浅谈网络爬虫

网页蜘蛛(spider)
,就是能够在互联网中检索自己需要的信息的程序或脚本。
爬虫,简单的说就是 一个http(https)请求 ,获取到对面网页的源码,然后从网页的源码中抓取自己需要的信息。而html代码的规则是基于xml的,所以可以通过一定解析规则和逻辑完成我们的数据。
爬虫能干什么
爬虫能干的事情比较多,并且有些领域和爬虫都有很大的关联。不同深度,技术的爬虫工作者能干的事情也不同。
搜索引擎

- 你熟知的 谷歌、百度、360等搜索 都是
网络爬虫+算法+db存储形成的一套持久运行、相对稳定的系统。当然,这类爬虫并不是大部分人都能接触的,通常这类对硬件成本和算法的要求较高,要满足一定的爬行速率、爬行策略并且你还要通过一定算法检索文本、挖掘文本,通过文本价值和外链数量等等判权信息给搜索排名加权。具体不做过多介绍。笔者也不会。但是如果有兴趣完全可以运用开源软件或者工具做个站内搜索,或者局域搜索。这个如果有兴趣可以实现,虽然可能效果不好。
抢票、刷票等自动化软件
12306抢票 拉票,投票
部分破解软件
- 你会见到一些诸如
pandownload、全网vip视频免费看、付费知识/文档下载、qq机器人等等。有经验的爬虫工程师不仅仅能够解析http请求,而tcp-ip等请求涉及到的各种加密也能处理的非常得手。然而这些人就能开发出一些让人感到黑科技的东西。
金融等行业数据挖掘、分析数据来源
- 随着大数据热门,相关的系列领域和相关领域如数据挖掘、分析以及人工只能的。因为数据的生产者是有限的,比如新浪
微博、淘宝、京东、金融等其他等就可以自己生产数据。而其他人如果想要这些数据集,那么要么通过官方可能给的部分可怜的api、数据。要么就是买(很贵),要么就是自己爬。通过爬虫的数据可以做舆情分析,数据分析等等。数据本身是没有价值的,然而通过挖掘处理之后就极具商业、研究价值。
其他
- 数据是一个公司的核心。市面上有很多类似产品或者功能,有很多中小部分的数据核心来自于他人,所以爬虫对于他们公司至关重要。
- 而诸如
校园辅助app,博客一键搬迁,新闻等咨询,等等非官方授权的应用却有着官网app的功能都是基于网络爬虫实现。还有很多就不具体介绍。
爬虫很简单
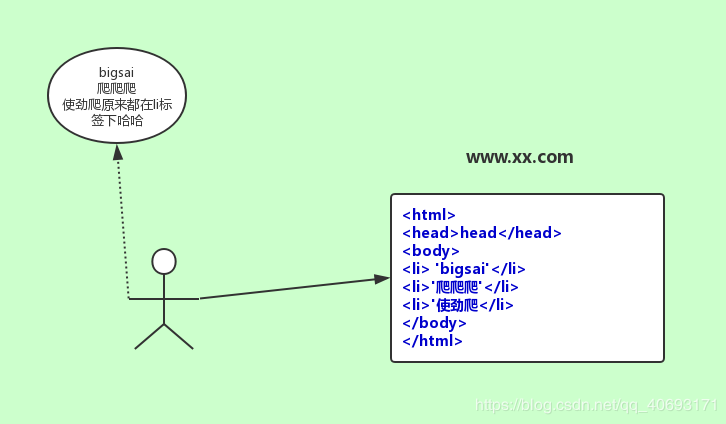
