轻松构建微服务之docker和高效发布
我们先来了解下docker的原理,如何才能制造出一个真正隔离的软件运行环境.
namespace
docker在创建容器进程的时候可以指定一组namespace参数,这样容器就只能看到当前namespace所限定的资源,文件,设备,网络。用户,配置信息,而对于宿主机和其他不相关的程序就看不到了,PID namespace让进程只看到当前namespace内的进程,Mount namespace让进程只看到当前namespace内的挂载点信息,Network namespace让进程只看到当前namespace内的网卡和配置信息,
docker利用namespace机制隔离出一个软件执行环境,我们可以用下图来将docker和虚拟机技术做一个对比
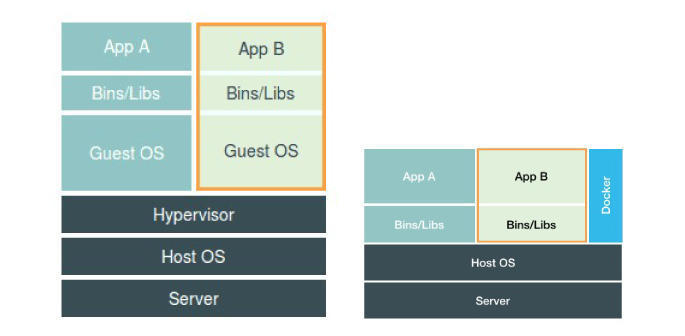
一个centOS的KVM启动起来后,即使什么不做也需要消耗200M的内存,而且用户进程运行在虚拟机里,对宿主机操作系统的调用不可避免会受到虚拟化软件的拦截,而容器化的应用依然是宿主机上的一个普通进程.
cgroup
全名 linux control group,用来限制一个进程组能够使用的资源上限,如CPU,内存,网络等,另外Cgroup还能够对进程设置优先级和将进程挂起和恢复,cgroup对用户暴露的接口是一个文件系统,/sys/fs/cgroup下 这个目录下面有 cpuset,memery等文件,每一个可以被管理的资源都会有一个文件,如何对一个进程设置资源访问上限呢?在/sys/fs/cgroup目录下新建一个文件夹,系统会默认创建上面一系列文件,然后docker容器启动后,将进程ID写入taskid文件中,在根据docker启动时候传人的参数修改对应的资源文件
$ docker run -it --cpu-period=100000 --cpu-quota=20000 ubuntu /bin/bash 复制代码
Linux Cgroup的设计还是比较易用的,简单理解就是一个子系统目录加上一组资源限制文件,而对docker等linux容器项目而言,只需要在每个子系统下面,为每个容器创建一个控制组也就是一个文件夹,让后在容器启动后写入进程PID.
文件系统
即使开启了Mount Namespace,容器进程看到的文件系统还是和宿主机一样的,mount namespace修改的时容器进程对挂载点的认知,他对容器进程视图的改变,一定伴随挂载操作才生效,但是作为一个普通用户,我们希望在容器内看到的文件系统就是一个独立的隔离环境,而不是继承自宿主机上的文件系统.
我们可以在容器启动后马上挂载他的整个根目录,这个挂载对宿主机不可见,然后通过chroot来更改change root file system更改进程的根目录到挂载的位置,一般会通过chroot挂载一个完整的linux的文件系统,但是不包括linux内核,这样当我们交付一个docker镜像的时候不仅包含需要运行的程序还包括这个程序依赖运行的这个环境,因为我们打包了整个依赖的linux文件系统,对一个应用来说,操作系统才是他所依赖的最完整的依赖库,
这个挂载在容器根目录下,用来为容器进程提供隔离后的执行环境的文件系统,就是所谓的容器镜像,它还有一个专业的名词rootFS
由于rootfs里面打包的不仅仅是用户程序,而是整个系统的文件目录,也就是是应用和应用依赖的类库和环境变量都在里面.
