通过Amazon Machine Learning建立一个数值回归模型
实际生产中,业务经常会碰到预测未来值的情况。预测可以帮助进行更好的资源规划及业务决策制定。通常情况下,鉴于无法承受如数值回归等复杂模型所带来的开销,机构安于使用过去一阶段平均值并附加一些假想变化这种廉价的模式。
本篇博文以自行车租赁程序为例,预测一个特定城市每个小时的自行车需求。在这个情景中,你需要机器学习模型来基于一组特征(或者predictor)来预测一个值。在这里,你将基于 Kaggle上开放的一些数据来建立一个回归模型。通过学习建立这个模型,你可以在自己的场景中应用自己的机器学习。
分析和机器学习的区别
自行车租赁程序可以很好地描述分析系统在做精准预测时的限制所在。Kaggle参赛者之一建立了下面这个网页来分析所提供的数。如果你点击Plots标签,你可以看到一个使用R建立的数据可视化。Shiny是一个很流行的免费分析软件,同时也是R非常流行的一个网络接口,详情访问View Bike Sharing Demand页面。

这张图显示了工作日与假期中人们对自行车的不同需求,峰值时间是8点和17点。同时,你还可以做一些更深度的挖掘,比如对比注册用户和游客的不同。数据可视化显示了临时用户更喜欢在周末和周一租车,而注册用户则更喜欢在工作日租车。
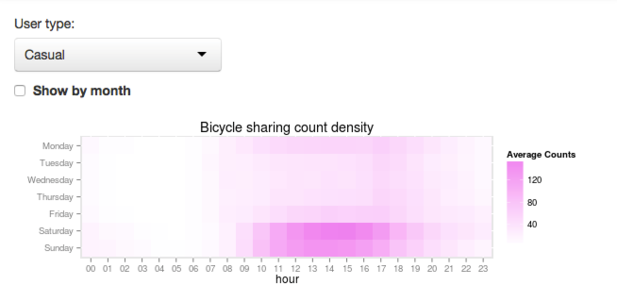
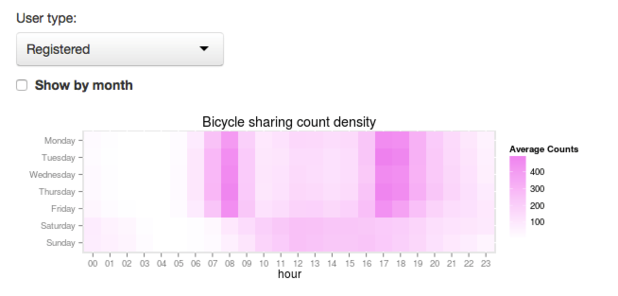
这也就是说,通过上面的可视化操作,你可以预测自行车租赁服务的使用率。然而,在这之外,是否还有其他因素影响着预测结果?比如天气、假日等。在加入这些附加因素后,预测将变得异常复杂,这也就是我们转向机器学习的原因。
为建立机器学习模型准备数据
如果想建立一个成功的机器学习模型,首先你需要找到合适的数据。其核心思想就是“Garbage-In-Garbage-Out”(或者“Gold-In-Gold-Out”,取决于你的看法”)。在特征识别过程中,专业知识可以帮助你判定是否要针对某个特征进行训练。
在上面的例子中,你看到了工作日和周末对结果产生了重要的影响。在自行车使用上,你同样看到了天气的影响重大,下雨或者冷空气来袭时,人们可能很少租车。我们可以很简单的取得历史天气信息,以及未来几日的天气预报。Kaggle上的竞赛组织者准备了以下的一些数据:
datetime - hourly date + timestamp season - 1 = spring, 2 = summer, 3 = fall, 4 = winter holiday - whether the day is considered a holiday workingday - whether the day is neither a weekend nor holiday weather - 1: Clear, Few clouds, Partly cloudy, Partly cloudy 2: Mist + Cloudy, Mist + Broken clouds, Mist + Few clouds, Mist 3: Light Snow, Light Rain + Thunderstorm + Scattered clouds, Light Rain + Scattered clouds 4: Heavy Rain + Ice Pallets + Thunderstorm + Mist, Snow + Fog temp - temperature in Celsius atemp - "feels like" temperature in Celsius humidity - relative humidity windspeed - wind speed casual - number of non-registered user rentals initiated registered - number of registered user rentals initiated count - number of total rentals
