从线程池理论聊聊为什么要看源码
很多时候,我都想向大家传输一个思想,那就是只有懂了原理,才能随心随心所欲写代码.而看源码,又是了解原理的一个非常重要的途径.
然而,肥朝之前的文章,大致分为三类
-
源码解析,穿插怎么看源码(参考肥朝Dubbo源码解析系列文章)
-
怎么临摹一个一比一的源码(参考肥朝 dubbo源码解析-简单原理、与spring融合 、 一比一手写Dubbo源码中的SPI,内附git地址
-
看了源码,究竟解决了什么问题(参考肥朝[还有这种操作?浅析为什么要看源码])
第三点,我认为尤其重要.我们看源码的目的是为了解决问题,我觉得只谈付出,不谈回报都是耍流氓.如果只告诉大家要懂原理,看源码,接着贴几大段源码,然后给大片大片的源码打上注释.看了大段大段的注释下来,好像都懂了,感觉很"充实".
但是我们要的并不是这种自我感觉的"充实",而是真真正正通过源码,解决了** 搜索无法解决的问题 **,只有这样.才是有收获的.如果百度随便一搜都有答案的那你还舍近求远的看源码这就实在是装逼了
直入主题
今天在公司压测的性能群,出现了这么一个问题,如下图:

粗略一看,大概Dubbo线程池达到最大线程数抛出的异常.那么我们先来铺垫线程池的知识基本储备
常见线程池
-
SingleThreadExecutor: 单线程线程池,一般很少使用. -
FixedThreadExecutor: 固定数量线程池,这个比较常用,重点留意一下,也是本文重点 -
CachedThreadExecutor: 字面翻译缓存线程池,这个也比较常用,重点留意一下,也是本文重点 -
ScheduledThreadExecutor: 定时调度线程池,一般很少使用.那这里可能就有人反驳了.那为什么Dubbo源码里面的定时任务要用这个?看源码最重要的还是要看出别人的设计思想.Dubbo设计的初衷是只依赖JDK,使用他的定时任务,自然是优先选择使用这个JDK原生的API来做一个简易的定时任务.
线程池参数的意义及工作原理
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
//...
}
复制代码
线程池有这么几个重要的参数
corePoolSize : 线程池里的核心线程数量
maximumPoolSize : 线程池里允许有的最大线程数量
keepAliveTime : 如果 当前线程数量 > corePoolSize ,多出来的线程会在 keepAliveTime 之后就被释放掉
unit : keepAliveTime的时间单位,比如分钟,小时等
workQueue : 队列
threadFactory : 每当需要创建新的线程放入线程池的时候,就是通过这个线程工厂来创建的
handler : 就是说当线程,队列都满了,之后采取的策略,比如抛出异常等策略
那么我们假设来一组参数练习一下这个参数的意义
corePoolSize:1 mamximumPoolSize:3 keepAliveTime:60s workQueue:ArrayBlockingQueue,有界阻塞队列,队列大小是4 handler:默认的策略,抛出来一个ThreadPoolRejectException 复制代码
1.一开始有一个线程变量poolSize维护当前线程数量.此时poolSize=0
2.此时来了一个任务.需要创建线程. poolSize(0) < corePoolSize(1) ,那么直接创建线程
3.此时来了一个任务.需要创建线程. poolSize(1) >= corePoolSize(1) ,此时队列没满,那么就丢到队列中去
4.如果队列也满了,但是 poolSize < mamximumPoolSize ,那么继续创建线程
5.如果 poolSize == maximumPoolSize ,那么此时再提交一个一个任务,就要执行 handler ,默认就是抛出异常
6.此时线程池有3个线程(poolSize == maximumPoolSize(3)),假如都处于空闲状态,但是 corePoolSize=1 ,那么就有(3-1 =2),那么这超出的2个空闲线程,空闲超过60s,就会给回收掉.
以上,就是线程池参数意义及工作原理
线程池参数设计上的思考
知道了以上的原理,那么我们看看常见的两个线程池 FixedThreadExecutor 和 CachedThreadExecutor 的参数设计
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
复制代码
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
复制代码
那么问题来了
1.为什么 FixedThreadExecutor 的 corePoolSize 和 mamximumPoolSize 要设计成一样的?
2.为什么 CachedThreadExecutor 的 mamximumPoolSize 要设计成接近无限大的?
敲黑板划重点
还是前面那句话,我们看源码,并不是大段大段的源码打上注释,最重要的是经过深度思考,明白作者设计的意图,这也就是为什么市场上有这么多源码解析文章,我们依然还要关注一下肥朝(卖个萌)
如果你对上面的线程池的原理,参数有了清晰的认识,自然很快就能明白这个设计思路.
比如问题一,因为线程池是先判断 corePoolSize ,再判断 workQueue ,最后判断 mamximumPoolSize ,然而 LinkedBlockingQueue 是无界队列,所以他是达不到判断 mamximumPoolSize 这一步的,所以 mamximumPoolSize 成多少,并没有多大所谓
比如问题二:我们来看看 SynchronousQueue 的注释:
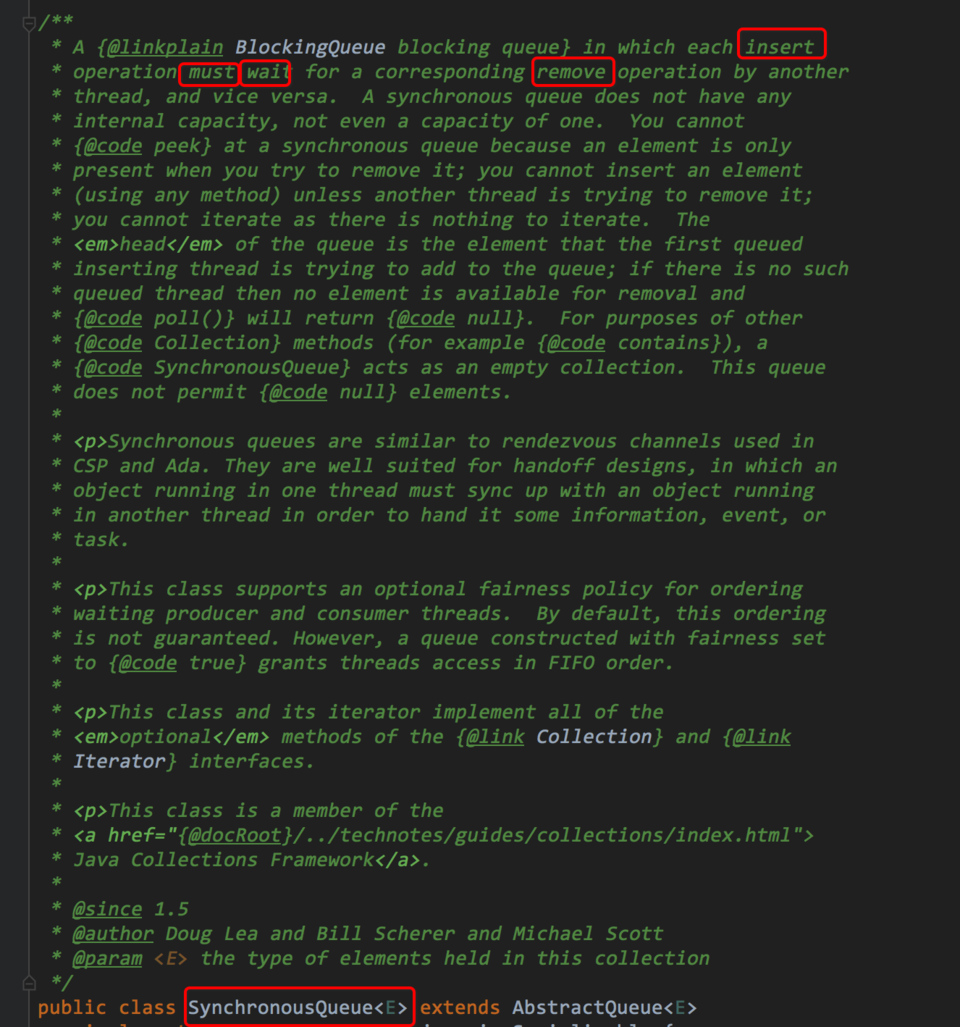
从我圈的这几个小学英文单词都知道,这个队列的容量是很小的,如果 mamximumPoolSize 不设计得很大,那么就很容易动不动就抛出异常
线程池使用上的建议
原理明白了,设计思想我们也明白了,代码要怎么写.光理论还不行,也就是说,我们在项目中,线程池究竟要怎么用?那么我们来看一下阿里手册,看到这个 强制 相信不用我多说什么

