实例分析理解Java字节码
Java语言最广为人知的口号就是“一次编译到处运行”,这里的“编译”指的是编译器将Java源代码编译为Java字节码文件(也就是.class文件,本文中不做区分),“运行”则指的是Java虚拟机执行字节码文件。Java的跨平台得益于不同平台上不同的JVM的实现,只要提供规范的字节码文件,无论是什么平台的JVM都能够执行,这样字节码文件就做到了到处运行。这篇文章将通过一个简单的实例来分析字节码的结构,加深对Java程序运行机制的理解。
1、 准备.class文件
第一步,我们要准备一个字节码文件。先写一个简单的Java源程序 TestByteCode.java :
package com.sinosun.test;
public class TestByteCode{
private int a = 1;
public String b = "2";
protected void method1(){}
public int method2(){
return this.a;
}
private String method3(){
return this.b;
}
}
复制代码
使用 javac 命令将上面的代码进行编译,得到对应的TestByteCode.class文件,到这里就完成了第一步。
2、 人工解析.class文件
经过上一步已经得到了TestByteCode.class文件,也就是我们需要的字节码。我们不妨先来看一下文件的内容。(注意IDEA打开.class文件时会自动进行反编译,这里使用IDEA中的HexView插件查看.class文件,也可以使用Sublime Text直接打开.class文件)可以看到字节码文件中是一大堆16进制字节,下图中红色框中的部分就是.class文件中的真实内容:
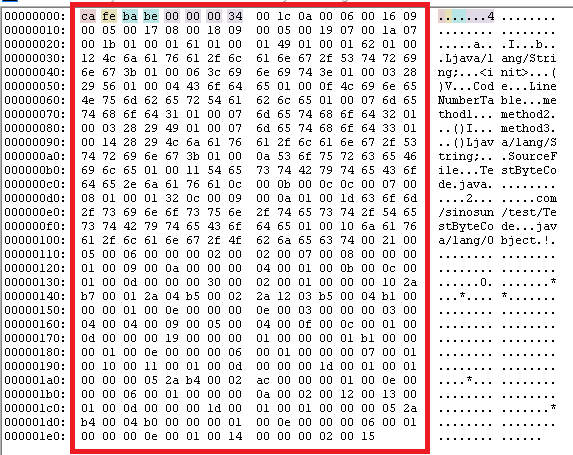
要想理解class文件,必须先知道它的组成结构。按照JVM的字节码规范,一个典型的class文件由十个部分组成:MagicNumber、Version、Constant_Pool、Access_flag、This_class、Super_class、Interface、Fields、Method以及Attributes。字节码中包括两种数据类型:无符号数和表。无符号数又包括 u1,u2,u4,u8四种,分别代表1个字节、2个字节、4个字节和8个字节。而表结构则是由无符号数据组成的。
根据规定,一个字节码文件的格式固定如下:

根据上表可以清晰地看出,字节码采用固定的文件结构和数据类型来实现对内容的分割,结构非常紧凑,没有任何冗余的信息,连分隔符都没有。
3、 魔数及版本号
根据结构表,.class文件的前四个字节存放的内容就是.class文件的魔数(magic number)。魔数是一个固定值: 0xcafebabe ,也是JVM识别.class文件的标志。我们通常是根据后缀名来区分文件类型的,但是后缀名是可以任意修改的,因此虚拟机在加载类文件之前会先检查这四个字节,如果不是 0xcafebabe 则拒绝加载该文件。
关于魔数为什么是 0xcafebabe ,请移步DZone围观James Gosling的解释。
版本号紧跟在魔数之后,由两个2字节的字段组成,分别表示当前.class文件的主版本号和次版本号,版本号数字与实际JDK版本的对应关系如下图。编译生成.class文件的版本号与编译时使用的-target参数有关。
| 编译器版本 | -target参数 | 十六进制表示 | 十进制表示 |
|---|---|---|---|
| JDK 1.6.0_01 | 不带(默认 -target 1.6) | 00 00 00 32 | 50 |
| JDK 1.6.0_01 | -target 1.5 | 00 00 00 31 | 49 |
| JDK 1.6.0_01 | -target 1.4 -source 1.4 | 00 00 00 30 | 48 |
| JDK 1.7.0 | 不带(默认 -target 1.6) | 00 00 00 32 | 50 |
| JDK 1.7.0 | -target 1.7 | 00 00 00 33 | 51 |
| JDK 1.7.0 | -target 1.4 -source 1.4 | 00 00 00 30 | 48 |
| JDK 1.8.0 | 无-target参数 | 00 00 00 34 | 52 |
第二节中得到的.class文件中,魔数对应的值为: 0x0000 0034 ,表示对应的JDK版本为1.8.0,与编译时使用的JDK版本一致。
4、 常量池
常量池是解析.class文件的重点之一,首先看常量池中对象的数量。根据第二节可知, constant_pool_count 的值为 0x001c ,转换为十进制为28,根据JVM规范, constant_pool_count 的值等于 constant_pool 中的条目数加1,因此,常量池中共有27个常量。
