java核心技术36讲笔记
Java-Basic
谈谈final、 finally、 finalize有什么不同?
典型回答:
final可以用来修饰类、方法、变量,分别有不同的意义, final修饰的class代表不可以继承扩展, final的变量是不可以修改的,而final的方法也是不可以重写的( override)。
finally则是Java保证重点代码一定要被执行的一种机制。我们可以使用try-finally或者try-catch-finally来进行类似关闭JDBC连接、保证unlock锁等动作。
finalize是基础类java.lang.Object的一个方法,它的设计目的是保证对象在被垃圾收集前完成特定资源的回收。 finalize机制现在已经不推荐使用,并且在JDK 9开始被标记
为deprecated。
强引用、软引用、弱引用、幻象引用有什么区别?具体使用场景是什么?
不同的引用类型,主要体现的是对象不同的可达性( reachable)状态和对垃圾收集的影响。
所谓强引用( "Strong" Reference),就是我们最常见的普通对象引用,只要还有强引用指向一个对象,就能表明对象还“活着”,垃圾收集器不会碰这种对象。对于一个普通的对
象,如果没有其他的引用关系,只要超过了引用的作用域或者显式地将相应(强)引用赋值为null,就是可以被垃圾收集的了,当然具体回收时机还是要看垃圾收集策略。
软引用( SoftReference),是一种相对强引用弱化一些的引用,可以让对象豁免一些垃圾收集,只有当JVM认为内存不足时,才会去试图回收软引用指向的对象。 JVM会确保在抛
出OutOfMemoryError之前,清理软引用指向的对象。软引用通常用来实现内存敏感的缓存,如果还有空闲内存,就可以暂时保留缓存,当内存不足时清理掉,这样就保证了使用缓
存的同时,不会耗尽内存。
andriod中的图片缓存是软引用的例子.
弱引用( WeakReference)并不能使对象豁免垃圾收集,仅仅是提供一种访问在弱引用状态下对象的途径。这就可以用来构建一种没有特定约束的关系,比如,维护一种非强制性
的映射关系,如果试图获取时对象还在,就使用它,否则重现实例化。它同样是很多缓存实现的选择。
ThreadLocal中entry的Key是弱引用的例子.
对于幻象引用,有时候也翻译成虚引用,你不能通过它访问对象。幻象引用仅仅是提供了一种确保对象被fnalize以后,做某些事情的机制,比如,通常用来做所谓的PostMortem清理机制,我在专栏上一讲中介绍的Java平台自身Cleaner机制等,也有人利用幻象引用监控对象的创建和销毁。
理解Java的字符串, String、 StringBufer、 StringBuilder有什么区别?
String是Java语言非常基础和重要的类,提供了构造和管理字符串的各种基本逻辑。它是典型的Immutable类,被声明成为fnal class,所有属性也都是fnal的。也由于它的不可
变性,类似拼接、裁剪字符串等动作,都会产生新的String对象。由于字符串操作的普遍性,所以相关操作的效率往往对应用性能有明显影响。
StringBufer是为解决上面提到拼接产生太多中间对象的问题而提供的一个类,我们可以用append或者add方法,把字符串添加到已有序列的末尾或者指定位置。 StringBufer本
质是一个线程安全的可修改字符序列,它保证了线程安全,也随之带来了额外的性能开销,所以除非有线程安全的需要,不然还是推荐使用它的后继者,也就是StringBuilder。
StringBuilder是Java 1.5中新增的,在能力上和StringBufer没有本质区别,但是它去掉了线程安全的部分,有效减小了开销,是绝大部分情况下进行字符串拼接的首选。
String是Immutable类的典型实现,原生的保证了基础线程安全,因为你无法对它内部数据进行任何修改,这种便利甚至体现在拷贝构造函数中,由于不可
变, Immutable对象在拷贝时不需要额外复制数据。
为了实现修改字符序列的目的, StringBufer和StringBuilder底层都是利用可修改的( char, JDK 9以后是byte)数组,二者都继承了AbstractStringBuilder,里面包含了基本
操作,区别仅在于最终的方法是否加了synchronized。
谈谈Java反射机制,动态代理是基于什么原理?
