2w字长文,让你瞬间拥有「调用链」开发经验

原创:小姐姐味道(微信公众号ID:xjjdog),欢迎分享,转载请保留出处。
很多同学表示,对于微服务中常用的调用链功能的原理,感觉很模糊。 本文将真正的从零开始,介绍调用链客户端开发的一些要点 。让你瞬间拥有APM开发经验。文章很长很长,照例看一下相关目录。

随着微服务架构的流行,一次请求往往需要涉及到多个服务,因此服务性能监控和排查就变得非常复杂。为了发现和治理这种依赖关系,APM因此而生。
目前,市面上的APM服务端已经有了非常多的实现。比如 Zipkin 、 Jaeger 、 SkyWalking 、 Elastic APM 等(Pinpoint并不支持OpenTracing,所以我们不介绍)。
本教程会提供一些开发思路,从源码层面,解析开发成本。本次选择Jaeger作为服务端示例(选其他没什么区别),涉及的知识比较多,所以首先介绍一下其中的内容。
温馨提示。本文的代码仓库,参见:
https://github.com/xjjdog/example-jaeger-tracing
主要内容
首先,我们来看一下 apm 的关键信息和一些概念性的东西,为后面的示例做准备。在这里,我们简单的描述了jaeger是如何安装的,并做一些准备工作。
接下来,使用一个简单的 java 程序,来说明如何使用OpenTracing api进行trace的生成,并演示一个带有二个节点的调用链生成。同时,介绍一下大流量下的trace 采样 策略。
然后,使用OkHttp3和SpringBoot,来演示如何实现一个分布式调用。本文依然是使用底层的api进行构建,有良好素养的开发,应该能够触类旁通,应用于任何场景。
最后,以SpringCloud为例,说明微服务的调用链生成逻辑。由于各种调用内容较多,我们仅以比较流行的Feign调用来说明其原理。
如果你在开发自己的中间件,或者做一些集成性的工作,本教程能够让你快速给自己的组件加入apm功能。前提是,你的api需要兼容OpenTracing协议。
1、整体介绍
对于整个监控体系,xjjdog有一篇比较全面的介绍,包括监控,日志和apm各自的定位。详见: 《这么多监控组件,总有一款适合你》 。对于其他的APM,也介绍过一篇《这一轮,skywalking胜出》。那么到底APM在企业服务中处于什么位置呢?可参见 《微服务不是全部,只是特定领域的子集》 一文。
1.1、主要开发内容
一个APM的开发工作会有很多,大体可以分为以下三部分。
数据收集部分
主要用于多样化的数据收集,为数据分析做准备。要求易用好用侵入尽量小(开发工作量),并且在极端情况下(如收集组件不可用)不能对业务有任何影响。可以看到此部分的开发量是巨大的,尤其是需要集成Nginx上下游、基础组件多样、技术栈多样的情况下。
数据分析部分
主要有实时分析与线下分析。一般,实时分析的价值更大一些,主要产出如秒级别的调用量、平均响应时间、TP值等。另外,调用链(Trace)需要存储全量数据,一些高并发大埋点的请求,会有性能问题。
监控报警
此部分利用数据分析的产出,通过短信邮件等形式,通知订阅人关注。监控报警平台应尽量向devops平台靠拢,包括自主化服务平台。
1.2、为什么选用jaeger
jaeger的开发较为活跃,而且它的模块划分是比较灵活的。在数据量非常大的情况下,数据是可以先用kafka缓冲一下的(同时为接入各种流分析平台做足了准备)。这些内容,我们在jaeger安装的部分顺便说明。
1.3、如何使用SpringBoot扩展功能
如果你的项目使用了SpringBoot,是非常方便进行扩展的。
我们接下来实现的功能是:任何加了 @OwlTrace 注解的方法,都将产生一条调用链信息。
首先,我们要定义一个注解:
import java.lang.annotation.*;
@Target({ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface OwlTrace {
}
然后,实现其处理类。代码通过 AOP 对Spring管理的Bean进行拦截,非常简单的实现了 Trace 信息的构造。代码如下:
import io.opentracing.Span;
import io.opentracing.Tracer;
import io.opentracing.tag.Tags;
import lombok.extern.slf4j.Slf4j;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.Around;
import org.aspectj.lang.annotation.Aspect;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Lazy;