语言的选择
- 对于初学者肯定会对选择java和python有些java爱好者可能会有点难受。对于java和python的爬虫。不能全全论之。因为各个语言有各个语言的特色。
- 就爬虫而言,个人感觉
用python更方便,得益于python精简的语法和弱类型变量。能够伸缩自如。这样还有一点就是python的字典操作起来远比java的Map方便。而java的强变量让书写变得稍加繁琐。 - 但是如果遇到多线程,
高并发问题其实还是java占优。python只能用多进程来优化速度而假的多线程对性能提升有限。
对于python爬虫常用的库有
| 名称 | 主要功能 | 依赖 |
|---|---|---|
| requests | 负责网页请求,代理等处理,封装urllib2(用起来麻烦)等库,使得操作简化。不需要考虑编码、解码等较麻烦的问题 | pip install requests |
| Beautifulsoup | 非常好用的dom解析器,还有css选择器。匹配正则等,而选用lxml当做解析 | pip install bs4,pip install lxml |
| xpath | 解析效率最高,和BeautifulSoup可以选择一个学习即可 | pip install lxml |
| re | 正则库,很多特殊匹配需要正则来完成 | 内置 |
| Senlenuim/ChromeDriver+PhantomJS | 模拟浏览器行为,执行点击事件,简单粗暴,但是速度慢 | 需要安装对应库和对应驱动 |
至于框架,scrapy流行。就不介绍 对于java爬虫常用的库有
| 名称 | 主要功能 |
|---|---|
| HttpURLConnection | java.net下包。很多其他包都基于此包进行封装 |
| HttpClient | 基于 HttpURLConnection进行封装,更加友好的解决参数,Cookie,Session等问题。 |
| jsoup | 基于HttpClient进行封装,更加方便的发送请求。此外jsoup的另一个重大功能就是他是一个非常良好的dom解析器。使用起来非常简单。 |
| Senlenuim+PhantomJS | 解决动态渲染解析不了的问题,同上 |