根据JVM规范,常量池中的常量的一般格式如下:
cp_info {
u1 tag;
u1 info[];
}
复制代码
共有11种类型的数据常量,各自的tag和内容如下表所示:
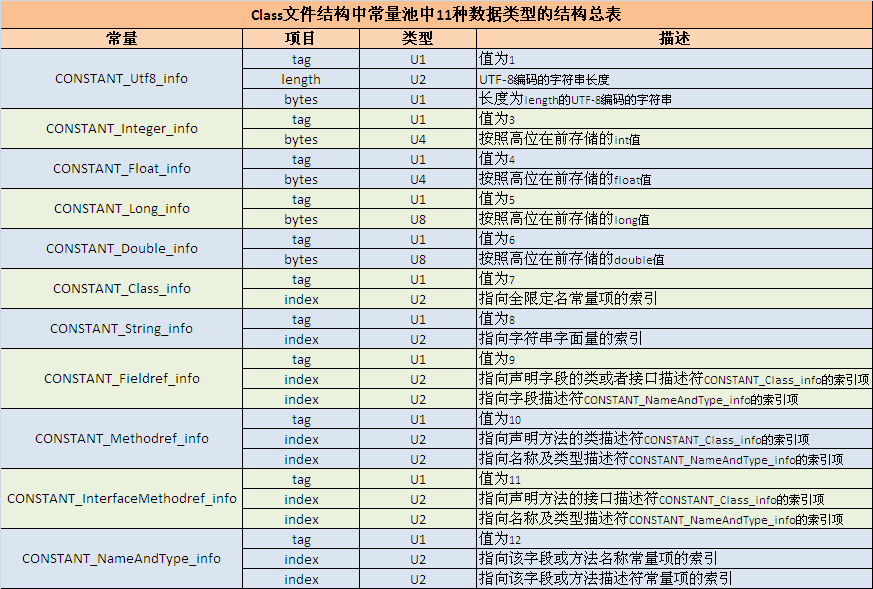
我们通过例子来查看如何分析常量,下图中,红线部分为常量池的部分内容。
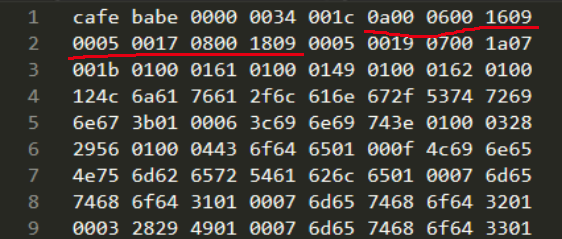
首先第一个tag值为 0x0a ,查看上面的表格可知该常量对应的是 CONSTANT_Methodref_info ,即指向一个方法的引用。tag后面的两个2字节分别指向常量池中的一个CONSTANT_Class_info型常量和一个CONSTANT_NameAndType_info型常量,该常量的完整数据为: 0a 0006 0016 ,两个索引常量池中的第6个常量和第22个常量,根据上表可以知道其含义为:
0a 0006 0016 Methodref class#6 nameAndType#22
因为还未解析第6个及第22个常量,这里先使用占位符代替。
同理可以解析出其它的常量,分析得到的完整常量池如下:
| 序号 | 16进制表示 | 含义 | 常量值 |
|---|---|---|---|
| 1 | 0a 0006 0016 | Methodref #6 #22 | java/lang/Object."":()V |
| 2 | 09 0005 0017 | Fieldref #5 #23 | com/sinosun/test/TestByteCode.a:I |
| 3 | 08 0018 | String #24 | 2 |
| 4 | 09 0005 0019 | Fieldref #5 #25 | com/sinosun/test/TestByteCode.b:Ljava/lang/String; |
| 5 | 07 001a | Class #26 | com/sinosun/test/TestByteCode |
| 6 | 07 001b | Class #27 | java/lang/Object |
| 7 | 01 0001 61 | UTF8编码 | a |
| 8 | 01 0001 49 | UTF8编码 | I |
| 9 | 01 0001 62 | UTF8编码 | b |
| 10 | 01 0012 4c6a6176612f6c616e672f537472696e673b | UTF8编码 | Ljava/lang/String; |
| 11 | 01 0006 3c 69 6e 69 74 3e | UTF8编码 | |
| 12 | 01 0003 28 29 56 | UTF8编码 | ()V |
| 13 | 01 0004 43 6f 64 65 | UTF8编码 | Code |
| 14 | 01 000f 4c696e654e756d6265725461626c65 | UTF8编码 | LineNumberTable |
| 15 | 01 0007 6d 65 74 68 6f 64 31 | UTF8编码 | method1 |
| 16 | 01 0007 6d 65 74 68 6f 64 32 | UTF8编码 | method2 |
| 17 | 01 0003 28 29 49 | UTF8编码 | ()I |
| 18 | 01 0007 6d 65 74 68 6f 64 33 | UTF8编码 | method3 |
| 19 | 01 0014 28294c6a6176612f6c616e672f537472696e673b | UTF8编码 | ()Ljava/lang/String; |
| 20 | 01 000a 53 6f 75 72 63 65 46 69 6c 65 | UTF8编码 | SourceFile |
| 21 | 01 0011 5465737442797465436f64652e6a617661 | UTF8编码 | TestByteCode.java |
| 22 | 0c 000b 000c | NameAndType #11 #12 | "":()V |
| 23 | 0c 0007 0008 | NameAndType #7 #8 | a:I |
| 24 | 01 0001 32 | UTF8编码 | 2 |
| 25 | 0c 0009 000a | NameAndType #9 #10 | b:Ljava/lang/String; |
