吉利汽车的监控平台建设之路

作者 | 田晓旭
嘉宾 | 詹文君
监控平台是很多公司最重要的基础设施之一。之前我们介绍了很多互联网公司的监控平台建设,现在我们想带大家了解一下传统公司监控平台的建设,本文我们采访了吉利汽车集团基础架构经理詹文君。

吉利汽车集团基础架构经理詹文君
据了解,吉利汽车的运维团队大约有 100 人,包括一线、二线、三线以及桌面团队。大部分团队成员是解决传统运维问题,保障业务的稳定性和可用性,而詹文君所在的团队更多的是在做能力建设。目前在建设的平台共有 3 个,分别是自动化运维平台、监控平台以及备份平台。
吉利汽车的监控平台
吉利汽车监控平台是从 2015 年开始大范围去推广的,整个平台建设与其它公司类似,从底层到上层分别包括基础设施的监控、操作系统主机的监控、基于中间件的环境监控(例如在数据库层面的缓存、消息、中间件监控)、应用监控、面向用户和应用性能的监控。
整个监控平台每月新增的监控告警数据大约为 2-3 个 TB,日志数据每天的增量为 500G。
与其它互联网公司相比,詹文君认为传统企业运维有两大特点:一是历史包袱比较重,无论是技术架构还是功能架构都可能出现不一样的情况;二是使用的技术组件种类繁多,例如,编程语言可能会用到 Delphi、C 语言,操作系统可能会用到 Windows XP、DOS 系统等。
由于存在一定的历史包袱,詹文君表示他们的监控平台无法做到全部标准化,所以是根据业务的重要程度来逐步完成标准化,对此,他引用了一个比喻说:“就像是驾驶一辆破损的飞机,一边修一边到达目的地。”针对通用性的东西,例如安装路径、进程、命名规范等,在不对业务产生太大影响的情况下,詹文君团队的做法是将其做成标准化。而针对定制化、个性化的东西,詹文君团队会根据差异选择小众工具去解决。
以主机监控为例,吉利汽车运维团队主要采用的是开源 Zabbix,并且是先在核心运维系统上推广。不可避免的遇到了操作系统及中间件等监控标准化问题,例如进程监控就出现同一组应用,进程启动的路径不相同,类似这样的问题比比皆是。针对这类情况,他们会根据实际情况制定通用性的监控标准,新的项目统一采用新标准,涉及到特殊历史时期遗留下来的非标监控,采用逐步淘汰或架构大调整时解决。而面向应用性能监控,他们尝试使用过开源的应用监控方案产品来解决,但是应用监控技术门槛相对较高,对应用的侵入性更强,为保障业务系统的稳定性,提高监控的准确度。最终采用商业的 Dynatrace 解决方案。例如吉利汽车内部有一个核心应用的做法是:应用的入口是统一的 URL,通过判断 action 值来决定调用哪个方法,开源的应用监控方案无法解决此类问题。
监控平台的分层体系
吉利汽车的整个监控平台可以分为两个部分,一部分面向经销商和用户,另一部分偏向于企业内部的管理系统。
这两个系统对架构和可行性的要求都有所不同。企业内部管理系统的结构比较简单,如果分层来看的话,从前端进来之后(通常是通过硬件 F5 或者是 SOA),直接就到了应用端,再往下就是数据库层。要是稍微复杂的架构,在数据库层之间可能会增加缓存;而面向经销商和用户的系统,因为要从内部网络暴露给外部用户使用,所以整体采用了服务化的框架。
在整个平台建设过程中,吉利企业也有很多自研的技术和产品。例如在技术方面,吉利汽车基于 Spring 装了一套服务化框架。而在产品方面,据詹文君介绍,吉利汽车内部 80% 的 IT 应用系统都是自研的,以 ERP 系统为例,最早吉利汽车的 ERP 系统使用的是 SAP,但出于 License 和安全性的考虑,吉利汽车开始逐步自研 SAP 的边缘系统,并与 SAP 做集成,目前 SAP 在吉利汽车内部更多的是在服务核心的财务系统。
建设过程
