为什么HashMap要自己实现writeObject和readObject方法?
如果你有仔细阅读过HashMap的源码,那么你一定注意过一个问题:HashMap中有两个私有方法。
private void writeObject(java.io.ObjectOutputStream s) throws IOException private void readObject(java.io.ObjectInputStream s) throws IOException, ClassNotFoundException 复制代码
这两个方法有两个共同点:
- 都是私有方法
- 虽然是私有方法,但是在HashMap内部却找不到任何调用它们的地方
疑问
这两个方法是干嘛用的?
为什么要设置成私有的?
解答
HashMap中的writeObject和readObject方法的作用是什么?
答:readObject和writeObject方法都是为了HashMap的序列化而创建的。
首先,HashMap实现了Serializable接口,这意味着该类可以被序列化,而JDK提供的对于Java对象序列化操作的类是ObjectOutputStream,反序列化的类是ObjectInputStream。我们来看下序列化使用的ObjectOutputStream,它提供了不同的方法用来序列化不同类型的对象,比如writeBoolean,wrietInt,writeLong等,对于自定义类型,提供了writeObject方法。 ObjectOutputStream的writeObject方法会调用下面的方法:
private void writeSerialData(Object obj, ObjectStreamClass desc)
throws IOException
{
ObjectStreamClass.ClassDataSlot[] slots = desc.getClassDataLayout();
for (int i = 0; i < slots.length; i++) {
ObjectStreamClass slotDesc = slots[i].desc;
if (slotDesc.hasWriteObjectMethod()) {//如果重写了writeObject方法
PutFieldImpl oldPut = curPut;
curPut = null;
SerialCallbackContext oldContext = curContext;
try {
curContext = new SerialCallbackContext(obj, slotDesc);
bout.setBlockDataMode(true);
slotDesc.invokeWriteObject(obj, this); //调用实现类自己的writeobject方法
bout.setBlockDataMode(false);
bout.writeByte(TC_ENDBLOCKDATA);
} finally {
//省略
}
curPut = oldPut;
} else {
defaultWriteFields(obj, slotDesc);
}
}
}
复制代码
或者下面这张图也可以:
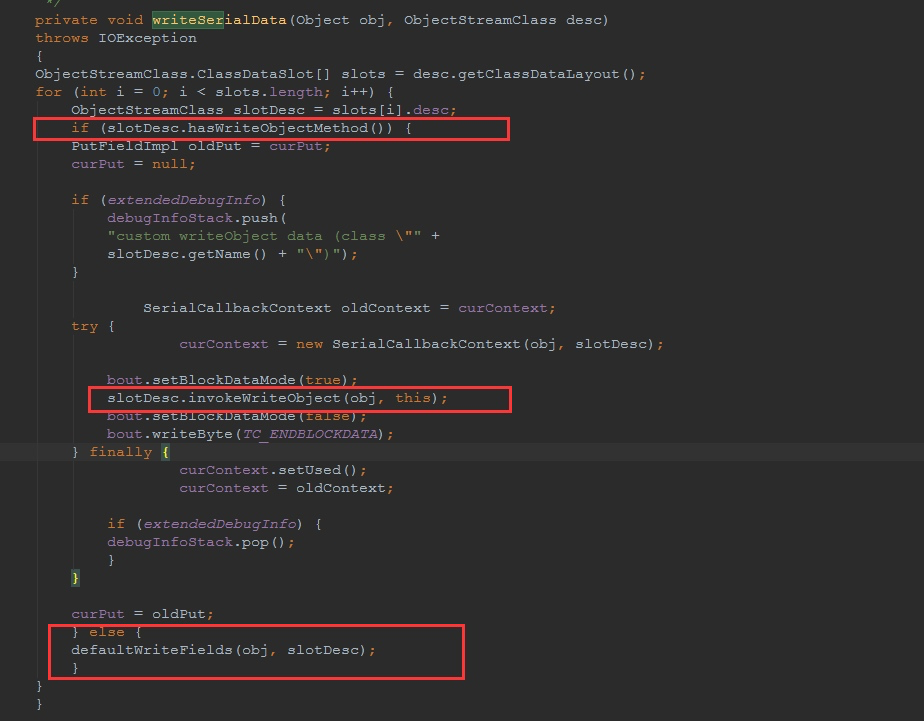
可以看到,实际上在ObjectOutputStream中进行序列化操作的时候,会判断被序列化的对象是否自己重写了writeObject方法,如果重写了,就会调用被序列化对象自己的writeObject方法,如果没有重写,才会调用默认的序列化方法。
调用关系如下图:
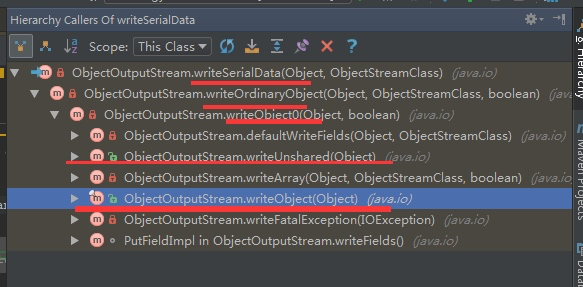
为什么HashMap中的readObject和writeObject都是私有的?