import java.util.LinkedHashMap;
import java.util.Map;
@Configuration
@Slf4j
public class OwlTraceAutoConfiguration {
static final String TAG_COMPONENT = "java";
@Autowired
@Lazy
Tracer tracer;
@Bean
public TracingAspect pxTracingAspect() {
return new TracingAspect();
}
@Aspect
class TracingAspect {
@Around("@annotation(com.sayhiai.arch.trace.annotation.OwlTrace)")
public Object pxTraceProcess(ProceedingJoinPoint pjp) throws Throwable {
Span span = null;
if (tracer != null) {
final String cls = pjp.getTarget().getClass().getName();
final String mName = pjp.getSignature().getName();
span = tracer.buildSpan(cls + "." + mName)
.withTag(Tags.COMPONENT.getKey(), TAG_COMPONENT)
.withTag("class", cls)
.withTag("method", mName)
.startActive(false)
.span();
}
try {
return pjp.proceed();
} catch (Throwable t) {
Map<String, Object> exceptionLogs = new LinkedHashMap<>(2);
exceptionLogs.put("event", Tags.ERROR.getKey());
exceptionLogs.put("error.object", t);
span.log(exceptionLogs);
Tags.ERROR.set(span, true);
throw t;
} finally {
if (tracer != null && span != null) {
span.finish();
}
}
}
}
}
最后,根据 Spring 的加载方式,将路径添加到 src/main/resources/META-INF/spring.factories 中:
org.springframework.boot.autoconfigure.EnableAutoConfiguration=/ arch.trace.core.owl.OwlTraceAutoConfiguration,/ arch.trace.core.log.LoggingAutoConfiguration
将组件打成 jar 包,一个 spring boot starter 就实现了。
使用
在application.properties文件中,确保打开了 AOP
# AOP spring.aop.auto=true spring.aop.proxy-target-class=true opentracing.jaeger.log-spans=true opentracing.jaeger.udp-sender.host=192.168.3.237 opentracing.jaeger.udp-sender.port=5775
接下来,我们将逐步进入客户端api的开发之中。
2、安装jaeger
支持 OpenTracing 的 server 端有很多,我们总要选一个 。在这里,选用 jaeger 。 jaeger 的开发较为活跃,支持的客户端实现也较多。由于采用了 golang 开发,发行包也比较简洁。
jaeger的官网是
https://www.jaegertracing.io/
2.1、 jaeger介绍
特点
jaeger的开发语言是`golang` jaeger支持OpenTracing协议,同属于CNCF基金会 jaeger支持各种各样的客户端,包括Go、Java、Node、Python、C++等 jaeger支持udp协议传输,当然也支持http
jaeger能够解决以下问题
分布式事务监控 性能分析与性能优化 调用链,找到根源问题 服务依赖分析(需大数据分析)
安装需了解的技术栈
OpenTracing Golang ElasticSearch Kafka (可选)
2.2、安装jaeger
jaeger是二进制发行包,使用wget下载即可,这里以linux版本为例。
