JAVA并发编程与实践
概述
并发是操作系统的特征,主要包括进程和线程。进程是通常彼此独立运行的程序的实例,比如,如果你启动了一个Java程序,操作系统产生一个新的进程,与其他程序一起并行执行。在这些进程的内部,我们使用线程并发执行代码,这样可以最大限度的利用CPU可用的核心(core)。
JDK自1.5版本之后,提供了专门支持并发程序的concurrent包,并在后面的版本中不断地扩展、增强,为JAVA的并发编程注入了很大的活力。但是很多普通开发人员对它望而生畏,不敢用于实践,使得自己的应用程序不够灵活、高效。
由于concurrent包内容众多,需要很大篇幅才能完整介绍,本文主要考虑从最为常用的线程池、阻塞队列、并行处理框架三块来介绍一下我们在日常开发实践中如何去使用。
线程池
在concurrent包中,线程池是比重最大的功能特性,它提供了不同适用场景、灵活配置、可扩展的线程池实现。本文不再赘述线程池产生的背景、以及其带来的好处。
线程池结构
线程池的顶级接口是e x e cutor,但是严格意义上讲e x e cutor并不是一个线程池,而只是一个执行线程的工具。真正的线程池接口是e x e cutorService。下面是JDK线程池相关的类结构图:
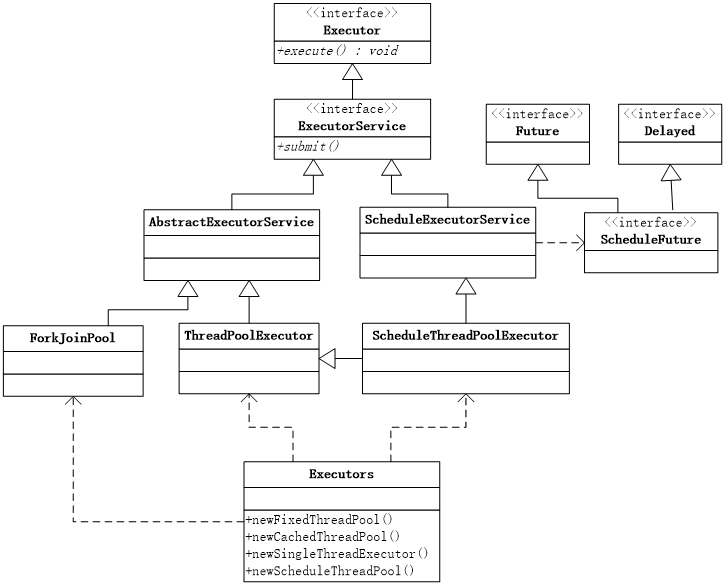
JDK提供了很多类型的线程池,适用于程序中不同的应用场景,主要有以下4类:
| 方法名 |
描述 |
适用场景 |
| FixedThreadPool |
创建一个自定义工作线程数的线程池 |
如果系统中需要创建的线程数量比较明确时 |
| CachedThreadPool |
创建一个可缓存的线程池 |
如果系统中需要创建的线程数较多,且数量不可预知时 |
| SingleThreade x e cutor |
创建一个单线程的线程池 |
如果系统中某项任务需要异步执行,且保证有序时 |
| ScheduleThreadPool |
创建一个支持任务调度的线程池 |
如果某类任务需要定时执行、或延时执行时 |
补充说明:
1) FixedThreadPool、CachedThreadPool、SingleThreade x e cutor都是ThreadPoole x e cutor的实例;
2) FixedThreadPool与CachedThreadPool主要的区别,就是后者会在任务空闲时,主动释放线程,进而节省内存资源,但是一旦有新的任务,线程就会重新创建,又会产生一定的开销。所以使用时需要结合任务空闲情况来选择。
3) Jdk1.7中,还提供了一种新的线程池ForkJoinPool,它会根据当前CPU数量创建足够多的线程,并通过多个任务队列进行分治执行,本文后续章节会有描述。
线程池使用
e x e cutors
线程池的主要作用是创建和管理一批线程,异步执行任务。通过e x e cutors可以创建各种不同的线程池,并执行任务,代码示例如下:
e x e cutorService e x e cutor = e x e cutors.newSingleThreade x e cutor(); //其他类型的线程池均有对应方法
e x e cutor.e x e cute(new Runnable(){
@Override
public void run() {
String threadName = Thread.currentThread().getName();
s y s t e m.out.println("Hello " + threadName);
}
});
这段代码先通过e x e cutors创建了一个SingleThreade x e cutor的线程池,然后用该线程池执行了一个任务。
在执行这段代码时,你会注意到一个现象:Java进程从没有停止。这就是线程池的一个显著特征,它会持续存在,并监听新的任务。
当然,JDK肯定会提供方法来关闭线程池,一个是shutdwon(),它会等到任务执行完毕后关闭;一个是shutdownNow(),它会终止所有正在执行的任务并立即关闭。
Callable和Future
除了能够执行Runnable的任务,线程池还可以执行另一种任务类型Callable,其不同之处在于,Callable可以有返回值,代码示例如下:
e x e cutorService e x e cutor = e x e cutors.newSingleThreade x e cutor();
Future<Integer> future = e x e cutor.submit(new Callable<Integer>(){
@Override
public Integer call() throws InterruptedException {
TimeUnit.SECONDS.sleep(10);
return 123;
}
});
Integer result = future.get();
s y s t e m.out.println(result);