吉利汽车的监控平台建设可以分为 3 个阶段:
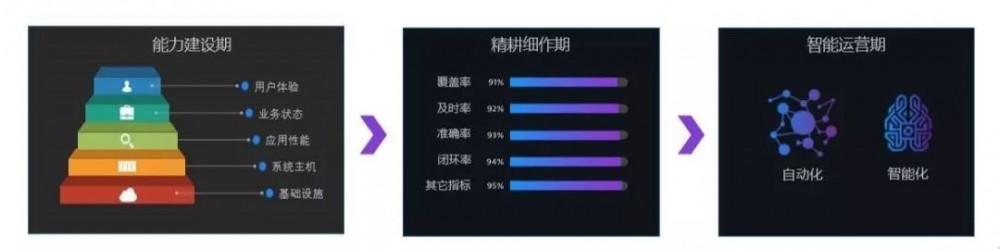
第一阶段是能力建设期。2017 年到 2019 年,这个阶段属于补短板的阶段,当时吉利汽车在一些垂直监控领域,比如网络监控、主机监控、数据库监控、应用监控等方面覆盖面相对匮乏所以需要尽快把监控工具构建起来、扩大监控覆盖面。
第二个阶段是精耕细作期。2020 年到 2021 年,这个阶段的重要标志就是构建集中监控平台和统一告警平台。监控工具和对象监控引入之后,监控的准确度、覆盖率、告警的及时性,都需要不停的运营和调整。这个调整的周期是一个持续的过程,很难在项目建设阶段完成。
第三个阶段是智能运营期,尝试利用 AI、大数据以及智能技术来辅助运营。
詹文君强调,只有前面的能力达到了,工具用好了,才能大胆的去谈自动化、智能化。因此吉利汽车在整个监控体系建设中选择用 Dynatrace 来实现三个软件智能场景:第一是用来排除故障,第二是应用性能检测,第三做瓶颈定位。
故障报警设置
故障报警是监控平台的重要组成部分,如何合理的设置报警量是个很有学问的工作。据了解,Google SRE 每周只有十条报警,如果超过十条,就说明没有把无效报警过滤掉(Google SRE 仅负责 SLA 要求为 99.99% 的服务)。而詹文君所在的团队,由于人员和精力有限,所以更多的会关注灾难级报警,而对一些 Warning 报警不会过多关注,一周报警量大概会有 180-190 条左右。
报警的颗粒度是很难掌握的,因此,詹文君表示他们会在精耕细作阶段不断优化,让报警变得更可信。但是监控平台并不能完全支持报警的所有工作,例如报警去重和消噪。有些工具可能只关注于监控数据采集,但是并不关注报警本身的处理,如主流的 Prometheus、小米开源的 Open-Falcon 等等。比如告警消噪, A 点到 B 点的网络连接中断,可能会造成范围性的报警, 需要我们通过上层告警平台,以 CMDB 数据为支撑来进行告警消噪。
未来发展
在提到未来发展时,詹文君表示:“我们特别想在容器方面有所进展。汽车行业和传统制造业都面临一个共性问题,那就是历史包袱比较重,业务架构很难去推动,改造,很难实现标准化,而容器刚好可以解决这些问题。如果标准化没有实现,就去谈自动化运维,可能蓝图描绘得非常好,但落地会很困难。”
“除了标准化,数据孤岛也是一个亟需解决的问题。从监控层面来看,如果数据不是互通的,或者在互通过程中是不标准的,比如订单在 A 系统是以“1”这种方式来存单的,而到了 B 系统是以“1.0”方式来存储的话,那么就很难实现监控。无论是应用监控、性能监控、还是资源监控,其实都属于技术监控,而业务部门真正想看的是交易情况到底如何?有多少用户本应付款但实际没有付?有多少付款失败是因为 IT 问题导致的?...... 将技术监控和业务监控结合在一起,能够减少很多技术与业务之间的矛盾。”
嘉宾介绍
詹文君 ,吉利汽车集团基础架构经理,推动吉利汽车集团监控和运维平台建设,不断完善监控和运维体系,为业务稳定高效运行保驾护航。
活动推荐
监控报警是故障发现的重要一环,也是百度在AIOps方向的第一个切入方向,目前百度AIOps在监控报警方面已经孵化出两个应用场景:智能异常检测和智能报警合并。
本次分享两位百度资深研发工程师将重点介绍百度监控告警系统在落地AIOps过程中遇到的架构挑战以及相应的解决方案。了解更多可点击【 阅读原文 】
9折购票开始啦,限时立减 880 元, 团购 更便宜哦~有任何问题可直接联系票务经理灰灰:15600537884 (同微信)。

正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