wget -c https://github.com/jaegertracing/jaeger/releases/download/v1.11.0/jaeger-1.11.0-linux-amd64.tar.gz
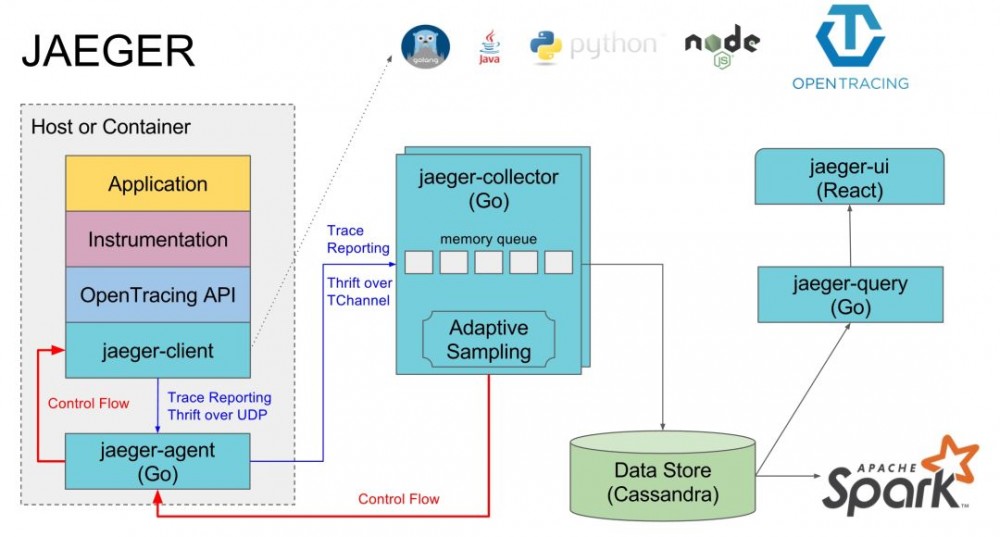
jaeger的二进制发行包包含五个二进制文件:
jaeger-agent jaeger-collector jaeger-query jaeger-standalone jaeger-ingester
如果没有执行权限,可以使用以下命令增加执行权限。
chmod a+x jaeger-*
trace数据总要存在一个地方。jaeger支持 ES 和 Canssandra 两种后端DB。国内用ES的多一点,我们就以ES为例,来介绍其安装方式。 ES请先自行安装。
由于上面四个命令都有很多参数,所以我们可以创建几个脚本,来支持jaeger的启动。
start-collector.sh
export SPAN_STORAGE_TYPE=elasticsearch nohup ./jaeger-collector --es.server-urls http://10.66.177.152:9200/ --log-level=debug > collector.log 2>&1 &
start-agent.sh
export SPAN_STORAGE_TYPE=elasticsearch nohup ./jaeger-agent --collector.host-port=10.66.177.152:14267 --discovery.min-peers=1 --log-level=debug > agent.log 2>&1 &
start-query.sh
export SPAN_STORAGE_TYPE=elasticsearch nohup ./jaeger-query --span-storage.type=elasticsearch --es.server-urls=http://10.66.177.152:9200/ > query.log 2>&1 &
部署方式
jaeger有两种部署方式。下面一一介绍。如果你的数据量特别多,使用kafka缓冲一下也是可以的(所以就引入了另外一个组件jaeger-ingester),不多做介绍。
简易环境
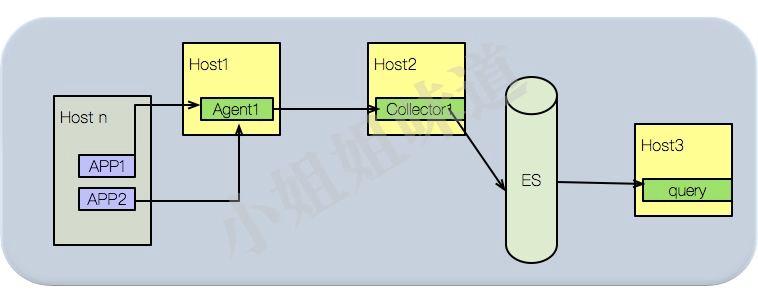 这种方式一般用在dev环境或者其他测试环境。只需要部署一个单一节点即可。我们的app,需要手动填写agent的地址,这个地址一般都是固定的。
这种方式一般用在dev环境或者其他测试环境。只需要部署一个单一节点即可。我们的app,需要手动填写agent的地址,这个地址一般都是固定的。
这些环境的流量很小,一个agent是足够的。
更加简洁的部署方式,连agent都不需要,直接向collector发送数据即可。为了方便测试,我们使用此方式。
生产环境
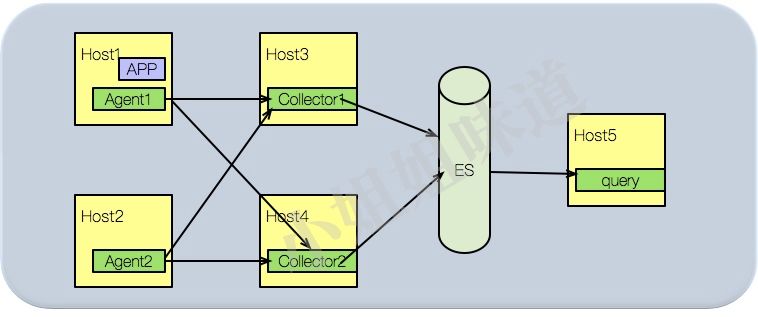 上面这种部署方式,适合生产环境。agent安装在每一台业务机器上。Client端的目标agent只需要填写localhost即可。
上面这种部署方式,适合生产环境。agent安装在每一台业务机器上。Client端的目标agent只需要填写localhost即可。
这种方式的好处是生产环境的配置非常的简单。即使你的机器是混合部署的,也能正常收集trace信息。
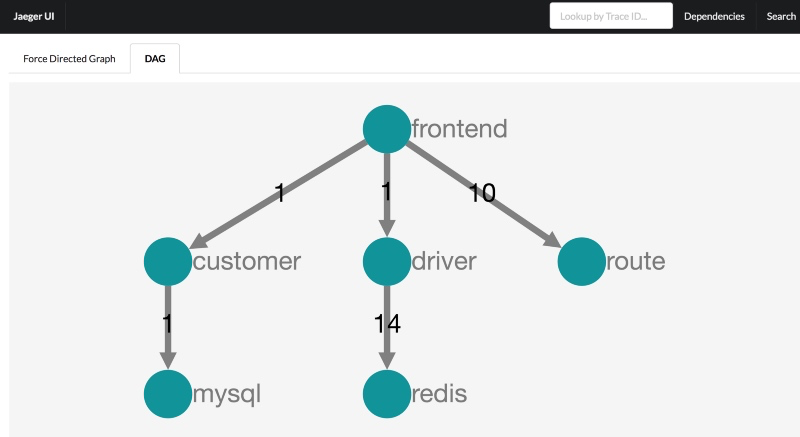
调用关系图
jaeger的调用关系图是使用spark任务进行计算的。项目地址为:
https://github.com/jaegertracing/spark-dependencies
作为一个可选部分,只有在计算完毕后,才能在jaeger的后台中进行展现。
端口整理
Agent
5775 UDP协议,接收兼容zipkin的协议数据 6831 UDP协议,接收兼容jaeger的兼容协议 6832 UDP协议,接收jaeger的二进制协议 5778 HTTP协议,数据量大不建议使用
它们之间的传输协议都是基于thrift封装的。我们默认使用5775作为传输端口。
Collector
14267 tcp agent发送jaeger.thrift格式数据 14250 tcp agent发送proto格式数据(背后gRPC) 14268 http 直接接受客户端数据 14269 http 健康检查
Query
16686 http jaeger的前端,放给用户的接口 16687 http 健康检查
至此,我们的jaeger就安装完毕。
3、编写一个HelloWorld