至于框架,java的框架 比较多 ,但是 流行度却没python的scrapy高 。自己可以查询各种框架进行对比。当然自己也可以使用spring+mybatis进行封装。如果项目比较大。
两种语言的小demo
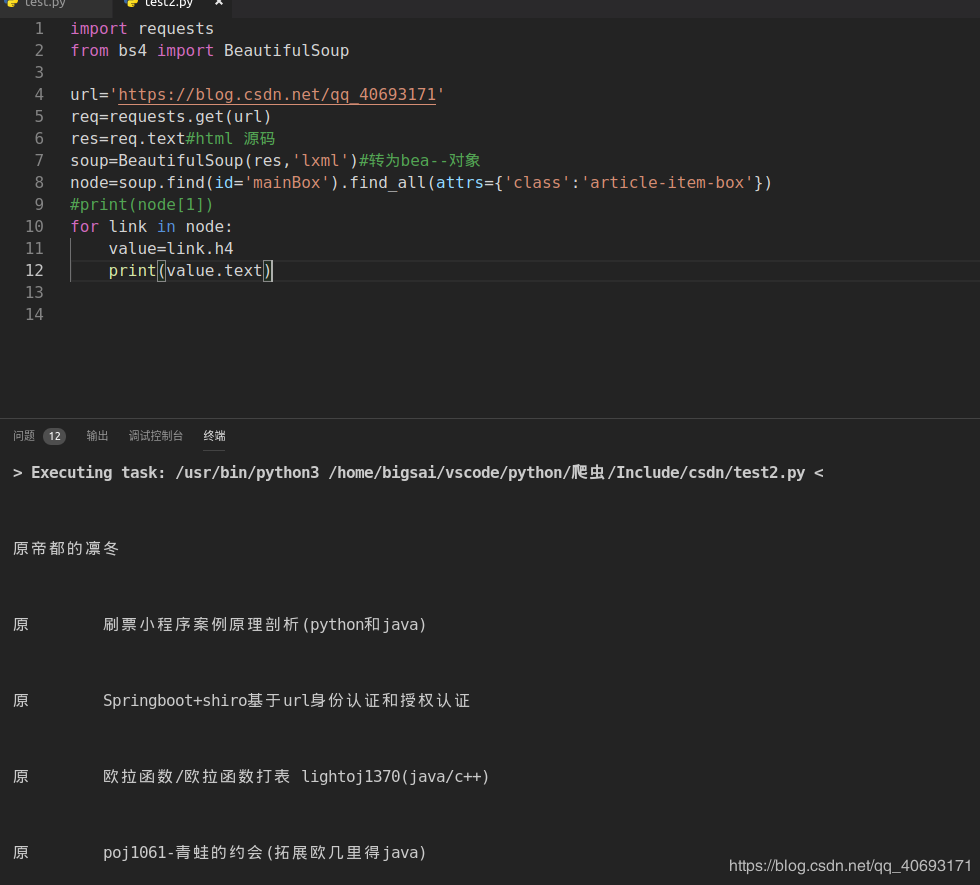
对于上面的主页,如果用python来完成数据提取
import requests
from bs4 import BeautifulSoup
url='https://blog.csdn.net/qq_40693171'
req=requests.get(url)
res=req.text#html 源码
soup=BeautifulSoup(res,'lxml')#转为bea--对象
node=soup.find(id='mainBox').find_all(attrs={'class':'article-item-box'})
for link in node:
value=link.h4
print(value.text)
复制代码
运行结果
如果用java来完成
package com.bigsai;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
public class test {
public static void main(String[] args) throws IOException {
String url="https://blog.csdn.net/qq_40693171";
Document doc= Jsoup.connect(url).get();
Elements elements=doc.getElementById("mainBox").select(".article-item-box");
for(Element element:elements)
{
Element node=element.select("h4").get(0);
System.out.println(node.text());
}
}
}
复制代码
运行结果
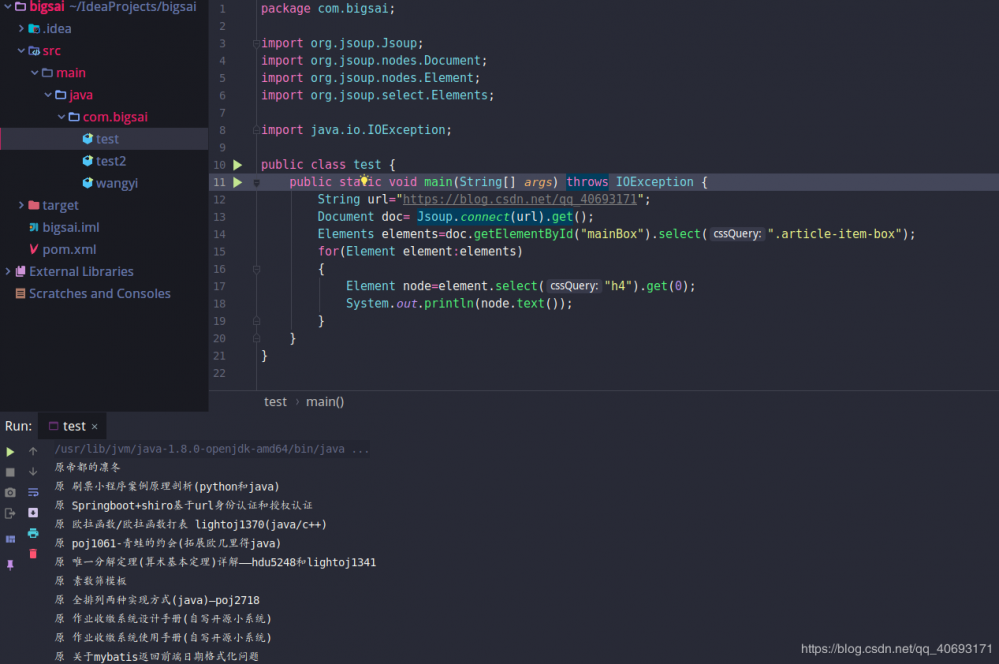
这样,一个简单的爬虫就完成了。是否勾起你对爬虫的兴趣?
