
网站被人疯狂爬了 1.5TB 流量
我刚上线了一个小网站:skills.lc。
本来只是想做一个简单的 AI skills / agent skills 的索引站,方便大家查找各种 skills。
网站上线之后其实没怎么宣传,就在几个地方随便发了一下。
结果三天后,我突然发现服务器流量不太对劲。
流量直接爆了
看了一下最近几天的流量统计:
1.09 TB
1.21 TB
1.47 TB
1.57 TB
我第一反应是:
不会吧?难道火了?
但冷静想想,这网站用户量不足产生这么大的流量。
再仔细看日志,发现事情不太对。
原来是被人疯狂下载
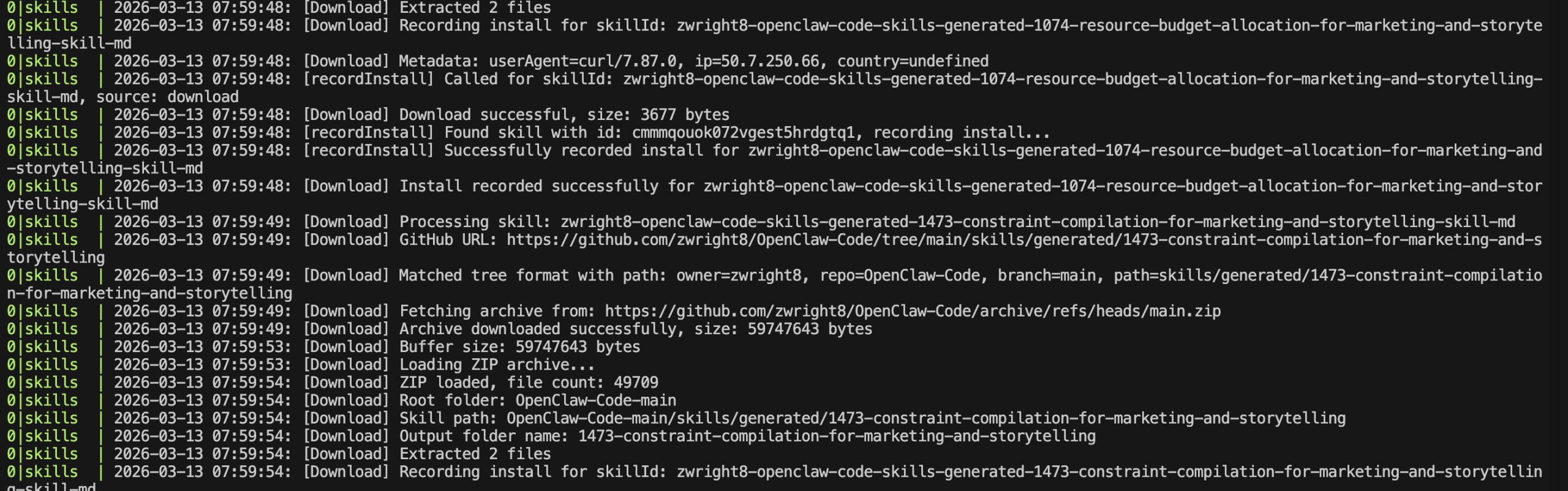
服务器日志里基本全是 curl 请求:
Time: 2026/3/13 15:09:26
Source: download
User Agent: curl/7.87.0
IP: 50.7.250.66
还有另一个:
Time: 2026/3/13 14:13:46
Source: download
User Agent: curl/8.16.0
IP: 121.237.245.164
这两个 IP 基本在 不停下载网站资源。
而且方式非常简单粗暴:
curl https://skills.lc/xxx
curl https://skills.lc/xxx
curl https://skills.lc/xxx
就是一条一条扫。
最离谱的是
我这个网站其实是一个 技能列表索引,
里面很多资源其实都是公开的 GitHub 内容。
但对方没有直接去 GitHub 拉。
而是:
从我的服务器反复下载。

于是就出现了一个很魔幻的情况:
我成了一个 免费 CDN。
别人疯狂 pull 数据,
而我疯狂烧服务器流量。
为什么有人会这么干?
