内部实例化了一个 native 层的 Looper(其源码在Looper)。
在 Android 的 native 层存在着一个于 Java 层类似的 Looper,它的主要作用是用来与 Java 层的 Looper 相互配合完成 Android 中最主要的线程通信。当消息队列中有消息存入时,会唤醒 Natvice 层的 Looper。当消息队列中没有消息时或者消息尚未到处理时间时, Natvice 层的 Looper 会 block 住整个线程。所以,创建了 Java Looper 的线程只有在有消息待处理时才处于活跃状态,无消息时 block 在等待消息写入的状态。既然如此,当我们在主线程中开启了 Looper 循环的话,为什么不会 block 住整个线程而导致 ANR 呢?这是因为,我们的主线程的消息都会发送给主线程对应的 Looper 来处理,所以,本质上,我们主线程中的许多事件也都是以消息的形式发送给主线程的 Handler 来进行处理的。只有当某个消息被执行的时间过长的时候才会出现 ANR。
上面我们实例化了一个 Native 层的 Looper。在其中主要做到的逻辑如下:
void Looper::rebuildEpollLocked() {
// 如果之前存在的话就关闭之前的 epoll 实例
if (mEpollFd >= 0) {
mEpollFd.reset(); // 关闭旧的epoll实例
}
// 申请新的 epoll 实例,并且注册 “Wake管道”
mEpollFd.reset(epoll_create(EPOLL_SIZE_HINT));
LOG_ALWAYS_FATAL_IF(mEpollFd < 0, "Could not create epoll instance: %s", strerror(errno));
struct epoll_event eventItem;
// 把未使用的数据区域进行置0操作
memset(& eventItem, 0, sizeof(epoll_event));
eventItem.events = EPOLLIN;
eventItem.data.fd = mWakeEventFd.get();
// 将唤醒事件 (mWakeEventFd) 添加到 epoll 实例 (mEpollFd)
int result = epoll_ctl(mEpollFd.get(), EPOLL_CTL_ADD, mWakeEventFd.get(), &eventItem);
LOG_ALWAYS_FATAL_IF(result != 0, "Could not add wake event fd to epoll instance: %s", strerror(errno));
// 这里主要添加的是Input事件如键盘,传感器输入,这里基本上由系统负责,很少主动去添加
for (size_t i = 0; i < mRequests.size(); i++) {
const Request& request = mRequests.valueAt(i);
struct epoll_event eventItem;
request.initEventItem(&eventItem);
// 将 request 队列的事件,分别添加到 epoll 实例
int epollResult = epoll_ctl(mEpollFd.get(), EPOLL_CTL_ADD, request.fd, &eventItem);
}
}
复制代码
这里涉及了epoll 相关的知识。 epoll 是一个可扩展的 Linux I/O 事件通知机制,用来实现多路复用 (Multiplexing)。它将唤醒事件按对应的 fd 注册进 epoll,然后 epoll 帮你监听哪些唤醒事件上有消息到达。此时的唤醒事件应该采用非阻塞模式。这样,整个过程只在调用 epoll 的时候才会阻塞,收发客户消息是不会阻塞的,整个进程或者线程就被充分利用起来,这就是事件驱动,所谓的响应模式。
上面的代码中使用了 epoll_ctl 方法来将被监听的描述符添加到 epoll 句柄。关于 epoll 的指令,可以参考这篇博文 《epoll机制:epoll_create、epoll_ctl、epoll_wait、close》 。这部分代码的主要作用是创建一个 epoll 实例并用它来监听 event 触发。
2.4 消息的执行过程
2.4.1 消息入队的过程
在介绍 Handler 的使用的时候,我们也说过不论是 Runnable 还是 Message 最终都会被封装成 Meseage 并加入到队列中。那么,加入队列之后又是怎么被执行的呢?