首先,创建一个普通maven工程。然后加入依赖:
opentracing-util 0.32.0 jaeger-client 0.35.0 logback-classic 1.2.3
主要用到了opentracing相关的jar包,而且用到了jaeger的java客户端实现。
3.1、一段简单的代码
首先创建一个简单的 loveyou 类,里面有一个简单的方法 hello 。本部分之与OpenTracing有关,与Jaeger关系并不是很大。
在 hello 方法体的前后,加入几行简单的代码,主要是根据OpenTracing规范定义的api进行一些调用信息等内容的添加。
public class LoveYou {
Tracer tracer;
public LoveYou() {
tracer = JaegerTracerHelper.initTracer("loveYouService");
}
public void hello(String name) {
Span span = tracer.buildSpan("hello").start();
span.setTag("name", name);
System.out.println("Hello " + name);
span.log("Love service say hello to " + name);
span.finish();
}
public static void main(String[] args) {
new LoveYou().hello("小姐姐味道");
}
}
代码主要加入了以下几个重要的信息。
1、构建了一个新的 span ,每个span有三个id:rootid、parentid、id。它们构成了树状调用链的每个具体节点。
2、给新加的span添加了一个 tag 信息,用来进行一些自定义标识。tag有一些标准的清单,但也可以自定义。
3、给新加的span添加了log。log信息会 附着 在信息span上,一块被收集起来,仅定义一些比较重要的信息,包括异常栈等。一些不重要的信息不建议使用log,它会占用大量存储空间。
执行代码后,可以在jaeger的ui端看到这次的调用信息。如下:
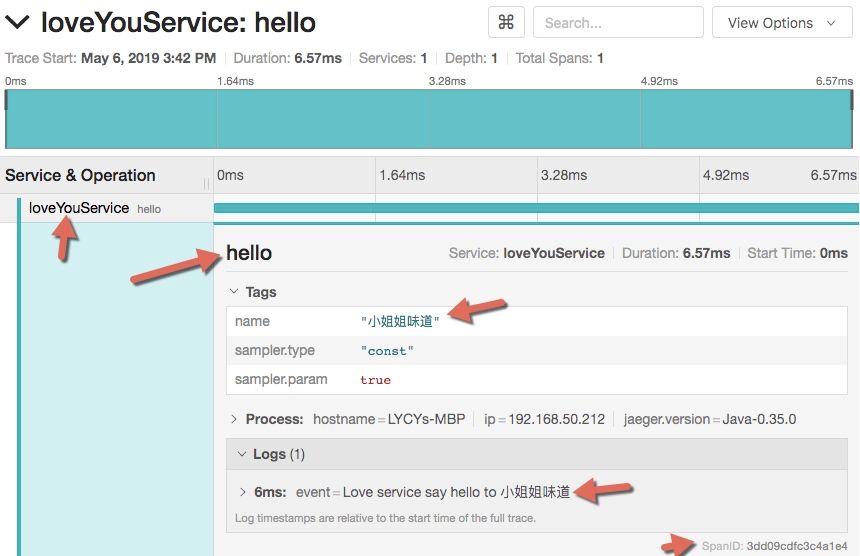
3.2、构建jaeger实现
我们的OpenTracing数据是如何构建,并发送到Jaeger的server端呢?就是通过下面的代码完成的。
public class JaegerTracerHelper {
public static JaegerTracer initTracer(String service) {
final String endPoint = "http://10.30.94.8:14268/api/traces";
final CompositeReporter compositeReporter = new CompositeReporter(
new RemoteReporter.Builder()
.withSender(new HttpSender.Builder(endPoint).build())
.build(),
new LoggingReporter()
);
final Metrics metrics = new Metrics(new NoopMetricsFactory());
JaegerTracer.Builder builder = new JaegerTracer.Builder(service)
.withReporter(compositeReporter)
.withMetrics(metrics)
.withExpandExceptionLogs()
.withSampler(new ConstSampler(true));
return builder.build();
}
}
JaegerTracer的参数很多,本篇不做详细介绍。要完成示例构建需要以下简单步骤:
1、构建Reporter,指发送到server的方式,代码中构建了一个http endpoint,越过jaeger-agent直接发送到jaeger-collector
2、构建一个Sampler,指定要收集的信息,由于本次要收集所有的信息。所以使用默认的ConstSampler
哦对了,为了便于调试和发现,代码还加入了一个LoggingReporter,用于将span输出到控制台。效果如下:

到此为止,一个简单的示例java示例九完成了。
3.3、实现一个2层深度的链
以上代码,仅产生了一个span,也就是一个方法调用。接下来,我们看一下如何完成一个多层的调用链条。
接下来还是要修改LoveYou类。我们把调用方法 hello 拆解一下,拆成 dispatch 和 hello 两个方法,并在hello方法里sleep一秒钟。