e x e cutor. shutdwon(); //关闭线程池
线程池的submit方法,不会直接得到任务的返回值,而是返回一个Future对象,通过Future的get()方法,即可得到任务的返回值。
注意:
l 上述示例中,执行future.get()语句时当前线程会阻塞等待,直到callable在返回实际的结果123时执行完成。
l 可以通过future.done()方法来判断执行的任务是否完成。
invokeAll和invokeAny
线程池支持通过invokeAll()可以一次批量提交多个callable。这个方法传入一个callable的集合,然后返回一个future的列表。该方法会阻塞直到所有callable执行完成,示例代码如下:
e x e cutorService e x e cutor = e x e cutors.newSingleThreade x e cutor();
List<Callable<Integer>> callables = Arrays.asList(
new Callable<Integer>(){
@Override
public Integer call() throws InterruptedException {
TimeUnit.SECONDS.sleep(10);
return 1;
}
},
new Callable<Integer>(){
@Override
public Integer call() throws InterruptedException {
TimeUnit.SECONDS.sleep(15);
return 2;
}
}
);
List<Future<Integer>> futures = e x e cutor.invokeAll(callables);
Integer result = 0;
for(Future<Integer> future : futures){
result += future.get();
}
s y s t e m.out.println(result);
上述程序运行后,会在15秒以后打印结果为3
与invokeAll相对应的,线程池还提供了一个invokeAny()方法,该方法将会阻塞直到第一个callable完成然后返回这一个callable的结果。示例代码如下:
e x e cutorService e x e cutor = e x e cutors.newSingleThreade x e cutor();
List<Callable<Integer>> callables = Arrays.asList(
new Callable<Integer>(){
@Override
public Integer call() throws InterruptedException {
TimeUnit.SECONDS.sleep(10);
return 1;
}
},
new Callable<Integer>(){
@Override
public Integer call() throws InterruptedException {
TimeUnit.SECONDS.sleep(15);
return 2;
}
}
);
Integer = e x e cutor.invokeAny(callables);
s y s t e m.out.println(result);
上述程序运行后,会在10秒以后打印结果为1
Schedulede x e cutorService
Schedulede x e cutorService是任务调度类线程池接口,即上文提到的ScheduleThreadPool类线程池,它支持对任务进行定时、持续执行,应用程序借其可以实现简单的定时处理逻辑。
下面这个示例代码,会实现一个任务延迟3秒钟执行:
Schedulede x e cutorService e x e cutor = e x e cutors.newScheduledThreadPool(1);
e x e cutor.schedule(new Runnable(){
@Override
public void run() {
String threadName = Thread.currentThread().getName();
s y s t e m.out.println("Hello " + threadName);
}
}, 5, TimeUnit.SECONDS);
如果要实现持续执行,线程池提供了两种方法:
1) scheduleAtFixedRate()
该方法有4个参数:
Runnable command //要执行的任务
long initialDelay //第一次执行的延迟时间
long period //每隔多少时间循环执行
TimeUnit unit //时间单位
2) scheduleWithFixedDelay()
该方法的参数和scheduleAtFixedRate一致,但是区别在于period参数:
l scheduleAtFixedRate的间隔时间是从上一次任务开始时点算起,它不会考虑任务的执行时长,也就是会存在执行时长大于间隔时间的情况
l scheduleWithFixedDelay的间隔时间是从上一次任务完成时点算起,即上一次任务完成后,经过间隔时间后再执行下一次任务。
下面是scheduleWithFixedDelay方法的示例代码,在上一次任务完成后5秒,会执行下一次任务:
Schedulede x e cutorService e x e cutor = e x e cutors.newScheduledThreadPool(1);
ScheduledFuture<?> future = e x e cutor.scheduleWithFixedDelay(new Runnable(){
@Override
public void run() {
s y s t e m.out.println("begin in "+s y s t e m.currentTimeMillis());
try {
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {}
s y s t e m.out.println("end in "+s y s t e m.currentTimeMillis());
}
},0l, 5l, TimeUnit.SECONDS);
阻塞队列
阻塞队列(BlockingQueue)是一个支持两个附加操作的队列。这两个附加的操作是:在队列为空时,获取元素的线程会等待队列变为非空;当队列满时,存储元素的线程会等待队列可用。阻塞队列常用于生产者和消费者的应用场景。
队列操作
阻塞队列的操作,主要有3类:插入、取出、检查。在JDK中,队列的这3类操作具有不同形式的实现,主要是基于插入时队列满、取出时队列空的场景而定,归纳如下:
| 队列操作 |
抛出异常式 |
实时返回式 |
阻塞式 |
超时退出式 |
| 插入 |
add(e) |
offer(e) |
put(e) |
offer(e,time,unit) |
| 取出 |
remove() |
pull() |
take() |
poll(time,unit) |
| 检查 |
无 |
peek() |
无 |
无 |
l 抛出异常式:当插入时队列满、取出时队列空,直接抛出异常
l 实时返回式:当插入成功时,返回true,否则返回false,取出失败则返回null
l 阻塞式:当插入时队列满、取出时队列空,方法会阻塞,直到成功
l 超时退出式:当插入时队列满、取出时队列空,方法会阻塞,但是达到超时时间后,会按照实时返回式进行返回。
队列种类
JDK提供了7个阻塞队列实现,分别是:
l ArrayBlockingQueue:由数组结构组成的有界阻塞队列
l LinkedBlockingQueue:由链表结构组成的有界阻塞队列
l PriorityBlockingQueue:支持优先级排序的无界阻塞队列
l DelayQueue:支持延时获取元素的无界阻塞队列
l SynchronousQueue:不存储元素的阻塞队列
l LinkedTransferQueue:由链表结构组成的无界阻塞队列
l LinkedBlockingDeque:由链表结构组成的双向阻塞队列
本文后续会介绍几个比较常用的阻塞队列。
队列的使用
阻塞队列可以解决应用程序中很多业务场景,其中最典型的是生产者消费者模式,特别是当生产者生产数据的速度与消费者处理数据的速度不一致时,适合使用阻塞队列。
使用阻塞队列,还可以简化很多同步锁、线程间通信的代码处理,能够避免程序出现意外的错误。
典型示例
下面是一个队列使用的典型示例程序,它要实现的场景描述如下:
1) 一个生产者,负责按固定次数往有界队列里存放数据
2) 一个消费者,负责从队列里获取数据,做有一定耗时的处理
3) 直到生产者处理完毕,消费者将所有数据处理完毕后结束
ArrayBlockingQueue<Integer> queue = new ArrayBlockingQueue<Integer>(10);
e x e cutorService e x e cutor = e x e cutors.newCachedThreadPool();
//生产者线程,做20次队列插入
e x e cutor.submit(new Runnable() {
@Override
public void run() {
for(int i=1;i<=20;i++){
try {
queue.put(i); //如果队列已满,阻塞直到成功
} catch (InterruptedException e) {}
s y s t e m.out.println("插入成功,当前队列数量:"+queue.size());
}
}
});
//消费者线程,循环从队列取出数据
e x e cutor.submit(new Runnable() {
@Override