列表最下方显示了你需要预测的3个数字:临时用户租赁的数量,注册用户租赁的数量,以及租赁的总数量。鉴于总数量是前两个数字之和,同时你也清楚临时用户和注册用户的行为区别,你需要分别建立两个不同的模型进行预测。
你可以使用不同的工具来处理CSV文件的列,比如Microsoft Excel或者RStudio IDE,它们在数据科学家群体中非常流行。在本篇博文中,你将使用cut、sed和awk来维护数据。
首先需要做的就是对训练数据的行进行shuffle,从而移除数据中任何可能存在的顺序,它们都可能让机器学习模型产生偏差。
# shuffle the lines except for the first header line tail -n+2 train.csv | gshuf -o BikeShareTrainData.csv # Add the header line from the original file as the first line of the shuffled file head -1 train.csv | cat - BikeShareTrainData.csv > temp && mv temp BikeShareTrainData.csv
为了给预测临时用户租赁建立一个训练数据模型,你需要去掉原始训练数据文件的最后两列(registered和count)。在一个为临时用户新建立的数据文件中使用cut和定界符“,”来存储前10个字段:
cat BikeShareTrainData.csv | cut -d',' -f1-10 > BikeShareCasualTrainData.csv
为注册用户预测重复相同的步骤,通过去掉第十个字段(casual)保留第十一个字段(registered):
cat BikeShareTrainData.csv | cut -d',' -f1-9,11 > BikeShareRegisteredTrainData.csv
为了训练这个模型,你需要将文件上传到Amazon S3。在与训练模型运行的AWS region中建立一个bucket,并使用AWS CLI将数据拷贝到这个bucket中。
aws s3 cp BikeShareCasualTrainData.csv s3://<BUCKET_NAME>/ML/input/ --region us-east-1 aws s3 cp BikeShareRegisteredTrainData.csv s3://<BUCKET_NAME>/ML/input/ --region us-east-1
在后续的预测中,请确保你已经移除了你不需要的数据。举个例子,如果你没有移除训练数据中的 casual和registered 字段并预测计数变量,那么模型将变得非常简单,它会简单地把两个变量相加,然后忽视天气和其他feature。
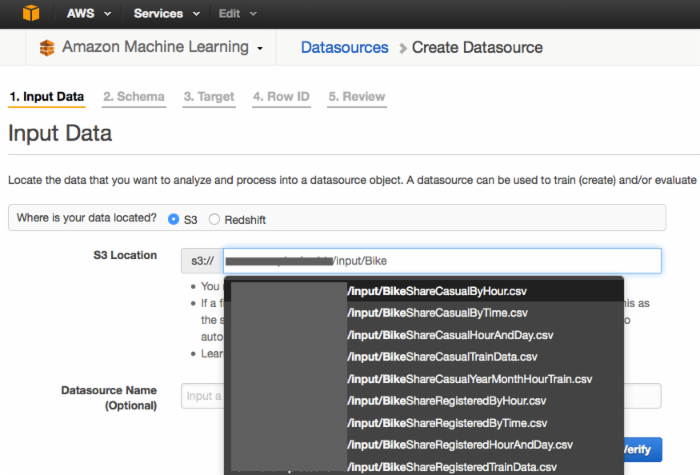
在Amazon ML控制台,将数据源指向你刚上传到Amazon S3的训练数据。随后,为数据定义和优化一个模式。
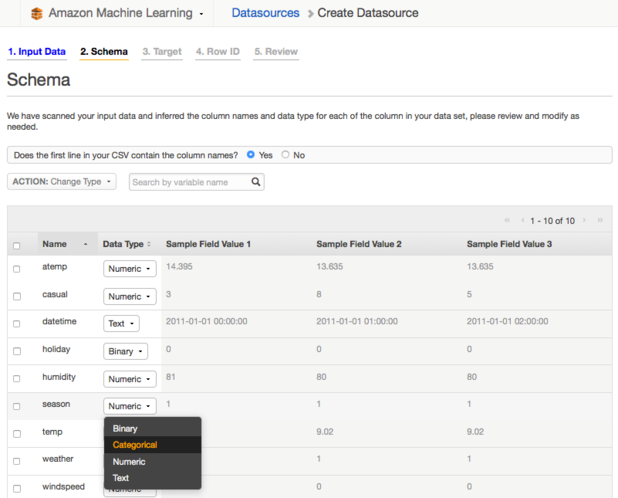
填写season变量,由数字来表示季节(比如春天为1,夏天为2),同时在数据类型中将其标识为类别而非数值。数值变量拥有一个值来描述可被数字度量的量,比如“how many或者how much”。如果你清楚某个特殊的数字代表的不是量,那么在数据类型中将其定义为category 类型更好些。下一步,选择机器学习模型需要预测的目标:
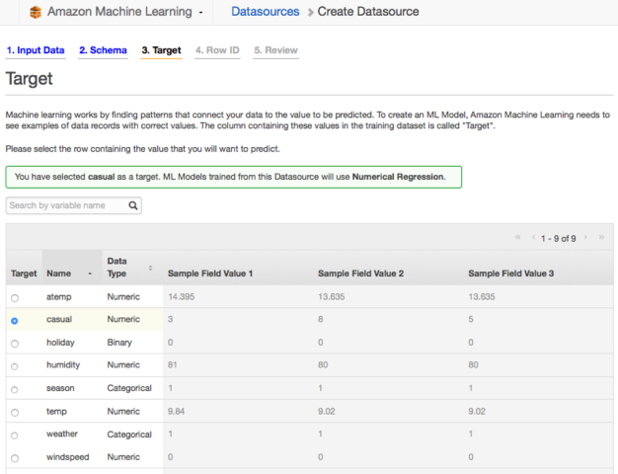
在这个模型中,选择casual变量作为预测目标。服务会将识别成一个数字,并提示它会使用数值回归。在下个界面中选择默认配置,并开始建立流程。建立流程需要花费数分钟的时间,具体时间取决于数据的大小。在后续工作中,你可能发现很多更好的途径来建立模型,但是对于新手来说使用简单和默认的选项显然更好一些。