典型回答:
反射机制是Java语言提供的一种基础功能,赋予程序在运行时自省( introspect,官方用语)的能力。通过反射我们可以直接操作类或者对象,比如获取某个对象的类定义,获取类
声明的属性和方法,调用方法或者构造对象,甚至可以运行时修改类定义。
动态代理是一种方便运行时动态构建代理、动态处理代理方法调用的机制,很多场景都是利用类似机制做到的,比如用来包装RPC调用、面向切面的编程( AOP)。
实现动态代理的方式很多,比如JDK自身提供的动态代理,就是主要利用了上面提到的反射机制。还有其他的实现方式,比如利用传说中更高性能的字节码操作机制,类
似ASM、 cglib(基于ASM)、 Javassist等。
我们知道Spring AOP支持两种模式的动态代理, JDK Proxy或者cglib,如果我们选择cglib方式,你会发现对接口的依赖被克服了。
cglib动态代理采取的是创建目标类的子类的方式,因为是子类化,我们可以达到近似使用被调用者本身的效果。
int和Integer有什么区别?谈谈Integer的值缓存范围。
典型回答:
int是我们常说的整形数字,是Java的8个原始数据类型( Primitive Types, boolean、 byte 、 short、 char、 int、 foat、 double、 long)之一。 Java语言虽然号称一切都是对象,
但原始数据类型是例外。
Integer是int对应的包装类,它有一个int类型的字段存储数据,并且提供了基本操作,比如Math运算、 int和字符串之间转换等。在Java 5中,引入了自动装箱和自动拆箱功能
( boxing/unboxing), Java可以根据上下文,自动进行转换,极大地简化了相关编程。
关于Integer的值缓存,这涉及Java 5中另一个改进。构建Integer对象的传统方式是直接调用构造器,直接new一个对象。但是根据实践,我们发现大部分数据操作都是集中在有
限的、较小的数值范围,因而,在Java 5中新增了静态工厂方法valueOf,在调用它的时候会利用一个缓存机制,带来了明显的性能改进。按照Javadoc, 这个值默认缓存
是-128到127之间。
这种缓存机制并不是只有Integer才有,同样存在于其他的一些包装类,比如:
- Boolean,缓存了true/false对应实例,确切说,只会返回两个常量实例Boolean.TRUE/FALSE。
- Short,同样是缓存了-128到127之间的数值。
- Byte,数值有限,所以全部都被缓存。
- Character,缓存范围'u0000' 到 'u007F'。
注意事项:
[1] 基本类型均具有取值范围,在大数*大数的时候,有可能会出现越界的情况。
[2] 基本类型转换时,使用声明的方式。例: int result= 1234567890 24 365;结果值一定不会是你所期望的那个值,因为1234567890 24已经超过了int的范围,如果修改为: long result= 1234567890L 24 * 365;就正常了。
[3] 慎用基本类型处理货币存储。如采用double常会带来差距,常采用BigDecimal、整型(如果要精确表示分,可将值扩大100倍转化为整型)解决该问题。
[4] 优先使用基本类型。原则上,建议避免无意中的装箱、拆箱行为,尤其是在性能敏感的场合,
[5] 如果有线程安全的计算需要,建议考虑使用类型AtomicInteger、 AtomicLong 这样的线程安全类。部分比较宽的基本数据类型,比如 foat、 double,甚至不能保证更新操作的原子性,
可能出现程序读取到只更新了一半数据位的数值。
[4].原则上, 建议避免无意中的装箱、拆箱行为 ,尤其是在性能敏感的场合,创建10万个Java对象和10万个整数的开销可不是一个数量级的,不管是内存使用还是处理速度,光是对象头
的空间占用就已经是数量级的差距了。
以我们经常会使用到的计数器实现为例,下面是一个常见的线程安全计数器实现。
class Counter {
private fnal AtomicLong counter = new AtomicLong();
public void increase() {
counter.incrementAndGet();
}
}
如果利用原始数据类型,可以将其修改为
class CompactCounter {
private volatile long counter;
private satic fnal AtomicLongFieldUpdater<CompactCounter> updater = AtomicLongFieldUpdater.newUpdater(CompactCounter.class, "counter");
public void increase() {
updater.incrementAndGet(this);
}
}
Java原始数据类型和引用类型局限性:
前面我谈了非常多的技术细节,最后再从Java平台发展的角度来看看,原始数据类型、对象的局限性和演进。
对于Java应用开发者,设计复杂而灵活的类型系统似乎已经习以为常了。但是坦白说,毕竟这种类型系统的设计是源于很多年前的技术决定,现在已经逐渐暴露出了一些副作用,例
如:
- 原始数据类型和Java泛型并不能配合使用
这是因为Java的泛型某种程度上可以算作伪泛型,它完全是一种编译期的技巧, Java编译期会自动将类型转换为对应的特定类型,这就决定了使用泛型,必须保证相应类型可以转换
为Object。
- 无法高效地表达数据,也不便于表达复杂的数据结构,比如vector和tuple我们知道Java的对象都是引用类型,如果是一个原始数据类型数组,它在内存里是一段连续的内存,而对象数组则不然,数据存储的是引用,对象往往是分散地存储在堆的不同位
置。这种设计虽然带来了极大灵活性,但是也导致了数据操作的低效,尤其是无法充分利用现代CPU缓存机制。
Vector、 ArrayList、 LinkedList有何区别?