首先,我们先看下入队的过程。以下是 Handler 中定义的方法,每当我们将一个消息入队的时候,都会调用它来完成。
private boolean enqueueMessage(MessageQueue queue, Message msg, long uptimeMillis) {
msg.target = this;
if (mAsynchronous) {
msg.setAsynchronous(true);
}
return queue.enqueueMessage(msg, uptimeMillis);
}
复制代码
从上面可以看出,入队的时候实际上是使用了 MessageQueue 的 enqueueMessage() 方法。所以,我们再来看下该方法的定义:
boolean enqueueMessage(Message msg, long when) {
// ... 无关代码,校验
synchronized (this) {
// ... 无关代码
Message p = mMessages;
boolean needWake;
if (p == null || when == 0 || when < p.when) {
msg.next = p;
mMessages = msg;
needWake = mBlocked;
} else {
needWake = mBlocked && p.target == null && msg.isAsynchronous();
Message prev;
for (;;) {
prev = p;
p = p.next;
if (p == null || when < p.when) {
break;
}
if (needWake && p.isAsynchronous()) {
needWake = false;
}
}
msg.next = p;
prev.next = msg;
}
if (needWake) {
nativeWake(mPtr);
}
}
return true;
}
复制代码
从上面的方法可以看出,所谓的入队操作本质上就是一个将新的消息加入到队列中的逻辑。当然,这里加入的时候要根据消息的触发时间对消息进行排序。然后,会根据 needWake 来决定是否调用 native 层的方法进行唤醒。只有当当前的头结点消息之前存在栅栏 (barrier) 并且新插入的消息是最先要被触发的异步消息就进行唤醒。当一般情况下是无需进行唤醒的。
这里的 nativeWake() 方法会最终调用 native 层的 Looper 的 awake() 方法:
void Looper::wake() {
uint64_t inc = 1;
ssize_t nWrite = TEMP_FAILURE_RETRY(write(mWakeEventFd.get(), &inc, sizeof(uint64_t)));
if (nWrite != sizeof(uint64_t)) {
if (errno != EAGAIN) {
LOG_ALWAYS_FATAL("Could not write wake signal to fd %d: %s", mWakeEventFd.get(), strerror(errno));
}
}
}
复制代码
此方法向 mWakeEventFd 写入了一个字节的内容。到底是什么内容并不重要,重要的是 fd 存在内容了,换句话说就是 mWakeEventFd 可读了,也就是 Native 层的 Looper 的线程从 block 状态中醒了过来。之所以需要进行唤醒,是因为,每次我们处理了消息之后会根据下个消息执行的时间进行唤醒。如果新插入的消息是最新的消息,那么显然,我们需要把唤醒的时间重置。(Native 层的 Looper 会在我们调用 Java 层的 MessageQueue 的时候执行 epoll_wait 时进入 block 状态。)
2.4.2 消息执行的过程
在上文中,我们分析了 MessageQueue 将消息入队的过程。那么这些消息要在什么时候被执行呢?在介绍 Handler 的使用的时候,我们也提到过当我们实例化了 Looper 之后都应该调用它的 loop() 静态方法来处理消息。下面我们来看下这个方法的定义。
public static void loop() {
final Looper me = myLooper();
// .. 无关代码
final MessageQueue queue = me.mQueue;
// .. 无关代码
for (;;) {
Message msg = queue.next(); // 可能会 bolck
if (msg == null) {
return;
}
// ... 无关代码
final long dispatchEnd;
try {
msg.target.dispatchMessage(msg);
dispatchEnd = needEndTime ? SystemClock.uptimeMillis() : 0;
} finally {
if (traceTag != 0) {
Trace.traceEnd(traceTag);
}
}
// ... 无关代码
msg.recycleUnchecked();
}
}
复制代码
从上面我们可以看出,当该方法被调用的时候,它会先开启一个无限循环,并在该循环中使用 MessageQueue 的 next() 方法来取出下一个消息并进行分发。这里我们先不看 next() 方法的定义。我们先把这个方法中涉及的部分分析一下。
