基于 NodeJS 的 serverless 架构实践
TL;DR
通过将 BFF 构建于 serverless 之上,将人工智能实验室(天猫精灵)数十个中后台应用整合到了一个统一入口。用云函数的方式取代了传统基于 NodeJS 的 BFF 层,提供了在一个站点下不同应用以及不同环境的快速切换能力。从而极大程度的降低了开发成本和运维成本,使机器数量从 200 余台缩减为 10 台,同时有效减少了业务方的学习和理解成本。
本文主要讲述了 BFF 局限性以及我们对应的 serverless 解决方案,其中平台核心功能包括:
-
云函数:
将 BFF 层的 Node 应用代码拆解成独立云函数,支持动态编写、秒级部署,平台提供隔离的沙箱容器进行执行,并自动接入日志和监控系统,使开发者可实时掌握函数的运行状况;
-
应用:
将各平台的前端代码打包部署,入口路由进行统一注册,我们将这些平台称为应用。
这些应用将直接支持各环境切换及多套预发环境解决方案;
-
SDK:
框架将集团中间件封装为 BaaS SDK 供应用直接调用,提供一套统一的 API 抹平了 Web 和 Node 的差异;
-
CLI:
提供命令行工具便于开发者可脱离 web 管理平台,而直接快速进行开发、调试和发布。
BFF 的局限
从传统大型机到服务器集群,从虚拟技术到容器化,我们正在走向那些更加轻量、更俱灵活性的解决方案。
阿里各 BU,在“大中台,小前台”的大背景下,也逐渐从巨石应用拆分为了更为灵活的微服务,以便以更小的粒度服务于更多的需求方。
而前端也在以往前后端分离的基础上,更进一步的演变为了 BFF 架构。根据最终端上的需求,通过 BFF 层将各个微服务进行聚合和裁剪后返回。根据”谁享受谁负责“原则,该 BFF 层通常由前端使用 NodeJS 维护。
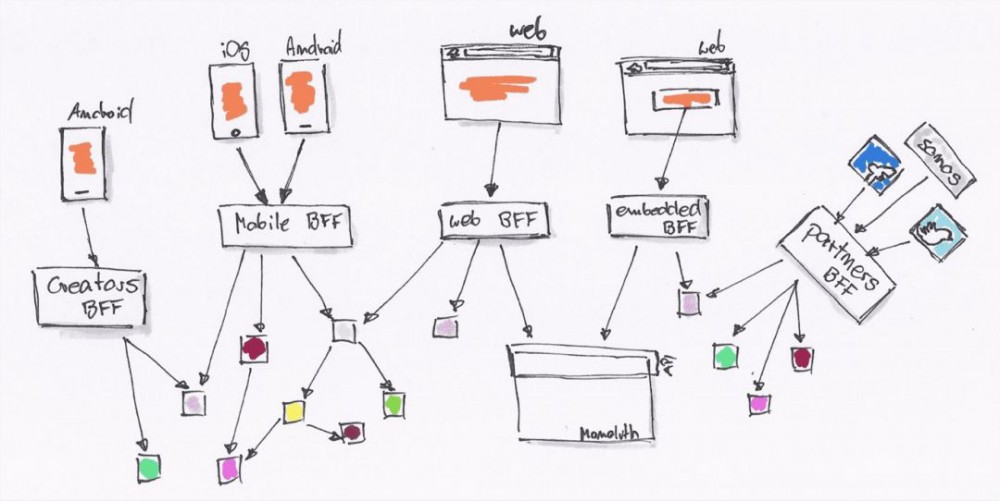 (典型 BFF 架构)
(典型 BFF 架构)
然而,作为横向支撑的前端团队,我们在实施 BFF 架构1年后,却发现它可能并没有想象的那么美好。为什么会这么说?截止目前,我们大概有 40 个左右不同的平台服务于我们的各个团队(包括运营、市场、测试、工程、算法、硬件和数据),对于大量的平台的存在,对开发人员的维护和业务方的理解,都成为了一种负担。
-
首先,每个平台都有一个对应的 Node 层来作为 BFF,我们仍然需要针对每一个平台部署代码、安装依赖的各种软件,关心究竟需要多少台服务器,这极大的增加了我们的运维成本;
-
其次,由于各个平台十分分散,均由独立域名进行访问,不同团队可能并不清楚已经存在一个类似平台从而导致提出相似需求,并且各个平台对于账户、权限、文件上传等中间件都需进行接入,对开发资源造成严重浪费;
-
最后,作为业务方,需要记住大量不同平台域名和对应的功能,也成为了一项挑战。
而每个平台还有对应还有多套环境,其也增加了他们的沟通成本和使用成本。
 (BFF 层横向扩展带来的挑战)
(BFF 层横向扩展带来的挑战)
所以,我们核心面临的问题总结起来就是运维成本难降低、重复开发难避免、入口分散难管理。那么有没有一种更轻量的架构,使我们所有人能从上述这些繁琐的工作中解放出来?