增量层
docker在镜像的设计中引入层的概念,也就是用户在制作docker镜像中的每一次修改都是在原来的rootfs上新增一层roofs,之后通过一种联合文件系统union fs的技术进行合并,合并的过程中如果两个rootfs中有相同的文件则会用最外层的文件覆盖原来的文件来进行去重操作,举个例子,我们从镜像中心pull一个mysql的镜像到本地,当我们通过这个镜像创建一个容器的时候,就在这个镜像原有的层上新加了一个增roofs,这个文件系统只保留增量修改,包括文件的新增删除,修改,这个增量层会借助union fs和原有层一起挂载到同一个目录,这个增加的层可以读写,原有的其他层只能读,这样保证了所有对docker镜像的操作都是增量,之后用户可以commit这个镜像将对这个镜像的修改生成一个新的镜像,新的镜像就包含了原有的层和新增的层,只有最原始的层才是一个完整的linux fs, 那么既然只读层不允许修改,那么我怎么删除只读层的文件呢,这个时候只需要在读写层也就是最外层生成一个whiteout文件来遮挡原来的文件就可以了,
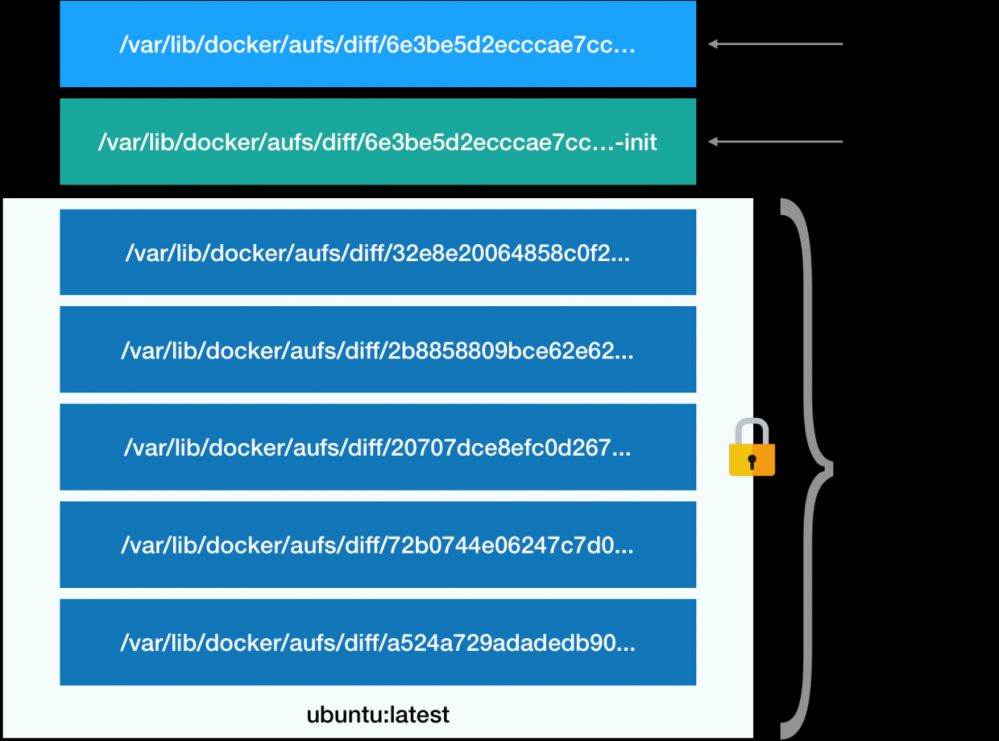
$ docker image inspect ubuntu:latest
...
"RootFS": {
"Type": "layers",
"Layers": [
"sha256:f49017d4d5ce9c0f544c...",
"sha256:8f2b771487e9d6354080...",
"sha256:ccd4d61916aaa2159429...",
"sha256:c01d74f99de40e097c73...",
"sha256:268a067217b5fe78e000..."
]
}
复制代码
dockerfile
可以通过docfile生成一个镜像,docfile里面可以指定 from的原始镜像,以及自定义操作例如拷贝文件等,容器启动命令等
例如下面的dockerfile,FROM原语指定了原始镜像是python:2.7-slim,避免了先从一个原始的ubantu镜像,然后通过apt-get install按照python
WORDIR 切换工作目录
ADD拷贝文件
RUN 在容器里执行shell
CMD 指定容器进程,相当于 docker rum python app.py
# 使用官方提供的 Python 开发镜像作为基础镜像 FROM python:2.7-slim # 将工作目录切换为 /app WORKDIR /app # 将当前目录下的所有内容复制到 /app 下 ADD . /app # 使用 pip 命令安装这个应用所需要的依赖 RUN pip install --trusted-host pypi.python.org -r requirements.txt # 允许外界访问容器的 80 端口 EXPOSE 80 # 设置环境变量 ENV NAME World # 设置容器进程为:python app.py,即:这个 Python 应用的启动命令 CMD ["python", "app.py"] 复制代码
容器网络
从之前的章节中我们可以看到,容器只是一个被隔离的进程,这个进程只能看到他自己network namespace下的网络栈,所谓的网络栈包括了 网卡(network interface),回环设备(loopback device),路由表(route table),iptables规则,这些已经可以构成这个 进程和外界进行网络通讯的基本环境.