Dubbo线程池
那么我们来看看Dubbo官方文档,一直强调,官方文档才是最好的学习资料.

回归问题
那么回到我们前面遇到的问题.我们看了官方文档说Dubbo默认(缺省)用线程池是 fixed ,那么我们第一反应,从前面各种分析原理也得知了, FixedThreadPool 的队列是很大的,他根本达不到第三个判断条件 mamximumPoolSize ,达不到第三个条件,也就不会触发 handle 抛出异常.那前面那个压测问题的异常怎么来的,难道肥朝上面的分析都是骗人的?肥朝也是大猪蹄子???

直入源码
这种问题.搜索是不好使了,因为根本不好搜索.那么我们只好直入源码了
@SPI("fixed")
public interface ThreadPool {
/**
* 线程池
*
* @param url 线程参数
* @return 线程池
*/
@Adaptive({Constants.THREADPOOL_KEY})
Executor getExecutor(URL url);
}
复制代码
public class FixedThreadPool implements ThreadPool {
public Executor getExecutor(URL url) {
String name = url.getParameter(Constants.THREAD_NAME_KEY, Constants.DEFAULT_THREAD_NAME);
int threads = url.getParameter(Constants.THREADS_KEY, Constants.DEFAULT_THREADS);
int queues = url.getParameter(Constants.QUEUES_KEY, Constants.DEFAULT_QUEUES);
return new ThreadPoolExecutor(threads, threads, 0, TimeUnit.MILLISECONDS,
queues == 0 ? new SynchronousQueue<Runnable>() :
(queues < 0 ? new LinkedBlockingQueue<Runnable>()
: new LinkedBlockingQueue<Runnable>(queues)),
new NamedThreadFactory(name, true), new AbortPolicyWithReport(name, url));
}
}
复制代码
此时我们发现,Dubbo里面的 FixedThreadPool 和 newFixedThreadPool 创建出来的 FixedThreadPool 参数是不一样的.默认情况下,Dubbo的 FixedThreadPool 中, maximumPoolSize = 200 ,队列是容量很小的 SynchronousQueue .所以当线程超过200的时候,就会抛出异常.这个和我们上面分析的原理是一致的.
其实换个角度想,规范手册都是阿里出的,阿里手册都强制说要用 ThreadPoolExecutor 的方式来创建了,而且还给你分析了无界队列的风险,那么Dubbo官方文档说的 fixed 又怎么会是 Executors 创建的无界队列这种呢?
知道了线程池的原理和异常的根源之后,我们完全可以根据业务特点的不同,自定义线程池参数,来避免这类异常的频繁发生.亦或者改变Dubbo默认的线程模型,从 aLL 改成 message 等,这个就要结合实际的业务情况了.(这两个方案后面有时间会把公司的真实案例抽象成简单模型和大家分享)
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