我们想到了 serverless,它让 NoOps 成为可能,实现零配置发布业务代码,这能极大降低运维成本。但传统的 serverless 仍然只能解决一个点的问题,如果我们做的更进一步,将 serverless 与已有的 BFF、FE 整合,那是不是有可能同时解决上述问题?基于上述思考,我们提出了自己的 serverless 架构。
在此之前,先介绍一下什么是 serverless。
serverless
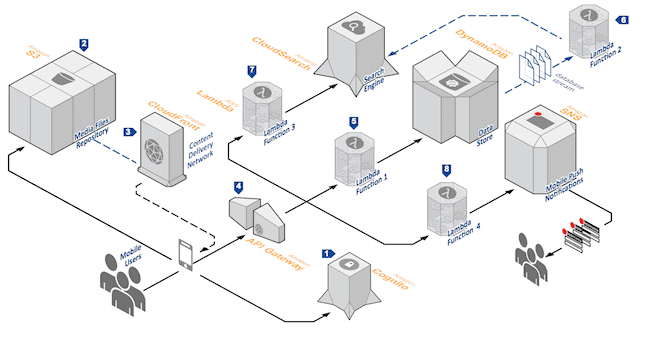 (基于 AWS lambda 的典型应用)
(基于 AWS lambda 的典型应用)
serverless 的定义如下
无服务器架构是基于互联网的系统,其中应用开发不使用常规的服务进程。相反,它们仅依赖于第三方服务,客户端逻辑和服务托管远程过程调用的组合。
目前我们说的 serverless,最常是指 Amazon 在 2014 年发布的 AWS Lambda 服务,为在服务端中运行的程序提供了一种全新的架构。我们不需要在服务器上持续运行进程以等待请求,而是可以通过某种事件机制来触发容器从而动态的执行代码。
不需要再关心应该配置多少机器,需要预装哪些依赖,这些统统由平台搞定,而我们只需要维护一个功能的集合,这些功能以“函数”的方式被调用。这种模式我们通常也把它称为 Faas(Function as a Services),一种比微服务粒度更小的代码组织方式。
关于 serverless 的介绍网上已有很多,具体可以从下面这篇文章开始,这里不再进行赘述。
从IaaS到FaaS—— Serverless架构的前世今生
BFF in serverless
