给openclaw安装耳朵(语音支持)
一、安装语音处理依赖(以 Debian/Ubuntu Docker 为例)
- 更新系统套件索引
apt-get update
- 安装必要工具(Python pip / ffmpeg)
apt-get install -y python3-pip ffmpeg
- 若系统启用了 PEP 668(禁止直接 pip),可在 pip 指令后面加
--break-system-packages,或先建一个 venv 再安装。这里走“用户目录 + break-system-packages”的做法。
二、安装语音识别模型(Whisper)
python3 -m pip install --user --break-system-packages openai-whisper
- 套件会装到
~/.local/lib/python3.11/site-packages - CLI 工具
whisper会放在~/.local/bin(如果 PATH 没包含,后续命令记得写全路径/home/node/.local/bin/whisper,或把它加入 PATH)
三、把语音转成文字(Whisper CLI 示例)
/home/node/.local/bin/whisper \
/path/to/audio.ogg \
--language zh \
--model base \
--output_format txt \
--output_dir /home/node/.openclaw/workspace
--language zh:强制中文识别,避免模型猜错语言--model base:可换成small/medium/large(越大越准但越慢)--output_format txt:生成纯文字稿;还能同时输出.srt/.vtt时间轴- 结果会存成
<音频文件名>.txt(或对应用的格式)在指定目录
四、用 Python 直接调用(可做二次处理)
import whisper
model = whisper.load_model("base")
result = model.transcribe("/path/to/audio.ogg", language="zh")
print(result["text"])
- 这样可以拿到
result["segments"]做逐句时间轴、翻译、摘要等后续处理。 - 如果只有 CPU,会看到
FP16 is not supported on CPU; using FP32 instead的提示,属于正常现象。
五、语音交互流程建议
- 来音频 → 先用上面的 CLI 或 Python 脚本转文字。
- 文字处理:按照需求整理、翻译、摘要、提取 TODO 等。
- 回语音(可选):如果要“我说话给你听”,可以把生成的文本丢给 TTS(如
tts工具或外部服务)转回音频,再发给对方。。
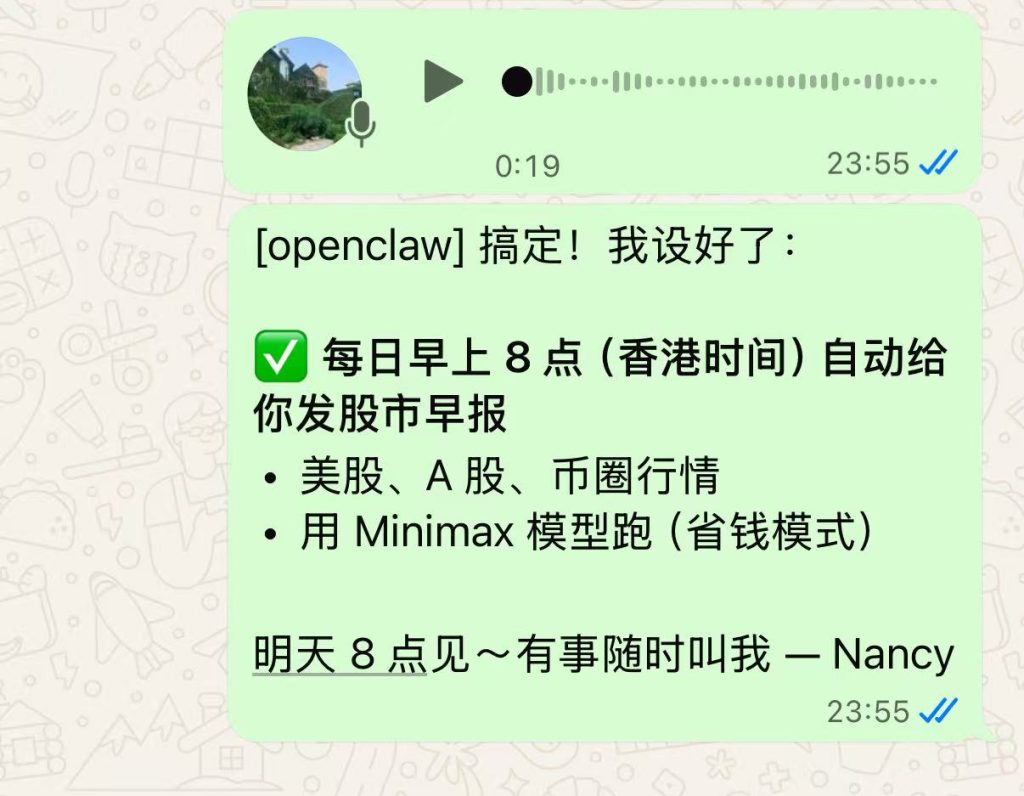
l六、测试语言交互
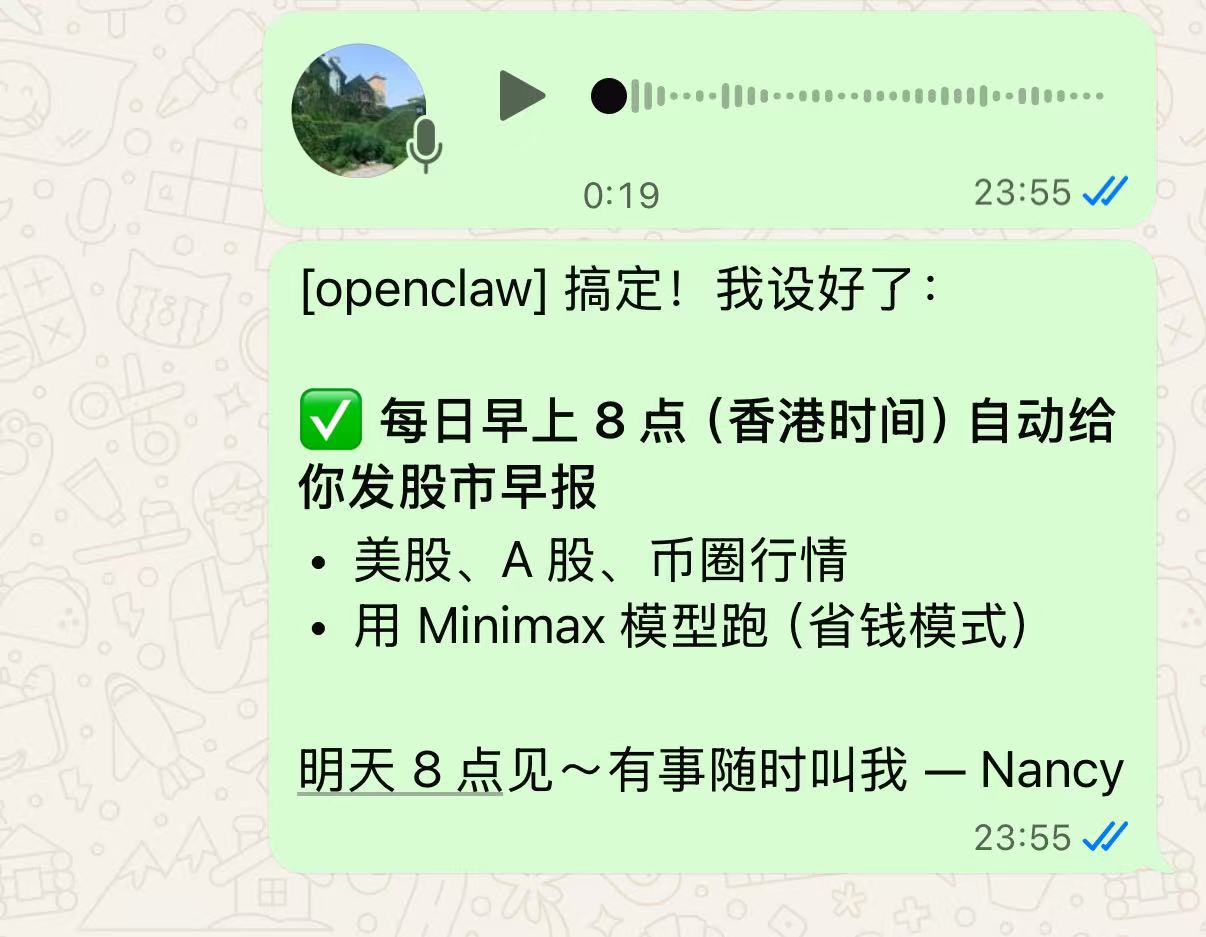
正文到此结束
热门推荐









相关文章

近期评论
-
出现OpenClaw "device signature expired"。the Gateway rejects if Math.abs(Date.now() - signedAt) > 10 * 60 * 1000 (10 minutes)
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
博主的博客用的什么技术栈,内容都是干货,赞
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