容器作为宿主机内的一个进程,在不设置network namespace的情况下,可以使用宿主机的网络栈.
$ docker run –d –net=host --name nginx-host nginx 复制代码
以上例子,就是容器采用宿主机的网络,当容器启动后监听的是宿主机上的80端口
采用宿主机网络可以为容器提供最好的网络性能,但是我们希望容器有一个完全被隔离的环境,包括网络环境,她应该有自己的IP地址和端口,这样就不会和其他进程有端口冲突,例如我运行4个ngnx容器进程,我希望他们是完全一样的,向运行在4台宿主机里面一样,都监听80端口.所以我们希望容器进程运行在自己的network namespace内.
我们现在把容器看成,一台主机,两台主机之间想要通信,就需要拉一条网线,多个主机之间想要通信,就需要一个交换机用网线把他们连起来,在linux上,能够启到虚拟交换作用的设备就是网桥(Bridge),他是一个工作在数据链路层的设备,我们可以把它当成一个二层交换机,而二层设备主要靠学习MAC地址对应的端口,并将数据包转发到对应的端口上去.
docker在安装的时候会在宿主机上创建一个叫docker0的网桥,而容器可用通过Veth Pair的虚拟设备,连接到这个网桥,Veth Pair这种设备在创建的时候会有两张虚拟网卡,从一个网卡里面发出的数据包会到达另外一个网卡里,并且这两个网卡可以跨network namespace,这样Veth Pair可以理解为连接不同namespace的网线.
下图是我启动了两个nginx容器,分别为nginx-1 ,nginx-2,我们用ifconfig查看宿主机上的网卡信息
$ docker run –d --name nginx-1 nginx $ docker run –d --name nginx-2 nginx 复制代码
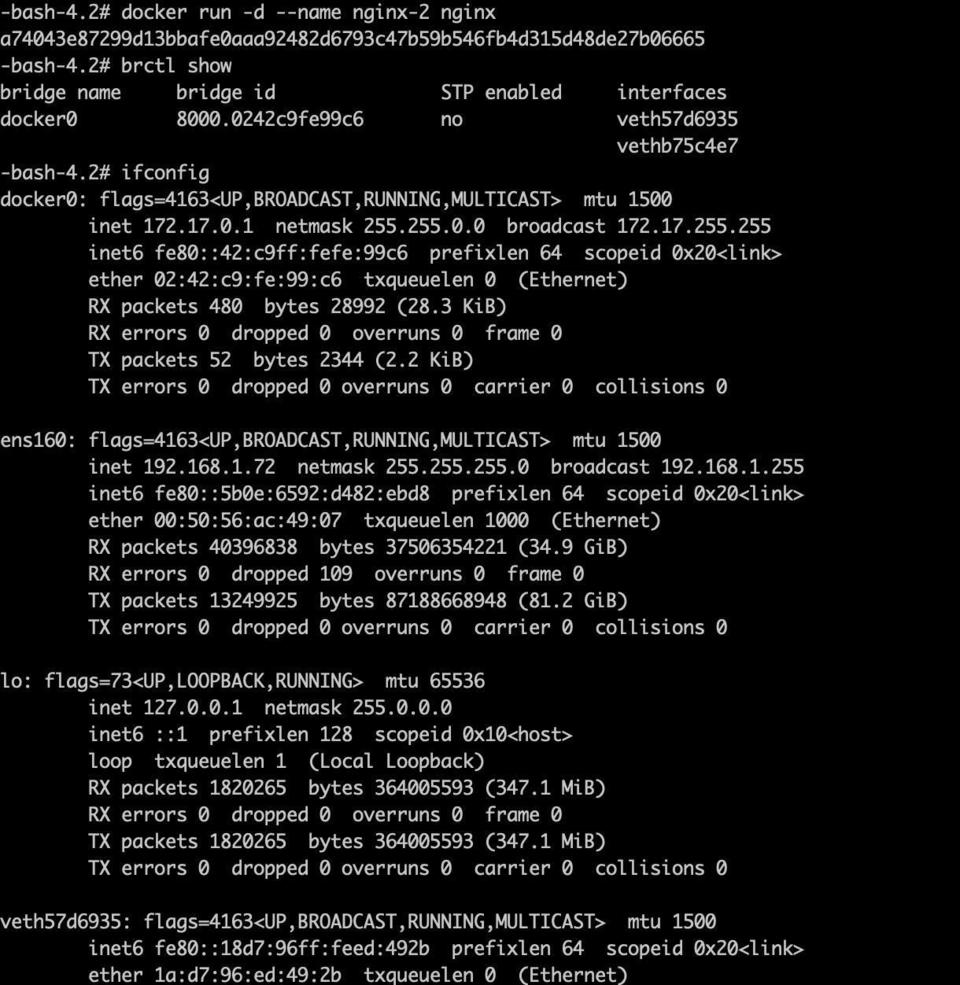
被插在网桥上的虚拟网卡,不会调用网络协议中栈处理数据包,只会像一个端口一样,将数据包交给网桥,由网桥进行转发.