public void run() {
while(true){
try {
TimeUnit.SECONDS.sleep(1); //模拟耗时
} catch (InterruptedException e) {}
try {
Integer take = queue.take();
s y s t e m.out.println("从列表获取元素:"+take);
s y s t e m.out.println("队列剩余数量:"+queue.size());
if(queue.size() == 0){
break;
}
} catch (InterruptedException e) {}
}
}
});
e x e cutor.shutdown();
执行示例程序,可以从打印结果中发现,当插入数据的线程插入时队列已满,就会阻塞,直到处理线程处理完一条数据,就进行了下一条插入。
LinkedBlockingQueue
LinkedBlockingQueue和 ArrayBlockingQueue在使用和特性上基本没有太大区别,只是内部结构不一样,前者采用的是链表的数据结构,在创建时,可以不需要指定容量大小(默认为Integer.MAX_VALUE),但是使用时尽量还是指定大小,否则会有内存耗尽的风险。
DelayQueue
DelayQueue是一个支持延时获取元素的无界阻塞队列,队列中的元素必须实现Delayed接口,在创建元素时可以指定多久才能从队列中获取当前元素。DelayQueue也是比较常用的阻塞队列,比如以下两个使用场景:
1) 可以用DelayQueue保存一些具备有效期的数据,使用一个线程循环pull该DelayQueue,一旦pull成功,表示该数据已经到了有效期。
2) 可以将一些延时执行的任务放入DelayQueue,一旦从DelayQueue中获取到任务就开始执行,swing框架的TimerQueue就是使用DelayQueue实现的。
DelayQueue的元素,需要实现compareTo方法,用于指定元素的存放顺序,比如让有效期较长的数据放到队列末尾。
并行计算框架
并行计算是项目开发时,非常常用的处理方式,主要解决对大量数据计算的性能需求。在大数据技术中的MR技术也是非常典型的并行计算框架。
Fork/Join
在上文中的线程池章节,通过线程池的invokeAll方法,可以实现对多个线程并行执行,然后阻塞等待所有处理结果,这种思路其实也是一种简单的并行计算方式。
但是这种写法比较繁琐,JDK1.7提供一种专门用于并行计算的框架,即Fork/Join框架。从字面理解,Fork/Join框架需要做两件事:
l fork就是一个大任务切分为若干子任务并行的执行
l Join就是合并这些子任务的执行结果,最后得到这个大任务的结果。
Fork/Join框架的核心是上文提到的一种线程池ForkJoinPool,这个线程池只能用来处理ForkJoinTask类型的任务,该任务有两种实现:
l RecursiveAction:用于没有返回结果的任务
l RecursiveTask:用于有返回结果的任务
典型示例
下面是一个使用Fork/Join框架来实现两个整数间累加运算的示例代码,它会将累加因子按每10个拆分子任务。
static class ComputeTask extends RecursiveTask<Integer>{
final Integer SHOLD = 10;
private Integer begin;
private Integer end;
public ComputeTask(Integer begin,Integer end){
this.begin = begin;
this.end = end;
}
private Integer sum(){
Integer sum = 0;
for(Integer i=begin;i<=end;i++){
sum +=i;
}
return sum;
}
@Override
protected Integer compute() {
//如果数量小于阈值,直接计算
if(end - begin <= SHOLD){
return sum();
}
//否则拆分成2个
ComputeTask leftTask = new ComputeTask(begin, begin+SHOLD-1);
ComputeTask rightTask = new ComputeTask(begin+SHOLD, end);
leftTask.fork();
rightTask.fork();
Integer sum = 0;
sum += leftTask.join();
sum += rightTask.join();
return sum;
}
}
public static void main(String[] args) throws InterruptedException, e x e cutionException {