爬虫也不简单
- 但是很多公司,网站的网址他们的数据是不太想随便让人爬的。有的网站给了robot.txt文件。规定那些爬虫可以爬。但是这些又是很矛盾的。因为如果你想要搜索引擎收录你,你肯定要允许百度,谷歌,360等爬虫程序访问你的网站,才能收录,搜索排名才能靠前。否则你的网站就成单机站点了。网站会处理或者拒绝
非正常访问的请求。比如检索你的请求非人为。请求过快等等。
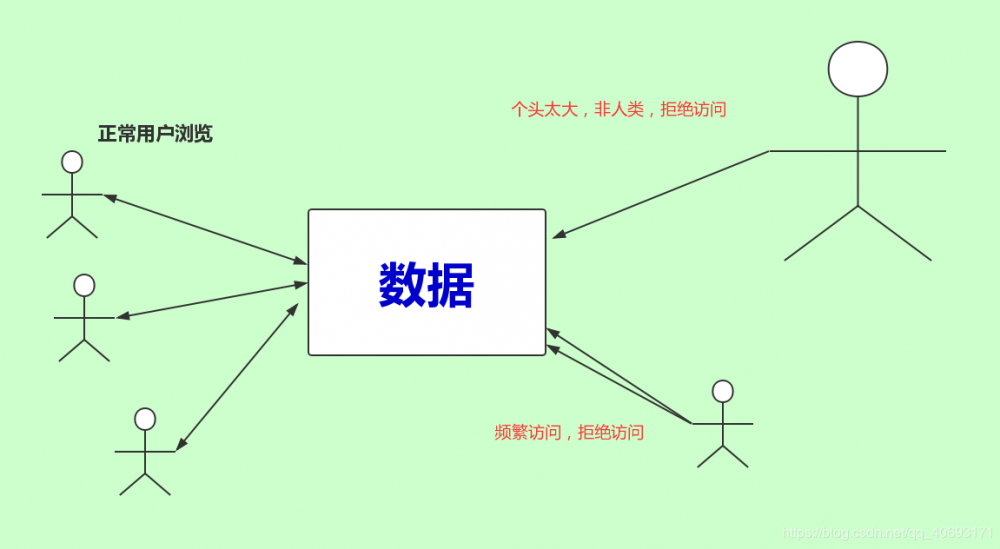
爬虫与反爬虫的斗争由此开始。
ip、浏览器头(User-Agent)、和cookie限制
一个http请求要携带很多头信息带给后台,后台也能够获取这些信息。那百度的首页打开F12刷新
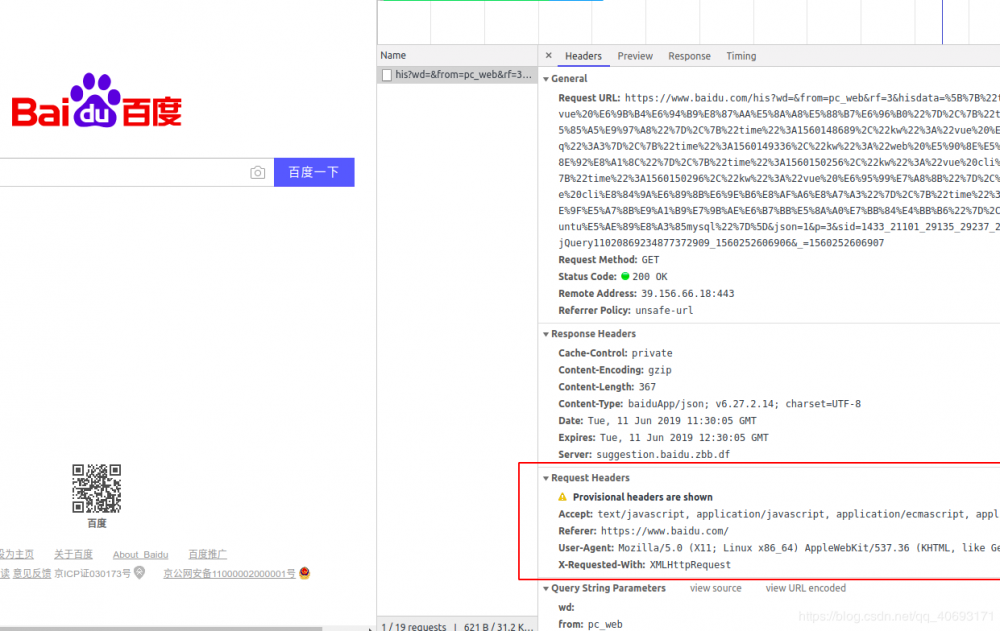
- 但是网站大部分会根据你所在的
公网ip进行封禁访问。如果你访问过快,就会招来403 forbidden。所以你需要使用代理ip来让对面认为你的ip没问题。 - 还有部分网站会针对
User-Agent等其他信息进行判断。所以你需要多准备几个User-Agent,比如谷歌的,IE的,360的随机使用即可。 - 而有些网站会根据
cookie进行封禁。因为有的cookie储存了用户的一些信息。如果网站根据cookie来进行限制,那么你不仅要找的到这样cookie池维护,还要记得维持cookie的活性。而新浪微博的反扒策略就是基于cookie鉴定。所以你需要到淘宝购买已登录过的cookie池才能拿到更多的数据。
需登录的验证码限制、参数限制
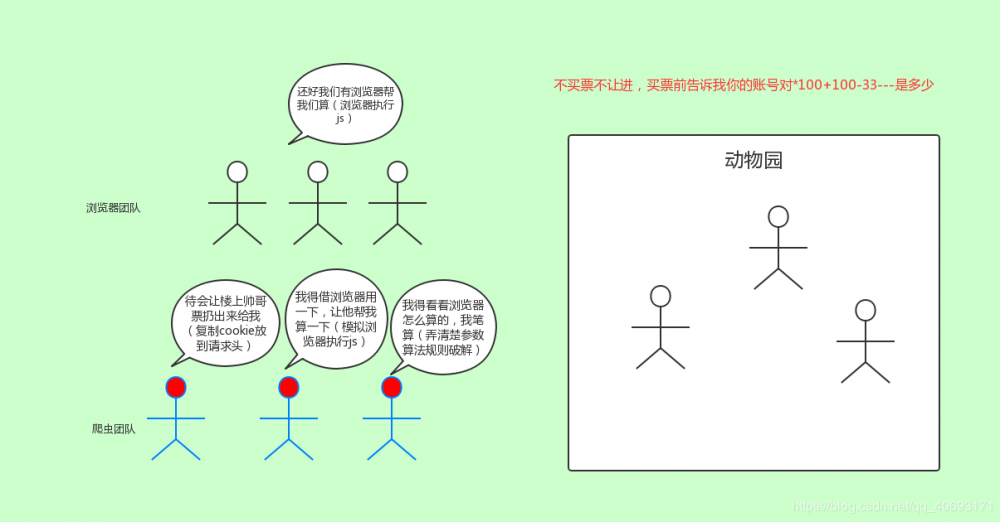
