【译】给小白准备的Web架构基础知识
警告:本文内容是入门级的,大佬请按秩序有序撤离。
原文地址:Web Architecture 101
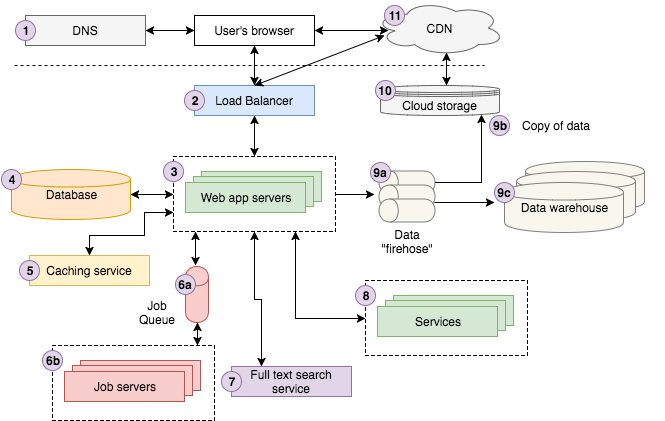
上图很好的展示了我们在Storyblocks的架构。如果你是一个新手工程师,可能会觉得这个架构非常复杂。在我们深入研究每个组件的细节之前,首先应该对它们有个大概的了解。
当一个用户在Google搜索“ Strong Beautiful Fog And Sunbeams In The Forest ”时,第一条结果来自 Storyblocks ,我们主要的照片网站。用户点击结果就会在浏览器中跳转到图片详情页。在引擎下,用户的浏览器想DNS服务器发送一个请求,查询如何连接 Storyblocks ,然后向 Storyblocks 发送请求。
请求会先到达我们的负载均衡器,负载均衡器会随机选择一个正在运行的服务器来处理请求。服务器先从缓存中查找一部分关于图片的信息,并从数据库查找剩余信息。我们注意到此时还没有对图片的颜色进行配置,因此我们发送“ color profile ”任务到我们的任务队列,处理任务的服务器会异步执行队列中的任务,并且将结果适时更新到数据库中。
接下来,我们试图从使用照片标题在全文检索服务中找到与输入的照片相似的照片。如果登录用户是 Storyblocks 的会员,我们会去账号服务中查找用户的相关信息。最后,我们会把页面访问数据发送到数据“ firehose ”,以便存储到我们的云存储系统上,并最终落地到数据仓库中。数据分析师会使用数据仓库中的数据来解决商业问题。
到这里,服务器已经呈现了一个HTML页面,并通过负载均衡器将它返回给用户。页面包含的JavaScript和CSS会放到连接了CDN的云存储系统中,所以用户的浏览器连接CDN取回数据。最后,由浏览器给用户呈现完整的页面。
接下来,我会对每个组件挨个进行简单的介绍,以求给你建立一个良好的关于学习架构的思维模型。我会在另外一个系列的文章中分享我在Storyblocks这段时间的实践经验,给你提供良好的建议。
1. DNS
DNS是“Domain Name System”的缩写,它是使万维网成为可能的核心技术。最基础的DNS提供了域名(例如google.com)和IP地址的(例如85.129.83.120)的键值对以供查找,这是计算机路由请求到指定服务器所必需的。类别电话号码,域名和IP地址的区别就像是“打给哲少”和“拨打201-867–5309”。就像过去你需要一个电话本来查找哲少的电话号码,如今你需要DNS服务器来查找域名对应的IP地址。所以你可以认为DNS就是互联网上的电话本。
关于DNS的细节我们还可以展开讲很多,但这里我们略过,因为这不是入门级介绍所关心的。
2. Load Balancer
在介绍负载均衡器之前,我们先来讨论一下应用的水平和垂直扩展。它们有什么不同呢?这篇帖子介绍的很明白,水平扩展是通过向资源池中增加更多的机器,垂直扩展是在已有的机器中增加更高的配置(CPU、内存等)。
在Web开发中,为了应对服务器宕机,网络波动,数据中心不可用等突发情况,你一定经常使用横向扩展,因为它既简单又快捷。拥有一台以上的服务器使你的应用程序在部分服务器掉电时仍然可以正常运行。换句话说,你的程序具有较好的容错性。其次,横向扩展允许你通过让每个部分运行在不同的服务器上来解耦后端的依赖(Web服务器、数据库、服务 X等)。最后,当你的服务器达到一定规模时可能无法再进行垂直扩展。因为这个世界上没有任何一台计算机的性能好到可以支撑你所有应用的计算。举一个典型的栗子——Google的搜索平台。当然一原则对于多数规模较小的公司也适用,例如Storyblocks就部署了150到400个AWS EC2实例。对于这样的情况,要想通过垂直扩展来提供全部计算是一项艰难的挑战。
我们再说回负载均衡器,它们使水平扩展成为可能。它们将传入进来的请求路由到众多服务器中的一个,并将响应结果返回给客户端。这些服务器通常是彼此的克隆或镜像,它们中的任何一个都应该以相同的方式处理,这样就通过分发请求的方式解决避免某台机器出现过载问题。
负载均衡的概念非常简单,但是实现起来非常复杂。我们暂且不介绍。
3. Web Application Servers
在上层的Web应用服务描述起来非常简单。它们用来执行主要的业务逻辑,处理用户请求,并将HTML返回到用户的浏览器。为了完成任务,它们通常要与各种后端基础组件交互,比如数据库、缓存、任务队列、检索服务、其他微服务、数据/日志队列等等。如上所述,为了处理用户请求,你至少有两个,通常更多的负载均衡器。