| 26 | 01 001d 636f6d2f73696e6f73756e2f746573 742f5465737442797465436f6465 | UTF8编码 | com/sinosun/test/TestByteCode |
| 27 | 01 0010 6a6176612f6c616e672f4f626a656374 | UTF8编码 | java/lang/Object |
上表所示即为常量池中解析出的所有常量,关于这些常量的用法会在后文进行解释。
5、访问标志
access_flag 标识的是当前.class文件的访问权限和属性。根据下表可以看出,该标志包含的信息包括该class文件是类还是接口,外部访问权限,是否是 abstract ,如果是类的话,是否被声明为 final 等等。
| Flag Name | Value | Remarks |
|---|---|---|
| ACC_PUBLIC | 0x0001 | public |
| ACC_PRIVATE | 0x0002 | private |
| ACC_PROTECTED | 0x0004 | protected |
| ACC_STATIC | 0x0008 | static |
| ACC_FINAL | 0x0010 | final |
| ACC_SUPER | 0x0020 | 用于兼容早期编译器,新编译器都设置该标记,以在使用 invokespecial 指令时对子类方法做特定处理。 |
| ACC_INTERFACE | 0x0200 | 接口,同时需要设置:ACC_ABSTRACT。不可同时设置:ACC_FINAL、ACC_SUPER、ACC_ENUM |
| ACC_ABSTRACT | 0x0400 | 抽象类,无法实例化。不可与ACC_FINAL同时设置。 |
| ACC_SYNTHETIC | 0x1000 | synthetic,由编译器产生,不存在于源代码中。 |
| ACC_ANNOTATION | 0x2000 | 注解类型(annotation),需同时设置:ACC_INTERFACE、ACC_ABSTRACT |
| ACC_ENUM | 0x4000 | 枚举类型 |
本文的字节码文件中 access_flag 标志的取值为 0021 ,上表中无法直接查询到该值,因为 access_flag 的值是一系列标志位的并集, 0x0021 = 0x0020+0x0001 ,因此该类是public型的。
访问标志在后文的一些属性中也会多次使用。
6、类索引、父类索引、接口索引
类索引 this_class 保存的是当前类的全限定名在常量池中的索引,取值为 0x0005 ,指向常量池中的第5个常量,查表可知内容为: com/sinosun/test/TestByteCode 。
父类索引 super_class 保存的是当前类的父类的全局限定名在常量池中的索引,取值为 0x0006 ,指向池中的第6个常量,值为: java/lang/Object 。
接口信息 interfaces 保存了当前类实现的接口列表,包含接口数量和包含所有接口全局限定名索引的数组。本文的示例代码中没有实现接口,因此数量为0。
7、字段
接下来解析字段 Fields 部分,前两个字节是 fields_count ,值为 0x0002 ,表明字段数量为2。 其中每个字段的结构用 field_info 表示:
field_info {
u2 access_flags;
u2 name_index;
u2 descriptor_index;
u2 attributes_count;
attribute_info attributes[attributes_count];
}
复制代码
根据该结构来分析两个字段,第一个字段的内容为 0002 0007 0008 0000 ,访问标志位 0x0002 表示该字段是 private 型的,名称索引指向常量池中第7个值为 a ,类型描述符指向常量池中第8个值为 I ,关联的属性数量为0,可知该字段为 private I a ,其中 I 表示 int 。
同样,通过 0001 0009 000a 0000 可以分析出第二个字段,其值为 public Ljava/lang/String; b 。其中的 Ljava/lang/String; 表示 String 。
关于字段描述符与源代码的对应关系,下表是一个简单的示意:
| 描述符 | 源代码 |
|---|---|
| Ljava/lang/String; | String |
| I | int |
| [Ljava/lang/Object; | Object[] |
| [Z | boolean[] |
| [[Lcom/sinosun/generics/FileInfo; | com.sinosun.generics.FileInfo[][] |
8、方法
字段结束后进入对方法 methods 的解析,首先可以看到方法的数量为 0x0004 ,共四个。