下面我们分析下一个宿主机内的两个容器之间的网络怎么通讯?
当我们在容器nginx-1内去ping一下nginx-2的ip,默认下是通的
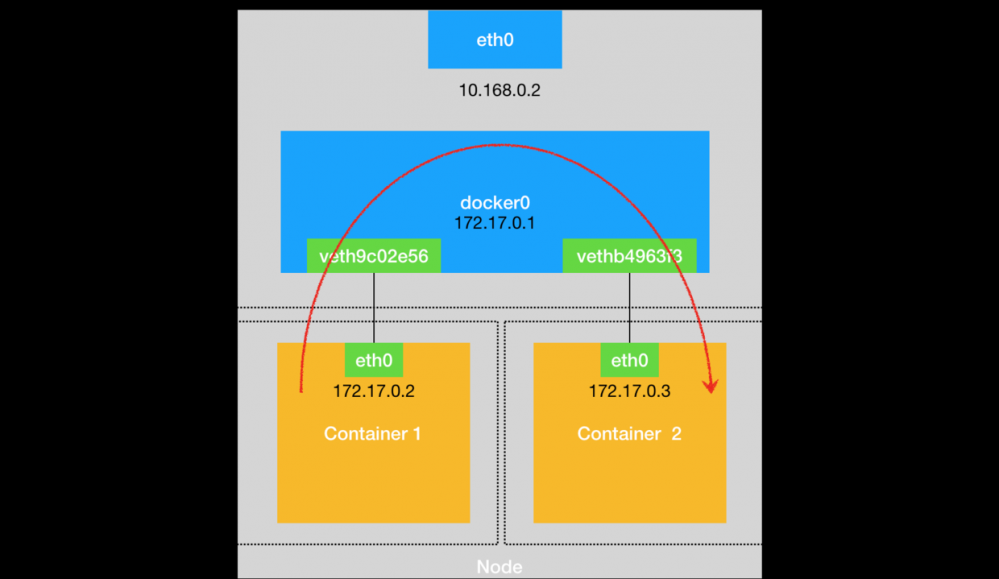
- 1.宿主机内的两个主机通过二层网络相通,nginx-1会先发一个ARP包来获取nginx-2的MAC地址
- 2.nginx-1只能看到他自己network namespace内的网卡 nginx-1-eth-0 ,所以数据包从这个网卡发出,但是这个网卡是一个Veth Pair设备,这个设备的另外一端在宿主机上默认的namespace内,并且是插在网桥docker-0上
- 3.由于Veth Pair设备的作用,宿主机的虚拟网卡收到数据包后,直接交给网桥docker-0进行转发,而docker-0会把数据包广播给插在这个网桥上的其他虚拟网卡
- 4.这样数据就会被广播到宿主机上的另外一个虚拟网卡上了,这个虚拟网卡也是一个Veth Pair,他的另外一端是nginx-2容器的namespace内的虚拟网卡,这个网卡将自己MAC地址回复
- 5.这样nginx-1的namespace内的虚拟网卡就获取到了nginx-2的namespace内的网卡的MAC地址了,就可以组装数据包将请求发给nginx-2了
- 6.同样数据包先根据Veth Pair设备到达宿主机namespace内的网卡,然后交给docker-0进行转发,由于此时docker-0网桥已经学习到了nginx-2的mac地址对应的端口了,只需要查CAM表查一下记录,转发到另外一块宿主机的虚拟网卡,然后到达nginx-2的namespace内的网卡
以上就是同一个宿主机内的不同docker容器通过Veth Pair设备和docker-0网桥通信的流程,与此类似,容器和其他宿主机进行通信,docker-0网桥在转发的时候会根据宿主机的路由规则,将数据转发给宿主机上的eth-0网卡,然后在由宿主机上德etho-进行转发.