当获取到了下一个消息之后,会调用它的 target 也就是发送该消息的 Handler 的 dispatchMessage() 方法来进行处理。该方法的定义如下:
public void dispatchMessage(Message msg) {
if (msg.callback != null) {
handleCallback(msg);
} else {
if (mCallback != null) {
if (mCallback.handleMessage(msg)) {
return;
}
}
handleMessage(msg);
}
}
复制代码
从上面可以看出,如果该消息是通过包装 Runnable 得到的话,会直接调用它的 handleCallback() 方法进行处理。在该方法内部会直接调用 Runnable 的 run() 方法。因为比较见到那,我们就补贴出代码了。
然后,会根据 mCallback 是否为空来决定是交给 mCallback 进行处理还是内部的 handleMessage() 方法。这里的 mCallback 是一个接口,可以在创建 Handler 的时候通过构造方法指定,也比较简单。而这里的 handleMessage() 方法,我们就再熟悉不过了,它就是我们创建 Handler 的时候重写的、用来处理消息的方法。这样,消息就被发送到了我们的 Handler 中进行处理了。
以上就是消息被处理的过程,代码的逻辑还是比较清晰的。下面我们就来看下 MessageQueue 是如何获取 “下一个” 消息的。
2.4.3 MessageQueue 的消息管理
上面我们已经分析完了 Handler 发送的消息执行的过程。这里我们在来分析一下其中的获取 “下一个” 消息的逻辑:
Message next() {
// 如果消息循环已经停止就直接返回。如果应用尝试重启已经停止的Looper就会可能发生这种情况。
final long ptr = mPtr;
if (ptr == 0) {
return null;
}
int pendingIdleHandlerCount = -1; // -1 only during first iteration
int nextPollTimeoutMillis = 0;
for (;;) {
if (nextPollTimeoutMillis != 0) {
Binder.flushPendingCommands();
}
// 调用 native 的方法,可能会这个函数发生 block
nativePollOnce(ptr, nextPollTimeoutMillis);
// ... 无关代码
}
}
复制代码
从上面可以看出 Java 层的 MessageQueue 的 next() 方法是一个循环。除了获取消息队列之外,还要监听 Natvie 层 Looper 的事件触发。通过调用 native 层的 nativePollOnce() 方法来实现。该方法内部又会调用 NativeMessageQueue 的 pollOnce() 方法。而且注意下,在下面的方法中, nativeMessageQueue 是从 Java 层的 mPtr 中获取到的。所以我们说,在初始化 MessageQueue 的时候得到的 mPtr 起到了桥梁的作用:
static void android_os_MessageQueue_nativePollOnce(JNIEnv* env, jobject obj,
jlong ptr, jint timeoutMillis) {
NativeMessageQueue* nativeMessageQueue = reinterpret_cast<NativeMessageQueue*>(ptr);
nativeMessageQueue->pollOnce(env, obj, timeoutMillis);
}
复制代码
在 NativeMessageQueue 的 pollOnce() 方法中会调用 native 层的 Looper 的 pollOnce() ,并最终调用 native 层 Looper 的 pollInner() 方法:
int Looper::pollInner(int timeoutMillis) {
// ... 根据下一个消息的事件调整超时时间
int result = POLL_WAKE;
mResponses.clear();
mResponseIndex = 0;
mPolling = true; // 将要空闲
struct epoll_event eventItems[EPOLL_MAX_EVENTS];
// 待已注册之事件被触发或计时终了
int eventCount = epoll_wait(mEpollFd.get(), eventItems, EPOLL_MAX_EVENTS, timeoutMillis);
mPolling = false; // 不再空闲
mLock.lock(); // 请求锁
if (mEpollRebuildRequired) {
mEpollRebuildRequired = false;
rebuildEpollLocked(); // 根据需要重建 epoll
goto Done;
}
// 进行检查
if (eventCount < 0) {
if (errno == EINTR) {
goto Done;
}
result = POLL_ERROR; // 错误