不对啊! TestByteCode.java 中明明只有三个方法,为什么 .class 文件中的方法数变成了4个?
因为编译时自动生成了一个 <init> 方法作为类的默认构造方法。
接下来对每个方法进行分析,老规矩,分析之前首先了解方法的格式定义:
method_info {
u2 access_flags;
u2 name_index;
u2 descriptor_index;
u2 attributes_count;
attribute_info attributes[attributes_count];
}
复制代码
根据该格式,首先得到第一个方法的前8个字节 0001 000b 000c 0001 ,对照上面的格式以及之前常量池和访问标志的内容,可以知道该方法是: public <init> ()V ,且附带一个属性。可以看到该方法名就是 <init> 。对于方法附带的属性而言,有着如下格式:
attribute_info {
u2 attribute_name_index;
u4 attribute_length;
u1 info[attribute_length];
}
复制代码
继续分析后面的内容 000d ,查询常量池可以知道该属性的名称为: Code 。 Code 属性是 method_info 属性表中一种可变长度的属性,该属性中包括JVM指令及方法的辅助信息,如实例初始化方法或者类或接口的初始化方法。如果一个方法被声明为 native 或者 abstract ,那么其 method_info 结构中的属性表中一定不包含 Code 属性。否则,其属性表中必定包含一个 Code 属性。
Code属性的格式定义如下:
Code_attribute {
u2 attribute_name_index;
u4 attribute_length;
u2 max_stack;
u2 max_locals;
u4 code_length;
u1 code[code_length];
u2 exception_table_length;
{
u2 start_pc;
u2 end_pc;
u2 handler_pc;
u2 catch_type;
} exception_table[exception_table_length];
u2 attributes_count;
attribute_info attributes[attributes_count];
}
复制代码
对照上面的结构分析字节序列 000d 00000030 0002 0001 ,该属性为 Code 属性,属性包含的字节数为 0x00000030 ,即48个字节,这里的长度不包括名称索引与长度这两个字段。 max_stack 表示方法运行时所能达到的操作数栈的最大深度,为2; max_locals 表示方法执行过程中创建的局部变量的数目,包含用来在方法执行时向其传递参数的局部变量。
接下来是一个方法真正的逻辑核心——字节码指令,这些JVM指令是方法的真正实现。首先是 code_length 表示code长度,这里的值为16,表示后面16个字节是指令内容, 2a b7 0001 2a 04 b5 0002 2a 12 03 b5 0004 b1 。
为了便于理解,将这些指令翻译为对应的助记符:
| 字节码 | 助记符 | 指令含义 |
|---|---|---|
| 0x2a | aload_0 | 将第一个引用类型本地变量推送至栈顶 |
| 0xb7 | invokespecial | 调用超类构建方法, 实例初始化方法, 私有方法 |
| 0x04 | iconst_1 | 将int型1推送至栈顶 |
| 0xb5 | putfield | 为指定类的实例域赋值 |
| 0x12 | ldc | 将int,float或String型常量值从常量池中推送至栈顶 |
| 0xb1 | return | 从当前方法返回void |
对照表格可以看出这几个指令的含义为:
2a aload_0 b7 0001 invokespecial #1 //Method java/lang/Object."":()V 2a aload_0 04 iconst_1 b5 0002 putfield #2 //Field a:I 2a aload_0 12 03 ldc #3 //String 2 b5 0004 putfield #4 //Field b:Ljava/lang/String; b1 return
可以看出,在初始化方法中,先后将类自身引用this_class、类中的变量a和变量b入栈,并为两个变量赋值,之后方法结束。
指令分析结束后,是方法中的异常表,本方法中未抛出任何异常,因此表长度为 0000 。后面的 0001 表示后面有一个属性。根据之前的属性格式可以知道,该属性的名称索引为 0x000e ,查找常量池可知该属性为 LineNumberTable 属性。