那么容器怎么和其他宿主机内的网络通信呢?
在docker默认配置下,一台宿主机内的docker-0网桥和另外一个宿主机内的docker-0网桥没有任何关联,它们之间没办法相互关联,所以连在不同网桥上的容器没有办法进行连通.我们可以通过软件的方式,创建一整个集群共用的网桥,集群内所有的容器都连到这个网桥上,这个就是覆盖网络(overlay),为了实现这个网桥,我们需要了解FLANNEL技术,以及他的量种实现:UDP,VXLAN
UDP的模式是在宿主机内增加一个软件进程,通过TUN设备,将数据包发给上层应用,然后在由应用层判断如何进行转发,目前UDP模式已经被淘汰,主要因为性能太低,涉及太多次数据包从内核态到用户态的转发.
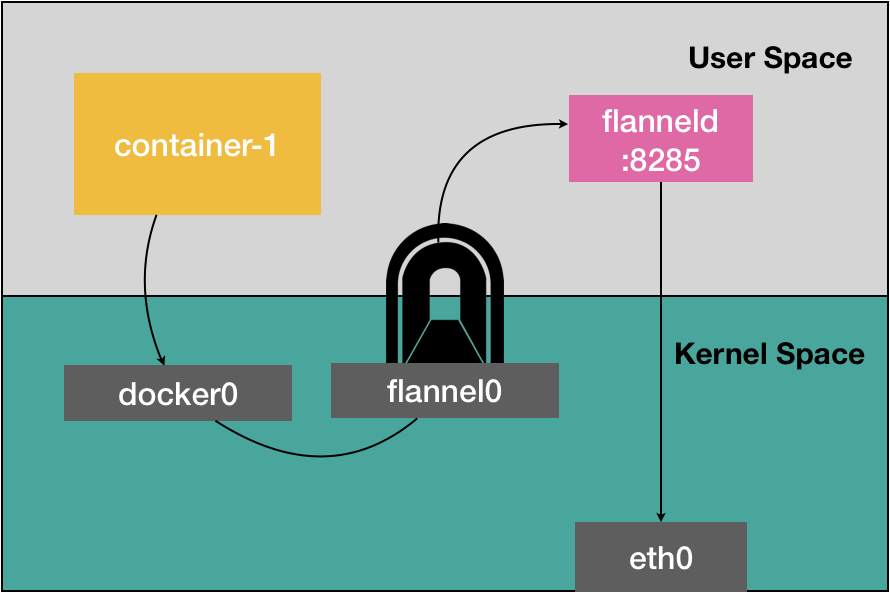
VXLAN是linux内核本身就支持的一种网络虚拟化技术,VXLAN维护一个虚拟的局域网,使在这个LAN以内的容器可以相互通信.
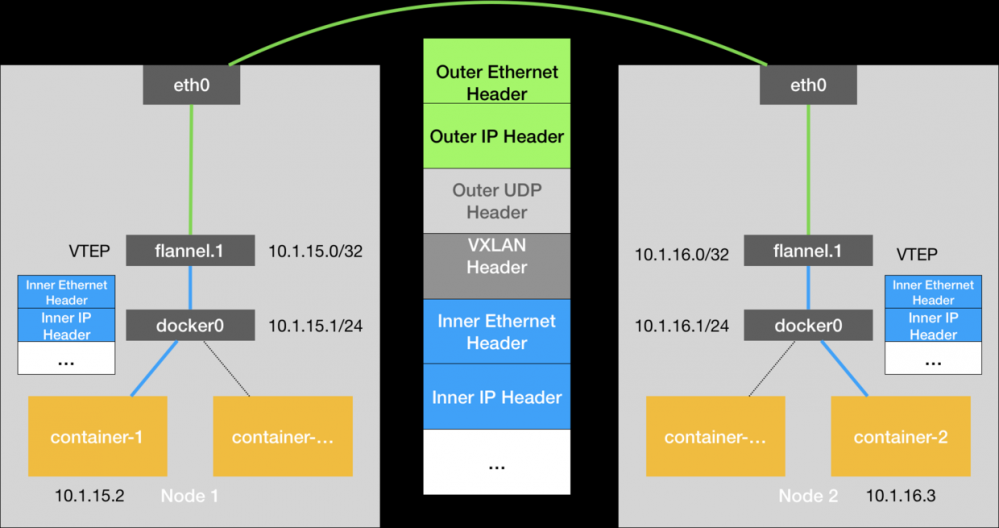
从上图可以看出,为了能让二层网络能够打通,VXLAN需要在宿主机上设置一个特殊的设备作为隧道的两端,这个设备就是VTEP (Vxlan Tunnel Endpoin ) 虚拟隧道端点.而VTEP的作用和上面UDP的应用程序类似,他会拆包和封包,只不过他在数据链路层而不是涉及用户太和内核态的转换.