典型回答:
Vector是Java早期提供的线程安全的动态数组,如果不需要线程安全,并不建议选择,毕竟同步是有额外开销的。 Vector内部是使用对象数组来保存数据,可以根据需要自动的增加
容量,当数组已满时,会创建新的数组,并拷贝原有数组数据。
ArrayList是应用更加广泛的动态数组实现,它本身不是线程安全的,所以性能要好很多。与Vector近似, ArrayList也是可以根据需要调整容量,不过两者的调整逻辑有所区
别, Vector在扩容时会提高1倍,而ArrayList则是增加50%。
LinkedList顾名思义是Java提供的双向链表,所以它不需要像上面两种那样调整容量,它也不是线程安全的。
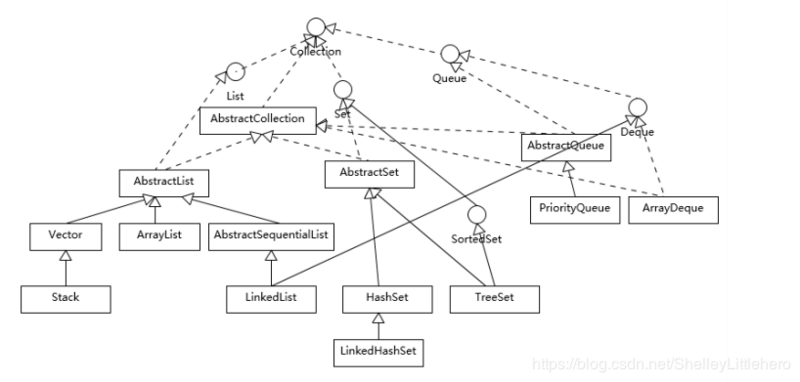
我们可以看到Java的集合框架, Collection接口是所有集合的根,然后扩展开提供了三大类集合,分别是:
- List,也就是我们前面介绍最多的有序集合,它提供了方便的访问、插入、删除等操作。
- Set, Set是不允许重复元素的,这是和List最明显的区别,也就是不存在两个对象equals返回true。我们在日常开发中有很多需要保证元素唯一性的场合。
- Queue/Deque,则是Java提供的标准队列结构的实现,除了集合的基本功能,它还支持类似先入先出( FIFO, First-in-First-Out)或者后入先出( LIFO, Last-In-FirstOut)等特定行为。这里不包括BlockingQueue,因为通常是并发编程场合,所以被放置在并发包里。
今天介绍的这些集合类,都不是线程安全的,对于java.util.concurrent里面的线程安全容器,我在专栏后面会去介绍。但是,并不代表这些集合完全不能支持并发编程的场景,
在Collections工具类中,提供了一系列的synchronized方法,比如
static <T> List<T> synchronizedList(List<T> list)
我们完全可以利用类似方法来实现基本的线程安全集合:
List list = Collections.synchronizedList(new ArrayList());
它的实现,基本就是将每个基本方法,比如get、 set、 add之类,都通过synchronizd添加基本的同步支持,非常简单粗暴,但也非常实用。注意这些方法创建的线程安全集合,都
符合迭代时fail-fast行为,当发生意外的并发修改时,尽早抛出ConcurrentModifcationException异常,以避免不可预计的行为。
另外一个经常会被考察到的问题,就是理解Java提供的默认排序算法,具体是什么排序方式以及设计思路等。
这个问题本身就是有点陷阱的意味,因为需要区分是Arrays.sort()还是Collections.sort() (底层是调用Arrays.sort());什么数据类型;多大的数据集(太小的数据集,复杂排
序是没必要的, Java会直接进行二分插入排序)等。
对于原始数据类型,目前使用的是所谓双轴快速排序( Dual-Pivot QuickSort),是一种改进的快速排序算法,早期版本是相对传统的快速排序,你可以阅读源码。
而对于对象数据类型,目前则是使用TimSort,思想上也是一种归并和二分插入排序( binarySort)结合的优化排序算法。 TimSort并不是Java的独创,简单说它的思路是查找
数据集中已经排好序的分区(这里叫run),然后合并这些分区来达到排序的目的。
另外, Java 8引入了并行排序算法(直接使用parallelSort方法),这是为了充分利用现代多核处理器的计算能力,底层实现基于fork-join框架,当处理的数据集比较小的时候,差距不明显,甚至还表现差一点;但是,当数据集增长到数万或百万以上时,提高就非常大了,具体还是取决于处理器和系统环境。
对比Hashtable、 HashMap、 TreeMap有什么不同?