期望生成两条trace信息。
dispatch
public void dispatch(String cmd, String content) {
Span span = tracer.buildSpan("dispatch").start();
tracer.activateSpan(span);
if (cmd.equals("hello")) {
this.hello(content);
}
if (null != span) {
span.setTag("cmd", cmd);
span.finish();
}
}
hello
public void hello(String name) {
Span span = tracer.buildSpan("hello").start();
tracer.activateSpan(span);
System.out.println("Hello " + name);
try {
Thread.sleep(TimeUnit.SECONDS.toMillis(1));
} catch (InterruptedException e) {
e.printStackTrace();
}
span.setTag("name", name);
span.log("Love service say hello to " + name);
span.finish();
}
与示例一不同的是,每次生成span之后,我们还要将其激活一下
tracer.activateSpan(span);
它的目的主要是让span实例在当前的ctx里面保持活跃(比如一个线程)。这样,如果新的span判断当前有活跃的span,则将它们放在同一个 scope 中。这样,链条就串起来了。
以下是程序运行后的效果。
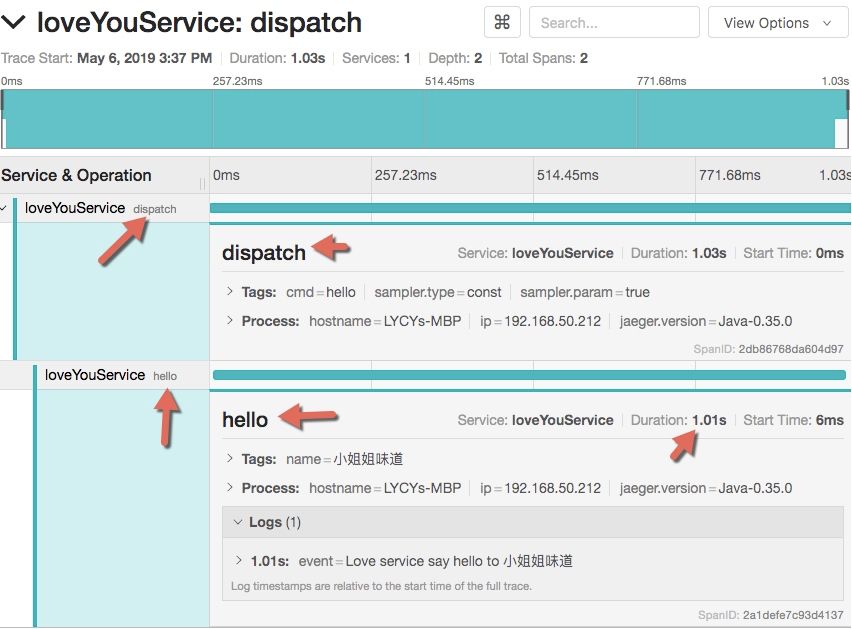
3.4、采样
有时候,我们的服务QPS非常高,瞬间能够生成大量的trace信息。这些信息是非常相近的,且会给存储产生很大的压力。
如果不需要统计一些QPS之类的信息,就可以使用sampler,仅收集部分trace。
还记得我们使用javaapi构建的jaeger实例么?其中,有这么一行代码:
.withSampler(new ConstSampler(true))
这就是最简单的 采样 ,意思是收集所有的信息。jaeger支持四种不同的采样类型。
Constant
这是一个布尔开关,如果 sampler.param=1 ,则代表收集所有的trace,如果为 0 ,则代表什么都不收集。
Probabilistic
基于概率进行采样,比如sampler.param=0.1,则代表有1/10的trace将被收集。
Rate Limiting
限流方式,使用令牌桶限流。
sampler.param=2.0
则代表每秒有2个trace被收集,超出的将被抛弃。
Remote
通过远程配置方式配置,这也是默认的方式。比如在Collector中配置 strategies.json
{
"service_strategies": [
{
"service": "foo",
"type": "probabilistic",
"param": 0.8,
"operation_strategies": [
{
"operation": "op1",
"type": "probabilistic",
"param": 0.2
},
{
"operation": "op2",
"type": "probabilistic",
"param": 0.4
}
] },
{
"service": "bar",
"type": "ratelimiting",
"param": 5
}
],
"default_strategy": {
"type": "probabilistic",
"param": 0.5
}}
通过OpenTracing的Api,可以很容易的实现调用链功能。但可以看到,由于存在各种各样的客户端,主要工作量就集中在对这些客户端的兼容上。比如线程池、SpringCloud、MQ、数据库连接池等等等等。
使用Aop可以省去一些编码和侵入,但可控制性会弱一些。
接下来,我们给一个简单的OkHttp+SpringBoot调用,也就是分布式应用,添加trace功能。
4、实现一个分布式调用
很多情况, trace 是分布在不同的应用中的,最常用的远程调用方式就是 Http 。
在这种情况下,我们通常通过增加额外的 Http Header 传递Trace信息,然后将其组织起来。
本部分通过构建一个目前最火的 SpringBoot 服务端,然后通过 OkHttp3 进行调用,来展示分布式调用链的组织方式。
需要的知识:
创建一个简单的SpringBoot应用 使用OkHttp3发起一个Post请求 了解OpenTracing的inject和extract函数
4.1、inject & extract函数
这是两个为了跨进程追踪而生的两个函数,力求寻找一种通用的trace传输方式。这是两个强大的函数,它进行了一系列抽象,使得OpenTracing协议不用和特定的实现进行耦合。
Carrier 携带trace信息的载体,下文中将自定义一个 inject 将额外的信息`注入`到相应的载体中 extract 将额外的信息从载体中`提取`出来
其实,这个载体大多数都是用一个Map(具体是text map)来实现;或者是其他二进制方式实现。
在本文中,我们就是用了text map,载体的底层就是http头信息(也可以通过request params进行传递)。
4.2、创建一个Server端
首先,通过bom方式import进spring boot的相关配置。
spring-boot-dependencies 2.1.3.RELEASE
然后,引入其他依赖
opentracing-util 0.32.0 jaeger-client 0.35.0 logback-classic 1.2.3 spring-boot-starter-web 2.1.3.RELEASE okhttp 3.14.1
创建一个SpringBoot应用,端口指定为8888,并初始化默认的 Tracer 。
@SpringBootApplication
@EnableAutoConfiguration
@ComponentScan(basePackages = { "com.sayhiai.example.jaeger.totorial03.controller",
})
public class App extends SpringBootServletInitializer {
public static void main(String[] args) {
SpringApplication.run(App.class, args);
}
@Bean
public JaegerTracer getJaegerTracer() {
return JaegerTracerHelper.initTracer("LoveYou");
}
}
在controller目录下创建一个简单的服务 /hello ,通过request body传递参数。
关键代码如下:
@PostMapping("/hello")
@ResponseBody
public String hello(@RequestBody String name,HttpServletRequest request) {
Map<String, String> headers = new HashMap<>();
Enumeration<String> headerNames = request.getHeaderNames();
while (headerNames.hasMoreElements()) {
String header = headerNames.nextElement();
headers.put(header, request.getHeader(header));
}
System.out.println(headers);
Tracer.SpanBuilder builder = null;
SpanContext parentSpanContext = tracer.extract(Format.Builtin.HTTP_HEADERS, new TextMapAdapter(headers));
if (null == parentSpanContext) {
builder = tracer.buildSpan("hello");
} else {
builder = tracer.buildSpan("hello").asChildOf(parentSpanContext);
}
Span span = builder.start();
首先拿到头信息,并进行 extract ,如果得到的 SpanContext 不为空,则代表当前的请求是另外一个应用发起的。在这种情况下,我们把请求的来源,作为当前请求的 parent 。
使用Curl进行调用,确保服务能正常运行。
curl -XPOST http://localhost:8888/hello -H "Content-Type:text/plain;charset=utf-8" -d "小姐姐味道"
4.3、创建OkHttp3客户端调用
OkHttp3是一个非常轻量级的类库,它的header信息可以通过以下代码设置。
Request.Builder builder; builder.addHeader(key, value);