kubernetes
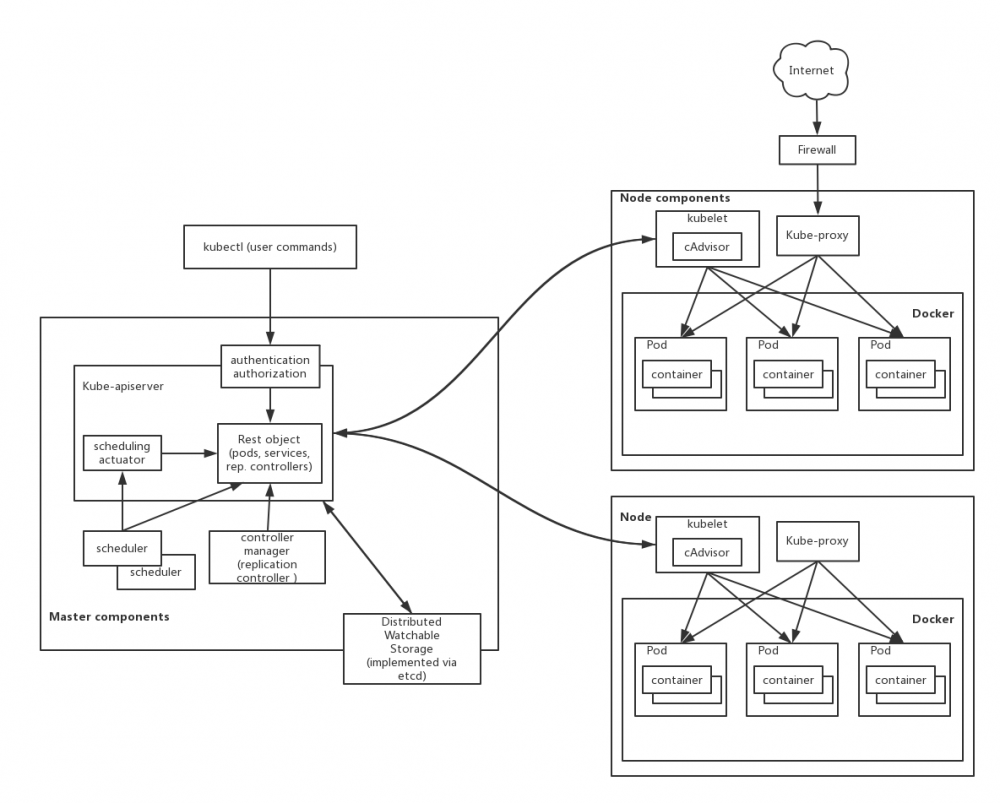
k8s是一个做容器编排和调度的工具,kubernets的最小调度单元是POD,一个POD可以管理一组同生命周期的容器,k8s提供一个restful的客户端api供用户使用,所以会有一个APIserver来接受请求,通过etcd作为数据库来存储请求中得CRUD操作,而其他模块例如控制器中的调度单元,会扫描数据库中的记录,如果有新的POD还没有分配物理节点,则会执行调度动作,如果发现新增了副本数量,就会增加POD副本,如果修改了POD相关配置就去执行,而每一个节点上面都会允许一个kube-proxy用来接收外部请求后转发,而docker采用的插拔容器,可以使用docker引擎,也可以用其他的引擎。
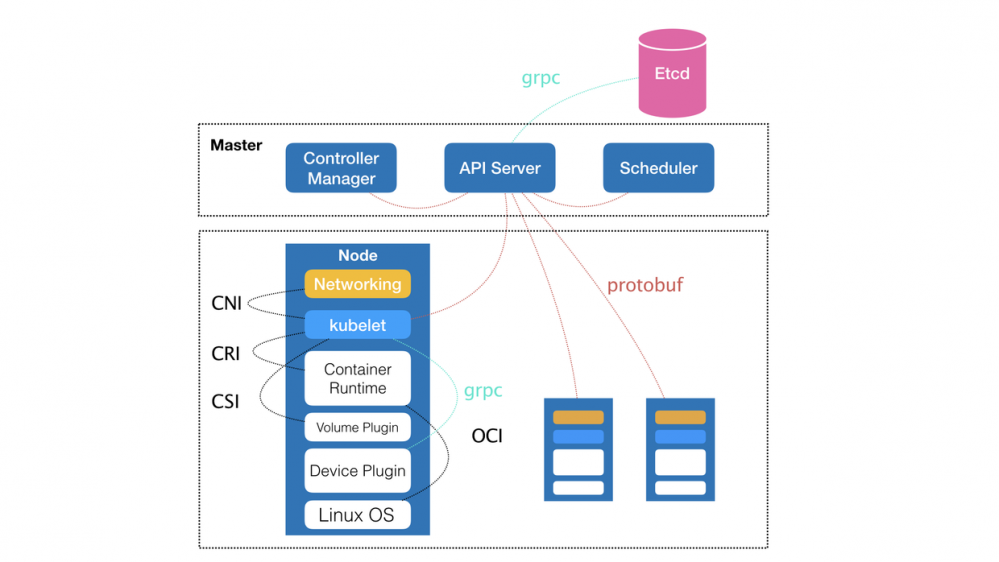
下面我们分析下k8s下相关的概念
-
1.POD POD是kubernate的最小可操作单元,如果我们把容器看成一个特殊的进程,那POD就是一个有相同生命周期的进程组,POD里的所有容器共享一个Network namespace,并且可以共享一个Volume,那么kubernate怎么实现呢? k8s会在容器创建的时候先创建一个中间容器infra,然后其他的容器和这个容器共享namespace来实现.这样一个POD内的多个容器可以通过localhost进行通信,一个POD只有一个IP地址,POD的生命周期和infra相关,和容器A和B无关.
-
2.MASTER Kubernatis集群中的master节点,可以部署在物理机或者虚拟机上,master节点负责维护集群的状态,以及对外提供API服务,master节点上部署以下3种组件
-