下面是 LineNumberTable 属性的结构:
LineNumberTable_attribute {
u2 attribute_name_index;
u4 attribute_length;
u2 line_number_table_length;
{
u2 start_pc;
u2 line_number;
} line_number_table[line_number_table_length];
}
复制代码
结合该结构,分析 0000000e 0003 0000 0003 0004 0004 0009 0005 可知,该表中共有三项,第一个数字表示指令码中的字节位置,第二个数字表示源代码中的行数。
同理,可以对后面的方法进行分析。
第二个方法, 0004 000f 000c 0001 表示方法名及访问控制符为 protected method1 ()V ,且附有一个属性。 000d 00000019 ,毫无疑问,属性就是 Code ,长度为25个字节。
0000 0001 00000001 b1 可以看出操作数栈深度 max_stack 为0, max_locals 为1表示有一个局部变量,所有方法默认都会有一个指向其所在类的参数。方法体中只有一个字节指令,就是 return ,因为该方法是一个空方法。 0000 0001 表明没有异常,且附有一个属性。 000e 00000006 0001 0000 0007 属性是 LineNumberTable ,内容表明第一个字节指令与代码的第7行对应。
在后面两个方法中,使用了三个新的字节指令:
| 字节码 | 助记符 | 指令含义 |
|---|---|---|
| 0xb4 | getfield | 获取指定类的实例域, 并将其压入栈顶 |
| 0xac | ireturn | 从当前方法返回int |
| 0xb0 | areturn | 从当前方法返回对象引用 |
解析 0001 0010 0011 0001 000d 0000 001d 可知第三个方法为 public method2 ()I ,其 Code 属性内容为 0001 0001 00000005 2a b4 0002 ac , 获取变量 a 并返回。 后面仍然是异常信息和 LineNumberTable 。
第四个方法这里不再赘述。
0002 0012 0013 0001 000d 0000 001d private method3 ()Ljava/lang/String; Code 0001 0001 00000005 2a b4 0004 b0 获取变量b并返回 0000 LineNumberTable 0001 000e 00000006 0001 0000 000e //line 14 : 0
这样,我们就在字节码中解析出了类中的方法。字节指令是方法实现的核心,字节指令在任何一个JVM中都对应的是一样的操作,因此字节码文件可以实现跨平台运行。但是每一个平台中对字节指令的实现细节各有不同,这是Java程序在不同平台间真正"跨"的一步。
9、属性
最后一部分是该类的属性 Attributes ,数量为 0x0001 ,根据 attribute_info 来分析该属性。
attribute_info {
u2 attribute_name_index;
u4 attribute_length;
u1 info[attribute_length];
}
复制代码
前两个字节对应 name_index ,为 0x0014 ,即常量池中的第20个常量,查表得到 SourceFile ,说明该属性是 SourceFile 属性。该属性是类文件属性表中的一个可选定长属性,其结构如下:
SourceFile_attribute {
u2 attribute_name_index;
u4 attribute_length;
u2 sourcefile_index;
}
复制代码
得到该属性的全部内容为 0014 00000002 0015 ,对比常量表可知内容为“SourceFile ——TestByteCode.java”,也就是指定了该 .class 文件对应的源代码文件。
10、后记
本文到此就算结束了,看到这里的话应该对字节码的结构有了基本的了解。
但是,前面花了这么大篇幅所做的事情,Java早就提供了一个命令行工具 javap 全部实现了,进入 .class 文件所在的文件夹,打开命令行工具,键入如下命令:
javap -verbose XXX.class 复制代码
结果如下所示:
PS E:/blog/Java字节码/资料> javap -verbose TestByteCode.class
Classfile /E:/blog/Java字节码/资料/TestByteCode.class