有很多数据是开放可以查看的,但是也有很多数据需要注册登录之后才能查看数据的,比如国内的各大招聘网站都需要你先登录然后才能爬取。
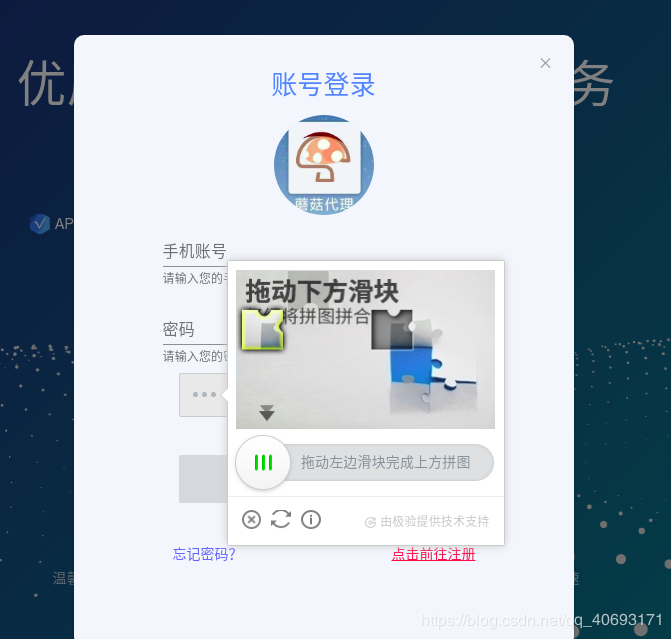
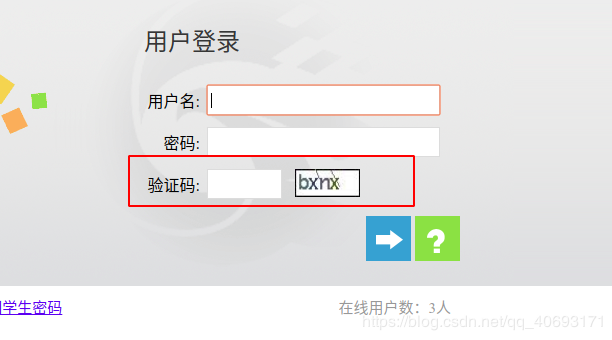
对于普通验证码来说,你大致有四个选择。
- 绕过验证码,直接手动登录用网站,复制cookie放到请求的去抓取数据。这种最不智能也是最简单的方法。(pandownload就是内置一个浏览器driver然后你手动登录后它获取你的cookie信息然后一波操作)
- 将验证码下载到本地(应用),让用户识别填写然后登录。
- 通过人工智能和数字图像相关技术,提前训练好验证码识别模型,在遇到验证码时候执行程序识别。对于简单的验证码识别。也有不少开源作品。
- 通过打码平台,让第三方专业打码。
而对于滑块以及其他奇葩如滑块,点选等等,那你要么借助第三方,要么就是自己研究其中js运转流程。以及交付方式。算法原理,还是很复杂的。笔者这部分也不是特别了解。只是略知一二。
不仅如此,在登录环节,往往还会遇到一些其他参数的会放到JavaScript里面,这需要你抓到比较。有的还会针对你的数据进行加密传到后台。这就需要你娴熟的js解密能力了。
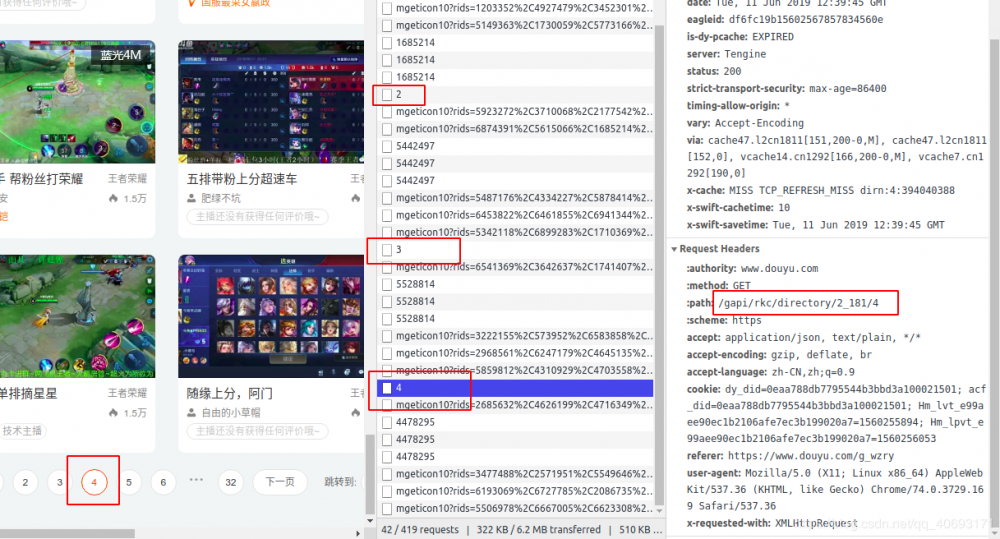
JavaScript渲染/ajax加密
- 有不少页面的数据是通过ajax或者JavaScript渲染进去的。而在数据上,爬虫无法识别、执行JavaScript代码,只能借助webdriver+phantomjs等模拟执行js获取数据。或者就是自己研究js流程。弄懂里面参数变化过程。但是实际是相当有难度的。毕竟人家一个团队写的逻辑,要你一个人(还不是搞前端的搞懂)真的是太困难的。所以,爬虫工程师的水平区别在解决这些复杂问题就体现出来了。
- 而异步传输如果借口暴露,或者能找到规则还好。如果做了加密限制,又是比较棘手的问题。
爬虫知识储备路线
虽然一些高难度的爬虫确实很难,没有一定的工作经验和时间研究确实很难变强。但是我们还是能够通过掌握一些大众知识能够满足生活、学习的日常需求和创意。
1.基础语法:
- 无论你使用java和python,爬虫也是程序,你首先要掌握这门编程语言的语法。而基础语法入门也不需要太久,但是还是 需要一点时间,不能急于求成。
正文到此结束
- 本文标签: App 下载 db value 索引 进程 UI 开源 代码 博客 web 解析 id js 搜索引擎 软件 CSS client 智能 招聘 node XML session 线程 金融 百度 SDN http java jsoup IO https 12306 加密 网站 IDE Connection TCP 数据挖掘 tab Select 工程师 find 安装 开发 多线程 公网IP spring HTML JavaScript ip Chrome 并发 产品 数据 Ajax 时间 python 源码 DOM 模型 科技 map 参数 API src 初学者 免费 自动化 谷歌 Agent 互联网 开源软件 微博 需求 排名 站点 Document 高并发 京东 mybatis 大数据 lib
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