JDK文档中并没有明确说明设置为私有的原因。方法是私有的,那么该方法无法被子类override,这样做有什么好处呢? 如果我实现了一个继承HashMap的类,我也想有自己的序列化和反序列化方法,那我也可以实现私有的readObject和writeObject方法,而不用关心HashMap自己的那一部分。 下面的部分来自StackOverFlow:
We don’t want these methods to be overridden by subclasses. Instead, each class can have its own writeObject method, and the serialization engine will call all of them one after the other. This is only possible with private methods (these are not overridden). (The same is valid for readObject.)
为什么HashMap要自己实现writeObject和readObject方法,而不是使用JDK统一的默认序列化和反序列化操作呢?
首先要明确序列化的目的,将java对象序列化,一定是为了在某个时刻能够将该对象反序列化,而且一般来讲序列化和反序列化所在的机器是不同的,因为序列化最常用的场景就是跨机器的调用,而序列化和反序列化的一个最基本的要求就是,反序列化之后的对象与序列化之前的对象是一致的。
HashMap中,由于Entry的存放位置是根据Key的Hash值来计算,然后存放到数组中的,对于同一个Key,在不同的JVM实现中计算得出的Hash值可能是不同的。
Hash值不同导致的结果就是:有可能一个HashMap对象的反序列化结果与序列化之前的结果不一致。即有可能序列化之前,Key=’AAA’的元素放在数组的第0个位置,而反序列化值后,根据Key获取元素的时候,可能需要从数组为2的位置来获取,而此时获取到的数据与序列化之前肯定是不同的。
在《Effective Java》中,Joshua大神对此有所解释:
For example, consider the case of a hash table. The physical representation is a sequence of hash buckets containing key-value entries. The bucket that an entry resides in is a function of the hash code of its key, which is not, in general, guaranteed to be the same from JVM implementation to JVM implementation. In fact, it isn’t even guaranteed to be the same from run to run. Therefore, accepting the default serialized form for a hash table would constitute a serious bug. Serializing and deserializing the hash table could yield an object whose invariants were seriously corrupt.
所以为了避免这个问题,HashMap采用了下面的方式来解决:
-
- 将可能会造成数据不一致的元素使用transient关键字修饰,从而避免JDK中默认序列化方法对该对象的序列化操作。不序列化的包括:Entry[] table,size,modCount。
-
- 自己实现writeObject方法,从而保证序列化和反序列化结果的一致性。
那么,HashMap又是通过什么手段来保证序列化和反序列化数据的一致性的呢? 首先,HashMap序列化的时候不会将保存数据的数组序列化,而是将元素个数以及每个元素的Key和Value都进行序列化。 在反序列化的时候,重新计算Key和Value的位置,重新填充一个数组。 想想看,是不是能够解决序列化和反序列化不一致的情况呢? 由于不序列化存放元素的Entry数组,而是反序列化的时候重新生成,这样就避免了反序列化之后根据Key获取到的元素与序列化之前获取到的元素不同。
作者简介: 小姐姐味道 (xjjdog),一个不允许程序员走弯路的公众号。聚焦基础架构和Linux。十年架构,日百亿流量,与你探讨高并发世界,给你不一样的味道。我的个人微信xjjdog0,欢迎添加好友,进一步交流。
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