我们在上面提到,将要创建一个自定义的 Carrier ,这里通过继承 TextMap ,来实现一个。
public class RequestBuilderCarrier implements io.opentracing.propagation.TextMap {
private final Request.Builder builder;
RequestBuilderCarrier(Request.Builder builder) {
this.builder = builder;
}
@Override
public Iterator<Map.Entry<String, String>> iterator() {
throw new UnsupportedOperationException("carrier is write-only");
}
@Override
public void put(String key, String value) {
builder.addHeader(key, value);
}
}
使用OkHttp3发起一个简单的Post请求即可。
public static void main(String[] args) {
Tracer tracer = JaegerTracerHelper.initTracer("Main");
String url = "http://localhost:8888/hello";
OkHttpClient client = new OkHttpClient();
Request.Builder request = new Request.Builder()
.url(url)
.post(RequestBody.create(MediaType.parse("text/plain;charset=utf-8"), "小姐姐味道"));
Span span = tracer.buildSpan("okHttpMainCall").start();
Tags.SPAN_KIND.set(span, Tags.SPAN_KIND_CLIENT);
Tags.HTTP_METHOD.set(span, "POST");
Tags.HTTP_URL.set(span, url);
tracer.activateSpan(span);
tracer.inject(span.context(), Format.Builtin.HTTP_HEADERS, new RequestBuilderCarrier(request));
client.newCall(request.build()).enqueue(new Callback() {
@Override
public void onFailure(Call call, IOException e) {
e.printStackTrace();
}
@Override
public void onResponse(Call call, Response response) throws IOException {
System.out.println(response.body().string());
}
});
span.finish();
}
注意,在方法中间,我们使用inject函数,将trace信息附着在 RequestBuilderCarrier 上进行传递。
这两个函数,使用的就是jaeger的实现。见:
io.jaegertracing.internal.propagation.TextMapCodec
运行Main方法,查看Jaeger的后台,可以看到,我们的分布式Trace已经生成了。
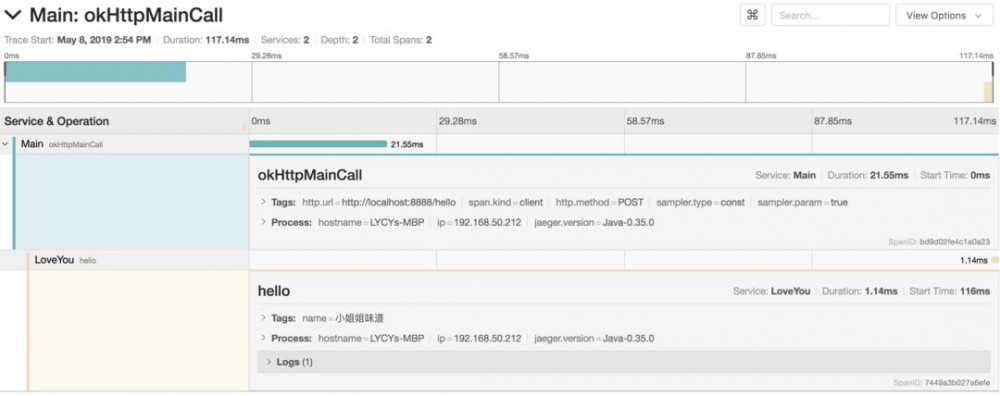 以上展示了创建分布式调用链的一般方式。类比此法,可以很容易的写出基于
以上展示了创建分布式调用链的一般方式。类比此法,可以很容易的写出基于 HttpClient 组件的客户端组件。
接下来,我们将使用Spring的拿手锏Aop,来封装通过Feign接口调用的SpringCloud服务。你会发现,实现一个类似Sleuth的客户端收集器,还是蛮简单的。
5、微服务之调用链
终于到了我们的重点,微服务了。
与使用OkHttp3来实现的客户端类似,Feign接口本来也就是一个Http调用,依然可以使用Http头传值的方式,将 Trace 往下传。
本文更多的是关于 SpringCloud 的一些知识,你需要了解一些基本的 Spring 相关的知识。
SpringCloud的注册中心,我们选用Consul。
consul也是用golang开发的。从consul官网下载二进制包以后,解压。