你应该知道应用服务的实现需要选择一种语言(Node.js、Ruby、PHP、 Scala、 Java、 C# 、.NET等)和对应MVC框架(Node.js的Express,Ruby的Rails,Scala的Play,PHP的Laravel等)。然而深挖这些语言和框架的细节也超出了本文的讨论范围。
4. Database Servers
每个Web应用项目都利用一个或多个数据库来存储信息。数据库提供了定义数据结构、对数据的增删改查、跨数据计算的方法。多数情况下,Web应用服务器和任务队列直接通信。另外每个后端服务可能都拥有独立的数据库。
虽然我一直强调本文不会介绍某个组件的细节,但是如果不提SQL和NOSQL也是一种不负责任的行为。
SQL的全称是“结构化查询语言”,它在18世纪70年代被发明。它给大家提供了查询关系型数据集的标准方法。SQL数据库将数据存储在通过公共ID(通常是整数)连接在一起的表中。让我们来看一个存储用户历史地址信息的例子。你可能需要两张表,用户表和用户地址表,它们通过用户ID连接在一起。下图展示了一个简化版本。两个表通过外键连接。
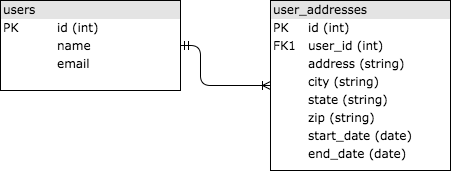
如果你不是很了解SQL,我强烈推荐你学习一下Khan Academy的一门课程。SQL现在已经非常普及了,因此你至少要了解一些基础知识才能构建你的应用程序。
NoSQL代表“非SQL”,是一种新的数据库技术集,用于处理大规模Web应用产生的大量数据(大多数SQL不支持水平扩展,并且垂直扩展也只能扩展到某个点)。如果你不了解NoSQL,可以看下面这些介绍:
- www.w3resource.com/mongodb/nos…
- www.kdnuggets.com/2016/07/sev…
- resources.mongodb.com/getting-sta…
但是总的来说,业界还是要将 SQL作为数据库的统一接口 ,即使是对菲关系型数据库,所以如果你还不了解SQL的话,就真的要赶快去学习一下了。
5. Caching Service
缓存服务提供了简单的kv存储数据,尽可能使保存和查找数据的时间复杂度接近O(1)。应用程序一般把计算比较复杂的结果保存到缓存服务中,以便再次取值时直接从缓存中读取而不用重新进行复杂的计算。应用可能缓存的信息包括,数据库查询的结果,调用外部服务的返回值,一个URL返回的HTML等等。下面是一些实际的例子:
- Google会将搜索结果缓存
- Facebook在你登录后会缓存你看到的大部分信息,比如帖子、好友等。关于Facebook的缓存技术缓存可以看这篇文章
- Storyblocks缓存来自服务器端React渲染,搜索结果和预输入结果等的HTML输出。
目前应用最广泛的两种缓存服务是Redis和Memcache。我会在另一篇文章中对它们进行更深入的介绍。
6. Job Queue & Servers
很多应用程序需要在后台异步处理一些和返回结果无关的逻辑。比如,Google为了提供搜索服务,需要爬取网页并进行索引。它并不是在你每次搜索的时候都去做这件事,而是异步爬取,并更新索引。
虽然现在有很多不同的架构都支持异步操作,但最普及的是我所说的“任务队列”架构。它包含两个组件:一个任务队列和至少一个任务服务器来执行队列中的任务。
任务队列通常保存一系列需要异步执行的任务。最简单的规则是先进先出(FIFO),大多数应用按照优先级给任务排序。当应用需要执行一个任务时,无论是定时任务还是用户操作,都会把任务放到队列中去。
还拿Storyblocks举例,我们使用一个后台的任务队列为我们的市场提供支持。我们会跑一些视频图片解码,处理CSV元数据标记,汇总用户统计信息,发送重置密码邮件等任务。我们一开始采用FIFO的原则,后来改为优先级队列,以保证有些具有时效性的任务能尽快完成,比如发送重置密码邮件。
任务服务器用来处理任务。它们轮询任务队列以确定是否有任务要执行以及是否有任务,如果有,就从任务队列中弹出一个任务来执行。底层语言和框架的选择非常多,但它们不在本文讨论范围。
7. Full-text Search Service
许多web应用支持某种搜索功能——用户输入文本,应用返回“相关”的结果。支撑这种功能的技术一般称为全文检索,它利用反向索引快速找到包含关键字的文档。

现在某些数据库也支持检索功能(比如 MySQL已经支持全文检索 ),通常是运行独立的搜索服务来计算和存储反向索引,并提供查询接口。目前最受欢迎的全文检索平台是Elasticsearch,另外还有一些其他比较好的平台 例如Sphinx和 Apache Solr 。