goto Done;
}
if (eventCount == 0) {
result = POLL_TIMEOUT; // 超时
goto Done;
}
// 处理所有消息
for (int i = 0; i < eventCount; i++) {
int fd = eventItems[i].data.fd;
uint32_t epollEvents = eventItems[i].events;
if (fd == mWakeEventFd.get()) { // 唤醒 fd 有反应
if (epollEvents & EPOLLIN) {
awoken(); // 已经唤醒了,则读取并清空管道数据
}
} else {
// 其他 input fd 处理,其实就是将活动 fd 放入到 responses 队列中,等待处理
ssize_t requestIndex = mRequests.indexOfKey(fd);
if (requestIndex >= 0) {
int events = 0;
if (epollEvents & EPOLLIN) events |= EVENT_INPUT;
if (epollEvents & EPOLLOUT) events |= EVENT_OUTPUT;
if (epollEvents & EPOLLERR) events |= EVENT_ERROR;
if (epollEvents & EPOLLHUP) events |= EVENT_HANGUP;
// 将消息放进 mResponses 中
pushResponse(events, mRequests.valueAt(requestIndex));
}
}
}
Done: ;
// 触发所有的消息回调,处理 Native 层的Message
mNextMessageUptime = LLONG_MAX;
while (mMessageEnvelopes.size() != 0) {
nsecs_t now = systemTime(SYSTEM_TIME_MONOTONIC);
const MessageEnvelope& messageEnvelope = mMessageEnvelopes.itemAt(0);
if (messageEnvelope.uptime <= now) {
{ // 获取 handler
sp<MessageHandler> handler = messageEnvelope.handler;
Message message = messageEnvelope.message;
mMessageEnvelopes.removeAt(0);
mSendingMessage = true;
mLock.unlock();
handler->handleMessage(message);
} // 释放 handler
mLock.lock();
mSendingMessage = false;
result = POLL_CALLBACK;
} else {
// 队列头部的消息决定了下个唤醒的时间
mNextMessageUptime = messageEnvelope.uptime;
break;
}
}
mLock.unlock(); // 释放锁
// 触发所有的响应回调
for (size_t i = 0; i < mResponses.size(); i++) {
Response& response = mResponses.editItemAt(i);
if (response.request.ident == POLL_CALLBACK) {
int fd = response.request.fd;
int events = response.events;
void* data = response.request.data;
int callbackResult = response.request.callback->handleEvent(fd, events, data);
if (callbackResult == 0) {
removeFd(fd, response.request.seq); // 移除文件描述符
}
response.request.callback.clear();
result = POLL_CALLBACK;
}
}
return result;
}
复制代码
从上面我们可以看出 Native 层的 pollInner() 方法首先会根据 Java 层传入的 timeoutMillis 调用 epoll_wait 方法来让线程进入等待状态。如果 timeoutMillis 不为 0,那么线程将进入等待状态。如果有事件触发发生,wake 或者其他复用 Looper 的 event,处理event,这样整个 Native 层的 Looper 将从 block 状态中解脱出来了。这样回到 Java 层就将继续执行 MessageQueue 中下一条语句。至于 Native 层的 Looper 何时从 block 状态中醒过来,就需要根据我们入队的消息来定。也就用到了 MessageQueue 的 enqueueMessage() 方法的最后几行代码:
if (needWake) {
nativeWake(mPtr);
}
复制代码
即:只有当当前的头结点消息之前存在栅栏 (barrier) 并且新插入的消息是最先要被触发的异步消息就进行唤醒。