2.1 API SERVER,作为kubernatis系统的入口,封装了核心对象的增删改查操作以及配置操作,以RESTFUL api的方式以及命令行的方式kubectl将接口暴露给外部客户和内部组件使用,维护的对象会被持久化到etcd中.
-
2.2 Schedule 调度器:为新建的POD选择NODE,也就是分配机器,这个调度器也是可以插拔的,可以换成其他调度器,调度器可以考虑根据NODE的负载以及物理位置等参数设计调度算法.
-
2.3 Controller 控制器:所有资源的自动化控制中心,是一个大总管,例如Node Controller 用于管理NODE对象,接收NODE节点的使用情况,和NODE生命周期的管理即:创建和销毁,以及心跳检查等,Replication Controller ,副本控制器,监测业务集群中POD数量是否符合预期,如果不够会创建,多余会销毁,当管理员修改了预期的值后,该进程就会进行响应.
-
3.NODE 节点是kubernatis集群中,相对于master而言的工作主机,这些主机可以说物理机,也可以是虚拟机,POD容器都运行在这些工作节点上,每个Node上都运行着一个叫kublet的进程,用来启动和管理POD,NODE被master管理,一个NODE宕机后,master会将这台node上部署的POD在其他NODE上重新创建并部署起来,NODE节点上部署有以下组件.
-
3.1 kubelet,作为一个单独进程运行在NODE节点上,主要功能是:容器的管理,镜像的管理,数据卷的管理,同时kubelet也提供restful接口服务,当master节点的控制器可以下发请求到node上的kubelet进程,进行某个POD的创建,启动容器和销毁,并监听容器运行状态汇报给master.