8. Services
一旦一个APP达到一定的规模,就会有某些服务被独立出来运行。它们不会对外暴露,但是可以和应用内部的服务之间交互。Storyblocks有几个运营和计划的服务:
- Account service 存储我们所有网站上的用户数据,这使我们可以更轻松的提供交叉销售机会并创建更统一的用户体验
- Content service 存储我们所有的视频、音频和图片的元数据。也提供了下载接口和查看历史下载记录的接口。
- Payment service 提供对用户信用卡进行计费的接口
- HTML → PDF service 提供了一个简单的HTML转PDF的接口
9. Data
当下,一家公司的生死由他们驾驭数据的能力决定。如今几乎每个APP一旦达到一定规模,就需要通过数据管道来收集、存储和分析数据。典型的管道有三个步骤:
- APP发送数据,典型的关于用户交互的事件,数据发送到“firehose”——提供获取和处理数据的接口。原始数据通常需要进行转换、增强并发送到另一个firehose。AWS Kinesis和Kafka是两个公共工具。
- 原始数据和转换/增强后的数据都被保存到云端。AWS Kinesis提供了一个名为firehose的设置,可以将原始数据保存到其云存储(S3),配置起来非常容易。
- 转换/增强后的数据通常会被加载进数据仓库用作数据分析。我们使用的是AWS Redshift,大部分创业公司和增长的部分也是如此,尽管大公司会使用Oracle或其他专有的仓库技术。
另外一个没有在架构图中画出来的一个步骤:将数据从应用程序和服务的操作数据库加载到数据仓库中。例如在Storyblocks,我们每晚将VideoBlocks, AudioBlocks, Storyblocks, account service和贡献值门户网站的数据加载到Redshift。通过将核心业务数据与我们的用户交互事件数据放在一起,为我们的分析师提供了一整个数据集。
10. Cloud storage
“云存储是一种简单、可靠且可扩展的存储、检索和共享数据的方法”——来自AWS。你可以使用它存储或多或少的存储和访问本地文件系统的任何内容,并且可以通过HTTP上的RESTful API与其进行交互。Amazon的S3是目前最流行的云存储产品,也是我们在Storyblocks广泛依赖的产品,用于存储我们的视频、照片和音频资产,我们的CSS和JavaScript,我们的用户数据等等。
11. CDN
CDN的全称是“Content Delivery Network”,该技术提供了通过Web获取静态HTML,CSS,JavaScript和图像资源的方式,比直接从单个源服务器提供服务要快得多。它的工作原理是在世界各地的许多“边缘”服务器上分发内容,以便用户从“边缘”服务器而不是源服务器下载资源。例如下图中,一个用户从西班牙请求源服务器在纽约的网站,但是静态资源会从在英国的CDN边缘服务器加载,防止许多缓慢的跨大西洋HTTP请求。
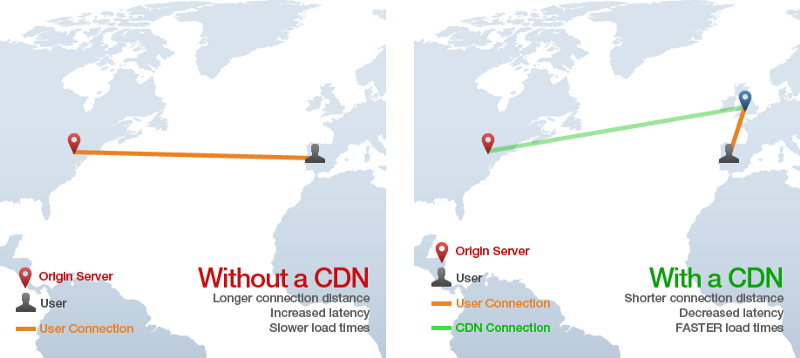
这篇文章进行了更详尽的介绍。通常web应用应该始终使用CDN来提供CSS,JavaScript,图片,视频和其他资源。某些应用也可能利用CDN来提供静态HTML页面。
总结
这是一篇入门级的Web架构总结。希望能够对你有帮助。我希望发布一系列的进阶文章,在接下来一两年内我会对这些组件进行深入研究。
正文到此结束
- 本文标签: 域名 希望 node 并发 创业 Architect NOSQL cache apache API DOM 工程师 js src 产品 queue redis 创业公司 文件系统 tab 总结 微服务 ACE sql Service java RESTful MongoDB 模型 https solr 互联网 Job 数据 工作原理 服务器 时间 开发 缓存 CDN http 标题 门户网站 云 Facebook HTML Elasticsearch ip sphinx 数据库 下载 UI IO PHP Node.js REST 索引 负载均衡 运营 网站 JavaScript mysql CSS App id db Amazon 部署 Oracle 文章 配置 图片 web Google 实例 mongo DNS 统计 cat scala IDE
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