上面主要是 Native 层的 Looper 线程 block 的相关的逻辑。即当我们获取消息队列的下一条消息的时候会根据下一个消息的时间来决定线程 block 的时长。当我们将一个消息加入到队列的时候会根据新的消息的时间重新调整线程 block 的时长,如果需要的话还需要唤起 block 的线程。当线程从 block 状态恢复出来的时候,Java 层的 Looper 就拿到了一个消息,对该消息进行处理即可。
3、总结
在上文中,我们从 Java 层到 Native 层分析了 Handler 的作用的原理。这里我们对这部分内容做一个总结。
3.1 Handler、MessageQueue 和 Looper 之间的关系
首先是 Handler、MessageQueue 和 Looper 之间的关系。我们用下面的这个图来表示:

也就是说,一个线程中可以定义多个 Handler 实例,但是每个 Handler 实际上引用的是同一个 Looper。当然,我们要在创建 Handler 之前先创建 Looper。而每个 Looper 又只对应一个 MessageQueue。该 MessageQueue 会在创建 Looper 的时候被创建。在 MessageQueue 中使用 Message 对象来拼接一个单向的链表结构,依次来构成一个消息队列。每个 Message 是链表的一个结点,封装了我们发送的信息。
3.2 Handler 的消息发送过程
然后,我们再来分析下 Handler 中的消息是如何被发送的。同样,我们使用一个图来进行分析:
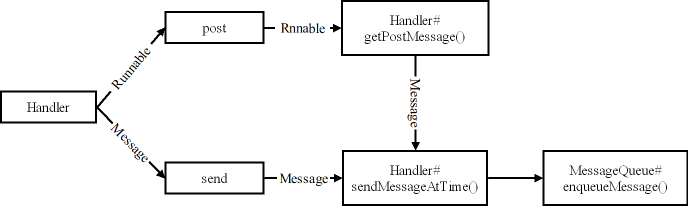
根据上文的内容我们将 Handler 发送消息的方法分成 post 和 send 两种类型。post 的用来发送 Runnable 类型的数据,send 类型的用来发送 Message 类型的数据。但不论哪种类型最终都会调用 Handler 的 sendMessageAtTime() 方法来加入到 MessageQueue 的队列中。区别在于,post 类型的方法需要经过 Handler 的 getPostMessage() 包装成 Message 之后再发送。
3.3 Looper 的执行过程
当消息被添加到队列之后需要执行消息,这部分内容在 Looper 的 loop() 方法中。但是这部分内容稍显复杂,因为涉及 Native 层的一些东西。我们这里仍然使用图来进行描述:
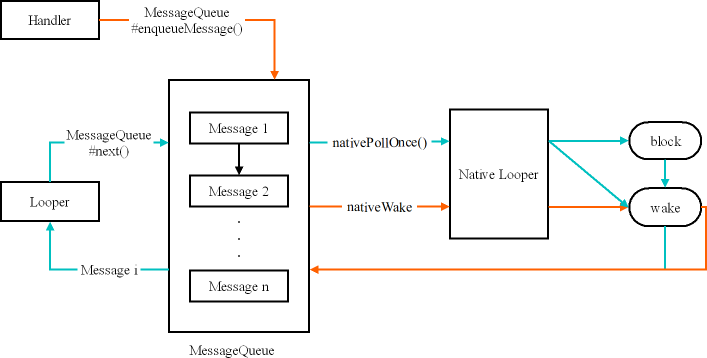
当我们调用 Looper 的 loop() 方法之后整个 Looper 循环就开始不断地处理消息了。在上图中就是我们用绿色标记的一个循环。当我们在循环中调用 MessageQueue 的 next() 方法来获取下一个消息的时候,会调用 nativePollOnce() 方法,该方法可能会造成线程阻塞和非阻塞,当线程为非阻塞的时候就会从 Native 层回到 Java 层,从 MessageQueuue 中取得一个消息之后给 Looper 进行处理。如果获取的时候造成线程阻塞,那么有两种情况会唤醒阻塞的线程,一个是当一个新的消息被加入到队列中,并且将会早于之前队列的所有消息被触发,那么此时将会重新设置超时时间。如果达到了超时时间同样可以从睡眠状态中返回,也就回到了 Java 层继续处理。所以,Native 层的 Looper 的作用就是通过阻塞消息队列获取消息的过程阻塞 Looper。
3.4 最后
因为本文中不仅分析了 Java 层的代码,同时分析了 framework 层的代码,所以最好能够结合两边的源码一起看,这样更有助于自己的理解。在上面的文章中,我们给出了一些类的在线的代码链接,在 Google Source 上面,需要 VPN 才能浏览。另外,因为笔者水平有限,难免存在有误和不足的地方,欢迎批评指正。
我是 WngShhng. 如果您喜欢我的文章,可以在以下平台关注我:
- 个人主页: shouheng88.github.io/
- 掘金: juejin.im/user/585555…
- Github: github.com/Shouheng88
- CSDN: blog.csdn.net/github_3518…
- 微博: weibo.com/u/540115211…
正文到此结束
- 本文标签: 文章 进程 SDN id value CST VPN https queue 数据 Android 构造方法 final java ACE 线程 Google 希望 key tag src git message UI 时间 静态方法 锁 linux 多个字段 find MQ API 消息队列 并发 build struct Job 安全 代码 线程通信 并发编程 http tar IO 管理 实例 retry 微博 ip 任务调度 cat GitHub 本质 开发 ECS 补贴 IDE 解析 synchronized 总结 源码
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章

近期评论
-
收到
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
-
-
-
https://pplx.ai/floraliu4199466 这个链接打不开是什么原因?
-
-
-
-
来看看,最近更新了一波,顺着友联过来的,几年过去了,网站越搞越好,厉害
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