典型回答
Hashtable、 HashMap、 TreeMap都是最常见的一些Map实现,是以键值对的形式存储和操作数据的容器类型。
Hashtable是早期Java类库提供的一个哈希表实现,本身是同步的, 不支持null键和值 ,由于同步导致的性能开销,所以已经很少被推荐使用。
HashMap是应用更加广泛的哈希表实现,行为上大致上与HashTable一致,主要区别在于HashMap不是同步的,支持null键和值等。通常情况下, HashMap进行put或者get操作,可以达到常数时间的性能,所以它是绝大部分利用键值对存取场景的首选,比如,实现一个用户ID和用户信息对应的运行时存储结构。
TreeMap则是基于红黑树的一种提供顺序访问的Map,和HashMap不同,它的get、 put、 remove之类操作都是O(log(n))的时间复杂度,具体顺序可以由指定
的Comparator来决定,或者根据键的自然顺序来判断。
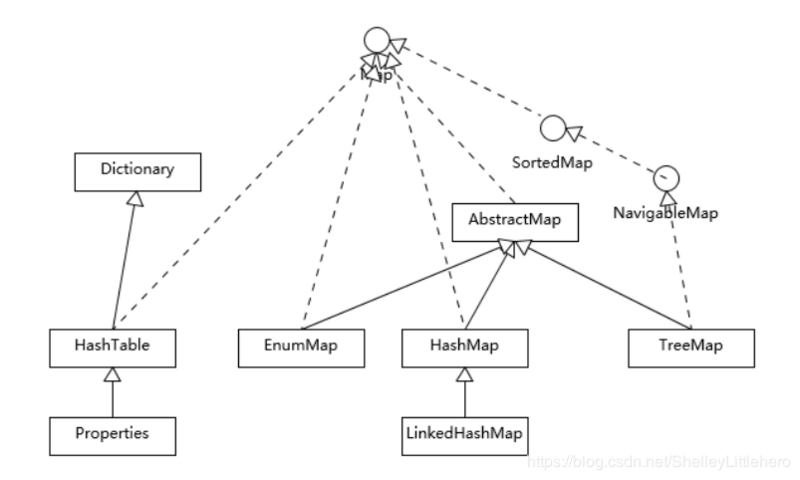
LinkedHashMap通常提供的是遍历顺序符合插入顺序,它的实现是通过为条目(键值对)维护一个双向链表。注意,通过特定构造函数,我们可以创建反映访问顺序的实例,所
谓的put、 get、 compute等,都算作“访问”。
对于TreeMap,它的整体顺序是由键的顺序关系决定的,通过Comparator或Comparable(自然顺序)来决定。
HashMap:
而对于负载因子,我建议:
- 如果没有特别需求,不要轻易进行更改,因为JDK自身的默认负载因子是非常符合通用场景的需求的。
- 如果确实需要调整,建议不要设置超过0.75的数值,因为会显著增加冲突,降低HashMap的性能。
- 如果使用太小的负载因子,按照上面的公式,预设容量值也进行调整,否则可能会导致更加频繁的扩容,增加无谓的开销,本身访问性能也会受影响。
那么,为什么HashMap要树化呢?