然而独立的 FaaS 其实并不具备实用性,因为他是无状态的,无法进行存储意味着无法针对不同用户提供服务。Amazon 的解决方案是让 Lambda 打通 AWS 大量基础服务,通过简单的 API 调用,即可使用 S3、RDS 等存储服务来保存用户数据。即使这样,仍然有很多工作需要开发者完成。
我们结合的实际情况,在平台中统一了 FE、BFF,并封装了大量集团中间件,使其成为一体化解决方案,让开发者仅需在一个平台,即可完成应用的开发、调试、构建和部署。
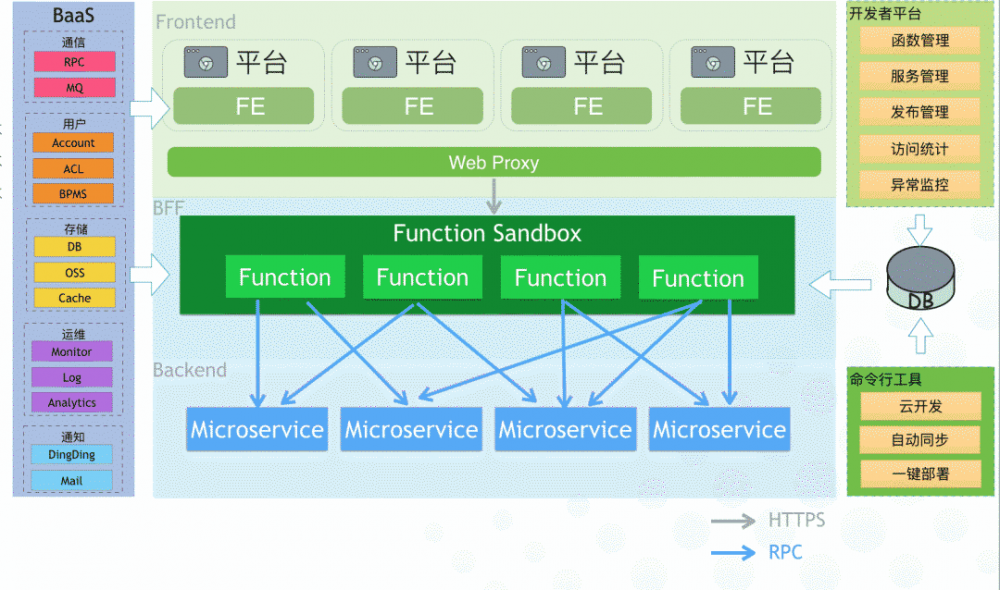 (平台整体链路)
(平台整体链路)
下面将详细介绍平台几大核心功能及其背后的思考。
1. 云函数
函数运行可以说是 serverless 架构的基础,为此我们创建了一个独立的 sandbox 模块来提供该功能的基础环境。
其实现方式类似 egg 的 master/worker 模式。不同之处在于请求进来时,会根据 request 查询到具体的代码片段,然后启动 worker 进程来运行,最后将运行的结果 response 到客户端,worker 再进行自销毁。
这么做的好处是我们可以针对任何一个函数进行监控和限制,了解和控制它的运行时长、内存占用,防止恶意代码侵害公共环境,不同函数之间也不会造成相互干扰。
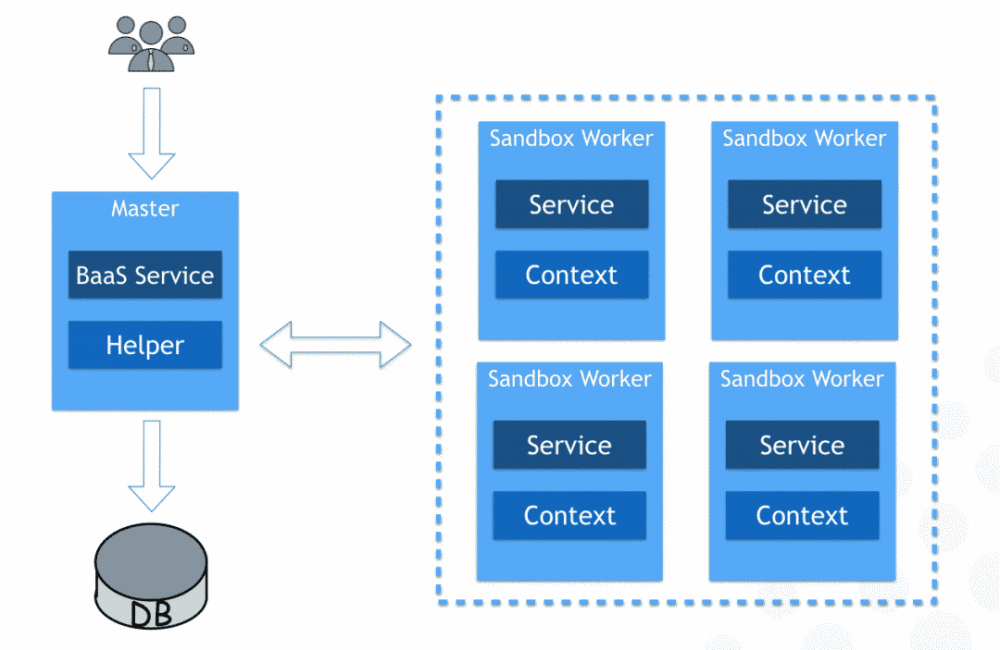 (函数运行环境)
(函数运行环境)
2. 开发者工作台(应用)
维护一个统一的入口,是平台其他功能能正常运转的基石。通过系统发布的所有平台,均通过同一域名进入,在导航处提供了在不同平台之间切换的功能,我们将这些平台称为”应用“。