我猜可能有几种原因:
1 爬全站做镜像
很多人做 AI 工具站的时候,会先把别人网站的数据全爬下来。
2 训练数据
AI 时代很多人会疯狂抓数据。
3 做聚合站。
有些 bot 就是全网扫。
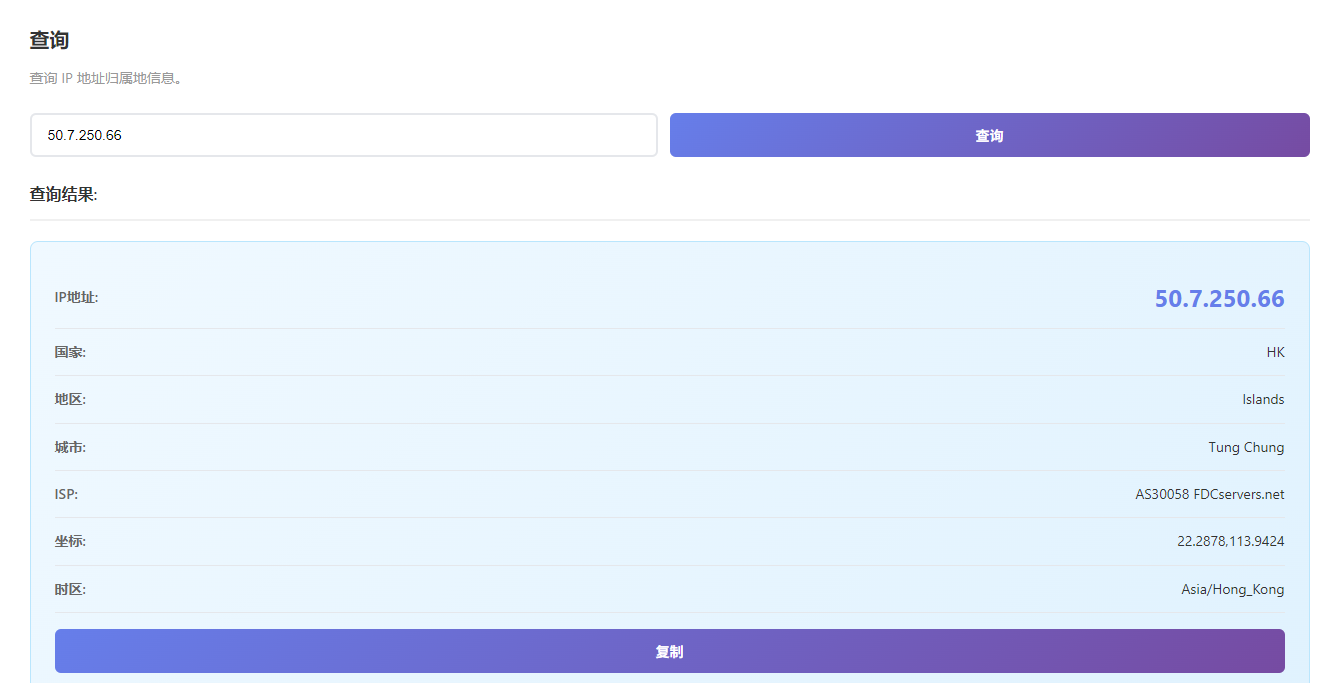
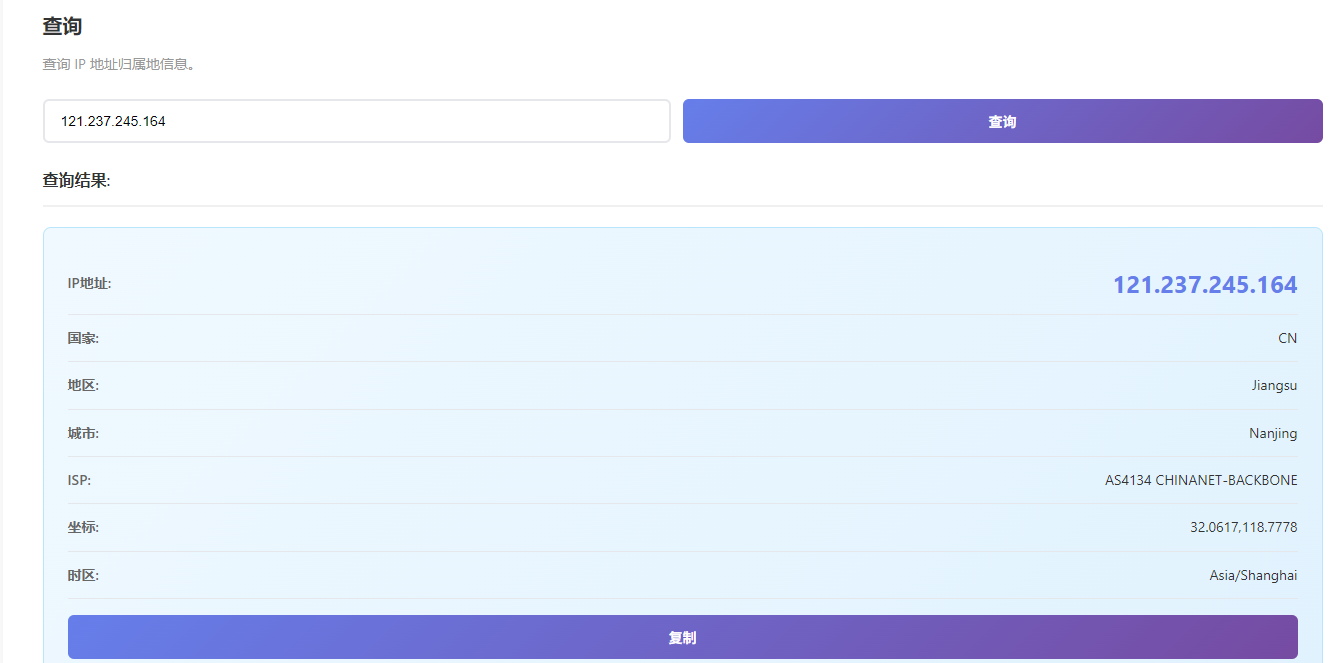
目前已经锁定两个 IP
50.7.250.66(香港ip)
121.237.245.164(江苏南京)
User-Agent:
curl/7.87.0
curl/8.16.0
基本可以确定是脚本。
准备做的几个防护
接下来准备做几件事情:
1 IP 限速
同一个 IP 每分钟限制请求数。
2 Cloudflare 防护
开启 bot fight。
3 下载接口加 token
避免直接 curl。
4 robots + WAF
防止简单爬虫。
做独立站的一个现实
以前总觉得:
网站没人访问是最大问题。
现在发现:
网站刚上线,被爬才是最大问题。
很多爬虫比用户来的还快。
一个小感慨
互联网其实很有意思。
你刚做了个小工具站,
还没来得及推广,
就已经有人在默默复制你的数据了。
如果你也做过类似的站,
有没有遇到这种情况?
最后对南京和香港的那2位朋友说一声,如果你真想要我网站的数据,来收购我网站就行呀,省得让我产生天价流量费账单
正文到此结束
- 本文标签: skills
- 版权声明: 本文由HARRIES原创发布,转载请遵循《署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)》许可协议授权
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
出现OpenClaw "device signature expired"。the Gateway rejects if Math.abs(Date.now() - signedAt) > 10 * 60 * 1000 (10 minutes)
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
博主的博客用的什么技术栈,内容都是干货,赞
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