Last modified 2018-9-6; size 494 bytes
MD5 checksum 180292e6f6e8e9e48807195b235fa8ef
Compiled from "TestByteCode.java"
public class com.sinosun.test.TestByteCode
minor version: 0
major version: 52
flags: ACC_PUBLIC, ACC_SUPER
Constant pool:
#1 = Methodref #6.#22 // java/lang/Object."<init>":()V
#2 = Fieldref #5.#23 // com/sinosun/test/TestByteCode.a:I
#3 = String #24 // 2
#4 = Fieldref #5.#25 // com/sinosun/test/TestByteCode.b:Ljava/lang/String;
#5 = Class #26 // com/sinosun/test/TestByteCode
#6 = Class #27 // java/lang/Object
#7 = Utf8 a
#8 = Utf8 I
#9 = Utf8 b
#10 = Utf8 Ljava/lang/String;
#11 = Utf8 <init>
#12 = Utf8 ()V
#13 = Utf8 Code
#14 = Utf8 LineNumberTable
#15 = Utf8 method1
#16 = Utf8 method2
#17 = Utf8 ()I
#18 = Utf8 method3
#19 = Utf8 ()Ljava/lang/String;
#20 = Utf8 SourceFile
#21 = Utf8 TestByteCode.java
#22 = NameAndType #11:#12 // "<init>":()V
#23 = NameAndType #7:#8 // a:I
#24 = Utf8 2
#25 = NameAndType #9:#10 // b:Ljava/lang/String;
#26 = Utf8 com/sinosun/test/TestByteCode
#27 = Utf8 java/lang/Object
{
public java.lang.String b;
descriptor: Ljava/lang/String;
flags: ACC_PUBLIC
public com.sinosun.test.TestByteCode();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=2, locals=1, args_size=1
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: aload_0
5: iconst_1
6: putfield #2 // Field a:I
9: aload_0
10: ldc #3 // String 2
12: putfield #4 // Field b:Ljava/lang/String;
15: return
LineNumberTable:
line 3: 0
line 4: 4
line 5: 9
protected void method1();
descriptor: ()V
flags: ACC_PROTECTED
Code:
stack=0, locals=1, args_size=1
0: return
LineNumberTable:
line 7: 0
public int method2();
descriptor: ()I
flags: ACC_PUBLIC
Code:
stack=1, locals=1, args_size=1
0: aload_0
1: getfield #2 // Field a:I
4: ireturn
LineNumberTable:
line 10: 0
}
SourceFile: "TestByteCode.java"
复制代码
基本就是我们之前解析得到的结果。
当然,我分享这些过程的初衷并不是希望自己或读者变成反编译工具,一眼看穿字节码的真相。这些事情人不会做的比工具更好,但是理解这些东西可以帮助我们做出更好的工具,比如CGlib,就是通过在类加载之前添加某些操作或者直接动态的生成字节码来实现动态代理,比使用java反射的JDK动态代理要快。
我总认为,人应该好好利用工具,但是也应该对工具背后的细节怀有好奇心与探索欲。就这篇文章来说,如果能让大家对字节码多一些认识,那目的就已经达到了。括弧笑
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