//使用e x e cutors来创建ForkJoinPool
ForkJoinPool forkJoinPool = (ForkJoinPool)e x e cutors.newWorkStealingPool();
Future<Integer> result =forkJoinPool.submit(new ComputeTask(1, 100));
s y s t e m.out.println(result.get());
}
根据这个示例,我们做出总结:ForkJoinTask与一般的任务的主要区别在于它需要实现compute方法,在这个方法里,首先需要判断任务是否足够小,如果足够小就直接执行任务。如果不足够小,就必须分割成两个子任务,每个子任务在调用fork方法时,又会进入compute方法,看看当前子任务是否需要继续分割成孙任务,如果不需要继续分割,则执行当前子任务并返回结果,它是一种典型的递归调用。使用join方法会等待子任务执行完并得到其结果。
CountDownLatch
如果我们不借助Fork/Join来实现并行计算,甚至我们也不想使用线程池来实现阻塞等待多线程处理结果,JDK提供了一个非常好用的工具,来解决并行处理的线程间通信问题。
CountDownLatch在使用场景上有两种用法:
1) 在一个主线程中,启动多个子线程,主线程等所有子线程处理结束后才能继续执行
2) 在一个主线程中,启动多个子线程,但是这些子线程初始是阻塞的,需要等到某个业务处理完后,唤醒这些子线程。
对于第一种场景,其效果与线程池的invokeAll()基本一致,这里不再赘述。
下面的示例程序,实现了第二种使用场景,通过一个唤醒线程,来触发子线程执行
static class SubThread implements Runnable{
private CountDownLatch cdl;
private int sort;
public SubThread(int sort,CountDownLatch cdl){
this.cdl = cdl;
this.sort = sort;
}
@Override
public void run() {
try {
cdl.await(); //一开始就挂起
} catch (InterruptedException e) {
}
s y s t e m.out.println("线程"+sort+"被唤醒!");
}
}
public static void main(String[] args){
CountDownLatch cdl = new CountDownLatch(1);
e x e cutorService e x e cutor = e x e cutors.newCachedThreadPool();
//启动5个子线程
for(int i =0 ;i<5;i++){
e x e cutor.submit(new SubThread(i,cdl));
}
//启动一个线程去做唤醒
e x e cutor.submit(new Runnable() {
@Override
public void run() {
s y s t e m.out.println("我是唤醒线程,3秒后开始唤醒他们");
try {
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
cdl.countDown(); //唤醒
}
});
}
该示例代码执行后,打印结果如下:
我是唤醒线程,3秒后开始唤醒他们
-----------经历了3秒-----------
线程0被唤醒!
线程1被唤醒!
线程2被唤醒!
线程4被唤醒!
线程3被唤醒!
结语
并发编程的核心宗旨,总结起来主要有两点:
1) 充分利用CPU等系统资源,为业务提速
2) 解决并发过程中的资源竞争、线程通信调度
尽管我们在做业务系统开发时大部分都是跟数据库打交道,但是并发编程是解决很多功能、性能需求不可或缺的手段;笔者通过多年的编码实践,总结了一些我们日常开发中,值得使用并发编程的业务需求场景:
1) 数据量较大的计算场景,可以使用并行处理方案来提升效率
2) 类似生产者消费者的业务场景中,可以使用阻塞队列来实现
3) 需要对业务进行异步处理时,使用线程池代替Thread.start()
4) 业务逻辑需要延时处理、循环处理时,可以使用调度线程池来实现
编写优质的并发代码是非常难的事情,它往往会增加程序的复杂度,出现一些难以预测和调试的缺陷。所以我们使用时,需要做好充分的学习,了解了这些并发处理类的特性,编码时考虑周全、化繁为简,才能真正的体现价值。
正文到此结束
热门推荐










相关文章

近期评论
-
主要用的是AI
-
博主的博客用的什么技术栈,内容都是干货,赞
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
-
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