评估机器学习模型
模型被建立后,你就可以对其进行评估;如果你使用了简单和默认的途径创建流程,那么评估将自动进行。使用非训练数据来测试模型评估非常重要。默认的简单模式下,Amazon ML通过对数据进行随机划分完成这个步骤,70%的数据用来训练,余下的进行评估。当然,你可以根据自己的需求对数据进行划分。
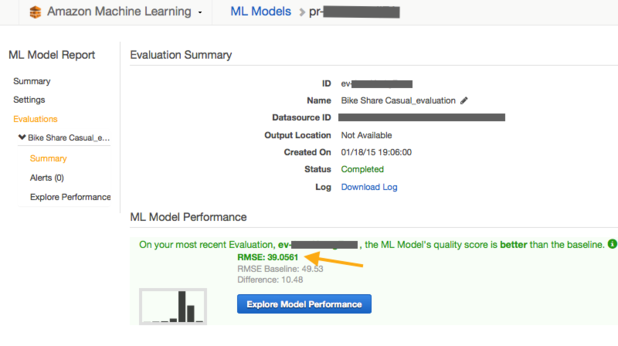
模型的评估结果会产生numeric value 和一个可视化图表。对于一个数值回归来说,numeric value也就是均方根误差(RMSE)。在这里,RMSE数值越小,预测产生的误差就越小,也就代表建立的模型越合适。在这个例子中,取平均值得到的RMSE是49,而数值回归的RMSE是39。
同时,你同样可以评估每个变量对预测目标的影响(temp、windspeed、working day等等):在这个例子中,就是临时或者注册用户租赁。
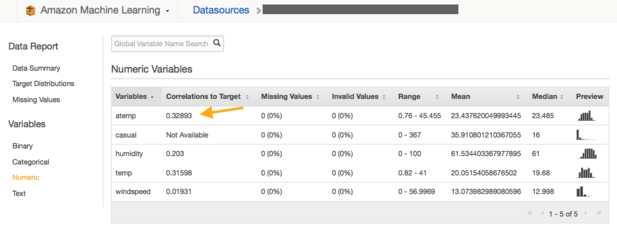
如图中所示,值越高越有帮助产生更好的预测结果。在这个例子中,对于临时用户来说,atemp(类似温度)拥有一个0.32的值,而风速的影响只是0.01。而有意思的是,datatime也占一个0.21比重。

mazon同样可以分析文本字段,提取类似01、02、03等标记作为模型的预测因子。
现在,你可以决定是使用原始模型,还是通过获得更低的RMSE来对其进行提升。现在,你就可以从datetime中抽取hour(特征抽取操作),随后服务会议一个合适的方式来完成这个操作。以此类推,你也可以从week或者month中抽取day。下面是一个示例脚本,它会将某周中的某天加入变量,并将它复制到临时用户训练集:
每个特征的转换都可能潜在地提升模型精度,因此专家可以识别出究竟需要增加哪个变量。
awk 'NR>1{system("date -j -f /"%Y-%m-%d/" " $1 " +%A")}' BikeShareTrain.csv > BikeShareTrainDoW.csv paste -d "," BikeShareTrainDoW.csv BikeShareCasualTrain.csv > BikeShareCasualDoW.csv 使用ML模型进行批预测
在得到了所需模型后,你可以开始使用它来进行预测。当规模大或者实时性要求较高时,我们可以进行批预测。
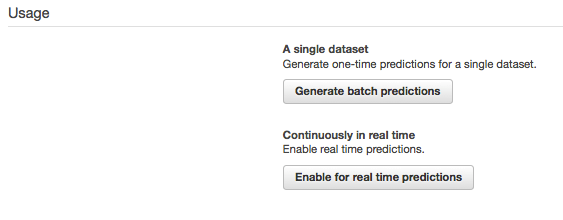
在作业结束后,通常是数分钟,下载批预测产生的结果。在提交结果之前,对所有预测值(临时+注册)进行求和以获得每个小时需要出租的自行车总量。
你可以通过下述代码进行:
paste casual_batch.out registered_batch.out | awk '$1+$2>0 {print int($1 + $2); next} {print "0"}' > bike_share_sub_test.csv 通过AWS ML,我们可以在数分钟内完成比以前计算平均值更好的结果。想学习更多Amazon ML的知识,请访问Amazon ML Developer Guide。
原文链接: https://blogs.aws.amazon.com/bigdata/post/Tx2OZ63RJ6Z41A0/Building-a-Numeric-Regression-Model-with-Amazon-Machine-Learning
活动推荐 : AWSome Day—让您大有作为(北京站)
活动推荐: 5月12日 AWS 动手实验课堂系列:DynamoDB使用技巧
 订阅“AWS中文技术社区”微信公众号,实时掌握AWS技术及产品消息!
订阅“AWS中文技术社区”微信公众号,实时掌握AWS技术及产品消息!
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