这里和“阿里内外工作台”的实现方式略有不同,“工作台”是通过统一门户,再导航至不同二级域名,其每二级站点实际为独立机器进行部署。而我们在不同应用之前的切换,只是同一域名下不同路由的切换,实际背后提供服务的都是同一个服务器集群。
这样做的好处是一些业务无关的框架级功能可以在平台上进行统一实现,比如后面提到的环境切换和多套预发环境管理。对于业务来说,需求方再也不需要记住不同平台的各种域名,在任意平台也实现了各平台间的导航。
而开发者工作台,提供了应用管理的所有功能,包括 BaaS 配置、函数发布、监控日志等,以满足开发者的日常需求,并极大的改善开发者开发体验。
 (开发者平台)
(开发者平台)
3. 在线环境切换
利用统一入口的优势,我们可以在线上、预发、日常之间实现无缝切换。然而由于阿里日常与线上的天然隔离,以及中间件的环境限制,我们并没有办法在线上环境的函数中,调用日常环境的 API 接口。为了实现各环境互通,我们在统一入口处增加了一层线上环境 Proxy。通过这层 Proxy,线上环境仍是正常访问,而当访问的是预发、日常的函数时,将通过 HTTP 的方式,到真正平台对应环境的机器上再执行相应函数。
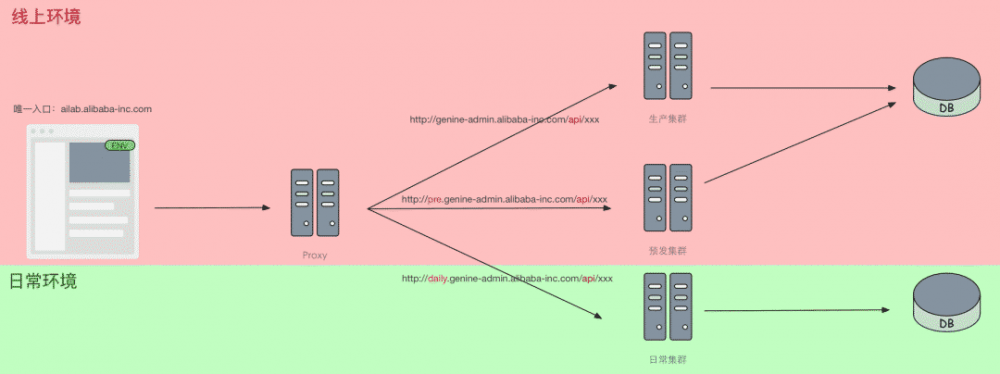 (在线环境切换部署方案)
(在线环境切换部署方案)
4. 多套预发环境管理
由于我们特殊情况,在预发部署了多套环境用于项目联调,然而因为我们业务较为复杂,一套完整链路往往涉及100个左右的应用,因为别个项目的修改需要每个应用都进行部署显然是不合理的。
那么有没有一种方式,只部署有修改的应用,而没有修改的应用,当在该环境访问时如果缺失,自动进入默认标准环境中,并且后续链路能维持这个逻辑呢?