-
3.2 kube-proxy,负责为POD创建代理对象,用来实现访问POD提供服务的网络请求的路由和转发,该proxy可以提供一定的负载均衡和SDN的功能
-
3.3 容器环境,可以是docker也可以是其他容器技术
-
4.etcd作为一个键值数据库,存储集群的元数据,以及POD的配置信息,并具有消息订阅功能,所以,当用户修改了POD预期副本数量,Replication Controller就可以感知到, etcs采用raft协议来保证集群环境下的数据一致性,并提供restful的api来供客户端使用,kubernatis中的网络配置信息,以及操作记录和各个对象的状态都存储在etcd中,多个组件间的交互都需要用到etcd,所以etcs对整个k8s集群特别重要,所以etcd必须保证高可用.
Devops
Devops用来保证,开发,运维,测试之间的高效沟通和协作,是软件发布更加简单和便捷.我们可以简单的将Devops思想抽象成两个产品,一个产品用来做项目管理,一个产品用来做软件发布和集成.
我们可以尝试简单思考下一个项目管理的系统需要提供哪些功能:
-
1.支持看板视图,让团队可以快速做信息同步,面板信息应该包括:项目描述,项目进度以及碰到的问题,而项目进度可以根据时间列出:需求立项,需求评审,设计评审,技术方案评审,开发,测试,发布.
-
2.项目迭代管理,提供各种维度报表,用来分析和预估后期项目周期.
-
3.代码关联,可以将需求在gitlab上关联代码
而一个软件发布的系统应该提供以下功能
-
1.代码管理,代码提交可以关联对应的需求,支持代码在线review
-
2.持续集成,支持每日定时,或者代码提交自动触发构建动作
-
3.支持从gitlab上拉取最新的代码,然后在特定环境下打包,然后根据dockerfile生成镜像并提交
-
4.支持镜像管理
-
5.支持自动化单元测试,接口测试,性能测试
-
6.持续部署,支持根据生成的镜像自动部署测试环境和开发环境,使开发环境可以随时访问
-
7.灰度发布,可以灰度发布到生产环境和预发布环境
我们如何利用k8s做到自动化打包和发布?
- 1.创建pileline 指定项目名称和对应的tag,以及依赖工程,一个pipeline指一个完整的项目生命周期(开发提交代码到代码仓库,打包,部署到开发环境,自动化测试,部署到测试环境,部署到生产环境)
- 2.根据项目名称和tag去gitlab上拉取最新的代码(利用java里的Runtime执行shell脚本)
- 3.利用maven进行打包,这个时候可以为maven创建一个单独的workspace(shell脚本)
- 4.根据预先写好的docfile,拷贝maven打的包生成镜像,并上传镜像 (shell脚本)
- 5.通过k8s的api在测试环境发布升级
- 6.通过灰度等方案发布到生产环境
蓝绿发布
一般在反向代理层,例如nginx,的配置文件做一个软连接,分别指向两套环境,我们将这两套环境分别称为生产环境和预发布环境,正常情况下配置文件的软连接指向生成环境,这个时候流量都会进入到生成环境的集群,发布的时候先发布预发布环境的机器,由于没有流量进入,所以机器重启没有太大影响,机器发布完成后,可以通过其他入口,例如内部修改host或者其他流量入口进行内部测试,如果内部测试通过,就可以修改软连接指向预发布环境的集群,然后在进行验证当外部流量进来后,是否正常,如果不正常可以直接在把流量切回去,如果正常就可以升级生成环境的机器,然后在把流量切到生产环境
灰度发布
灰度发布可以在发布前,将一部分比例的机器的流量切走,然后进行软件升级,升级完成后把流量切回来,然后进行验证,验证有问题在把流量掐掉,没有问题可以慢慢按比例对外,这种方式需要新老版本的服务同时对外提供服务,有些情况下我们把通过白名单或者固定用户的形式开发服务也叫灰度.
正文到此结束
- 本文标签: 删除 产品 MQ 目录 管理 Proxy 端口 Kubernetes Uber https 项目管理 sql id Nginx 代码 参数 微服务 shell http 进程 IO 虚拟化 数据 灰度发布 cmd App 同步 git ACE centos Master root SDN 单元测试 maven REST 主机 数据库 NIO mysql UI Dockerfile tab UDP iptables Word 集群 希望 java API 测试环境 自动化 软件 ask 调度器 linux 配置 一致性 测试 时间 开发 部署 网卡 生命 cat 文件系统 Ubuntu RESTful 反向代理 node Docker src 负载均衡 python 安装 高可用 协议 需求 操作系统 tag ip
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