本质上这是个 安全 问题。 因为在元素放置过程中,如果一个对象哈希冲突,都被放置到同一个桶里,则会形成一个链表,我们知道链表查询是线性的,会严重影响存取的性能。而在现实世界,构造哈希冲突的数据并不是非常复杂的事情,恶意代码就可以利用这些数据大量与服务器端交互,导致服务器端CPU大量占用,这就构成了哈希碰撞拒绝服务攻击,国内一线互联网公司就发生过类似攻击事件。
Hashtable、 HashMap、 TreeMap比较:
三者均实现了Map接口,存储的内容是基于key-value的键值对映射,一个映射不能有重复的键,一个键最多只能映射一个值。
(1) 元素特性
HashTable中的key、 value都不能为null; HashMap中的key、 value可以为null,很显然只能有一个key为null的键值对,但是允许有多个值为null的键值对; TreeMap中当未实现Comparator 接口时, key 不可以为null;当实现 Comparator 接口时,若未对null情况进行判断,则key不可以为null,反之亦然。
(2)顺序特性
HashTable、 HashMap具有无序特性。 TreeMap是利用红黑树来实现的(树中的每个节点的值,都会大于或等于它的左子树种的所有节点的值,并且小于或等于它的右子树中的所有节点的
值),实现了SortMap接口,能够对保存的记录根据键进行排序。所以一般需要排序的情况下是选择TreeMap来进行,默认为升序排序方式(深度优先搜索),可自定义实现Comparator接口
实现排序方式。
(3)初始化与增长方式
初始化时: HashTable在不指定容量的情况下的默认容量为11,且不要求底层数组的容量一定要为2的整数次幂; HashMap默认容量为16,且要求容量一定为2的整数次幂。
扩容时: Hashtable将容量变为原来的2倍加1; HashMap扩容将容量变为原来的2倍 。
(4)线程安全性
HashTable其方法函数都是同步的(采用synchronized修饰),不会出现两个线程同时对数据进行操作的情况,因此保证了线程安全性。也正因为如此,在多线程运行环境下效率表现非常低下。因为当一个线程访问HashTable的同步方法时,其他线程也访问同步方法就会进入阻塞状态。比如当一个线程在添加数据时候,另外一个线程即使执行获取其他数据的操作也必须被阻塞,大大降低了程序的运行效率,在新版本中已被废弃,不推荐使用。
HashMap不支持线程的同步,即任一时刻可以有多个线程同时写HashMap;可能会导致数据的不一致。如果需要同步(1)可以用 Collections的synchronizedMap方法;(2)使用ConcurrentHashMap类,相较于HashTable锁住的是对象整体, ConcurrentHashMap基于lock实现锁分段技术。首先将Map存放的数据分成一段一段的存储方式,然后给每一段数据分配一把锁,当一个线程占用锁访问其中一个段的数据时,其他段的数据也能被其他线程访问。 ConcurrentHashMap不仅保证了多线程运行环境下的数据访问安全性,而且性能上有长足的提升。
(5)一段话HashMap
HashMap基于哈希思想,实现对数据的读写。当我们将键值对传递给put()方法时,它调用键对象的hashCode()方法来计算hashcode,让后找到bucket位置来储存值对象。当获取对象时,通过键对象的equals()方法找到正确的键值对,然后返回值对象。 HashMap使用链表来解决碰撞问题,当发生碰撞了,对象将会储存在链表的下一个节点中。 HashMap在每个链表节点中储存键值对对象。当两个不同的键对象的hashcode相同时,它们会储存在同一个bucket位置的链表中,可通过键对象的equals()方法用来找到键值对。如果链表大小超过阈值(TREEIFY_THRESHOLD, 8),链表就会被改造为树形结构。
正文到此结束
- 本文标签: 锁 cglib 翻译 queue 安全 回答 需求 value 字节码 spring build https IO 数据 ConcurrentHashMap App volatile Proxy 编译 删除 cat 本质 代码 JVM key 同步 db 图片 开发者 HashTable CTO 并发编程 JDBC 服务器 http 互联网 id 多线程 equals Collections Java类 并发 tab 处理器 UI HashMap 空间 开发 synchronized update src 线程 AOP 管理 ArrayList 实例 final 缓存 源码 Atom map 集合类 时间 list java反射 java lib Collection IDE LinkedList 遍历
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