我们通过在请求加入标志位的方式,实现了实现这一需求。
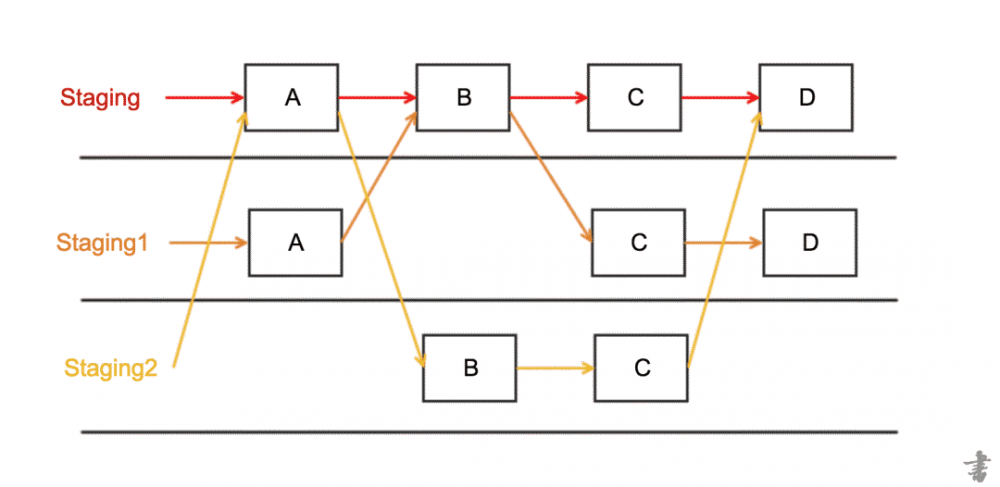 (当链路未部署时自动切换至标准环境)
(当链路未部署时自动切换至标准环境)
5. BaaS SDK
如果 egg 没有通过插件化机制来支持集团的各种中间件,如果 AWS 只是单纯的 serverless 而没有与 S3、RDS 等服务打通,那么其实很难规模化应用。
为了有效降低开发门槛和成本,我们建立了一套 Web 与 Node 端 API 基本一致的 SDK,使开发者在进行开发时,不必显著的区分当前环境是在浏览器中还是在服务端中,从而有效降低学习成本。
下面举个栗子:
// 初始化 app,只需执行一次
import genie from '@ali/cloud-genie';
const app = genie.initApp();
// 1. 云函数调用
const { cf } = app.cf();
const data = await cf.invoke('functionName', params);
// 2. 根据花名查询用户信息
const buc = app.buc();
const userInfo = await buc.getUserByNickNameCn('花名');
通过上述简单的调用,即可实现调用集团包括 DB 在内的各个中间件及服务。
6. CLI
除此之外,我们还提供了一个 CLI 工具,用于开发者快速的进行开发、调试和发布。
由于我们基于 serverless 架构,实际上在本地进行调试已没有太大必要,所以我们针对函数的调试,实际上都是连接到日常或预发机器直接运行的,再将运行的结果同步会开发者的终端,开发者本地并不需要搭建 serverless 的运行环境。
More
虽然平台已可完成基本开发,为了更好的支撑更多的业务,我们后面的计划主要包括租户隔离、多协议支持、可视化编写。
租户隔离:目前平台自带 Portal,故只支持了天猫精灵相关需求在上面进行开发,租户隔离期望实现不同 Portal 在数据上的隔离,以支持更多的业务线。
多协议支持:目前平台只支持 HTTP 协议,后续将支持更多协议,以便于服务更多的业务场景。
可视化编写:目前平台主要以 CLI 的方式编写函数,但其实 BFF 层很多只是简单的聚合和裁剪,如果我们能通过可视化的方式,选择一些 API 进行聚合,再根据需求进行裁剪,那么对于客户端等其他同学将更加友好,进一步降低开发成本。
写在最后
serverless 对业务开发者具有极大的友好性,使开发者不用了解应用服务器如何配置、数据库如何链接、消息服务中间件如何搭建,不需了解到底需要多少台服务器才能支撑,尤其是针对前端开发人员,NoOps 的特性正好弥补了前端运维能力的短板,使其从前端到全栈的转变提供了一个良好的平台。
而 BFF in serverless 在 serverless 架构的基础上,提供了一套完善的 BaaS SDK、监控日志体系以及前端解决方案,从而更进一步降低了开发者门槛。
其它精选文章:
天猫精灵智能家居之前世今生
科学精神与互联网A/B实验
当AI具备了视觉想象力
深度揭秘天猫精灵对话引擎
如何设计一个网关? 来自天猫精灵的架构供你参考
天猫精灵的边缘端异构计算引擎ACE
天猫精灵 的扩展点架构
来自天猫精灵的AutoML扫码或长按关注微信公众号: 天猫精灵技术。
 讲述天猫精灵背后的技术
讲述天猫精灵背后的技术
正文到此结束
热门推荐










相关文章

近期评论
-
不会英语啊。
-
前100名用户会展示特殊的纪念徽章
-
-
https://pplx.ai/floraliu4199466 这个链接打不开是什么原因?
-
-
-
-
来看看,最近更新了一波,顺着友联过来的,几年过去了,网站越搞越好,厉害
-
哥太牛了
-
是呀,看您的IP显示在美国,还以为您移民了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