./consul agent -bind 127.0.0.1 -data-dir . -node my-register-center -bootstrap-expect 1 -ui -dev
使用以上脚本快速启动,即可使用。
访问
http://localhost:8500/ui/
可以看到Consul的web页面。
5.1、构建微服务c/s端
以bom方式引入springboot和springcloud的组件。
spring-boot-dependencies 2.1.3.RELEASE spring-cloud-dependencies Greenwich.SR1
都是热乎乎的新鲜版本。
接下来下,引入其他必须的包
opentracing-util 0.32.0 jaeger-client 0.35.0 logback-classic 1.2.3 opentracing-spring-jaeger-cloud-starter 2.0.0 spring-boot-starter-web spring-boot-starter-aop spring-boot-starter-actuator spring-cloud-starter-consul-discovery spring-cloud-starter-openfeign
服务端App的端口是 8888
@SpringBootApplication
@EnableAutoConfiguration
@EnableDiscoveryClient
@ComponentScan(basePackages = {
"com.sayhiai.example.jaeger.totorial04.controller",
})
public class App extends SpringBootServletInitializer {
public static void main(String[] args) {
SpringApplication.run(App.class, args);
}
}
在application.yml中,配置Consul作为配置中心。
cloud:
consul:
host: 127.0.0.1
port: 8500
discovery:
register: true
tags: version=1.0,author=xjjdog
healthCheckPath: /actuator/health
healthCheckInterval: 5s
创建Rest服务 /hello
@PostMapping("/hello")
@ResponseBody
public String hello(@RequestBody String name) {
return "hello " + name;
}
5.2、构建Feign客户端
Feign客户端的App端口是 9999 ,同样是一个SpringCloud服务。
创建FeignClient
@FeignClient("love-you-application")
public interface LoveYouClient {
@PostMapping("/hello")
@ResponseBody
public String hello(@RequestBody String name);
}
创建调用入口 /test
@GetMapping("/test")
@ResponseBody
public String hello() {
String rs = loveYouClient.hello("小姐姐味道");
return rs;
}
5.3、集成jaeger
目前,已经有相关SpringCloud的轮子了,我们就不重复制造了。
首先,我们看一下使用方法,然后,说明一下背后的原理。了解原理之后,你将很容易的给自己开发的中间件加入Trace功能。
轮子在这里,引入相应maven包即可使用:
https://github.com/opentracing-contrib/java-spring-jaeger
<dependency> <groupId>io.opentracing.contrib</groupId> <artifactId>opentracing-spring-jaeger-cloud-starter</artifactId></dependency>
加入配置生效
在 application.yml 中,加入以下配置,就可以得到调用链功能了。
配置指明了trace的存放地址,并将本地log打开。
opentracing.jaeger.http-sender.url: http://10.30.94.8:14268/api/traces opentracing.jaeger.log-spans: true
访问 localhost:9999/test,会得到以下调用链。
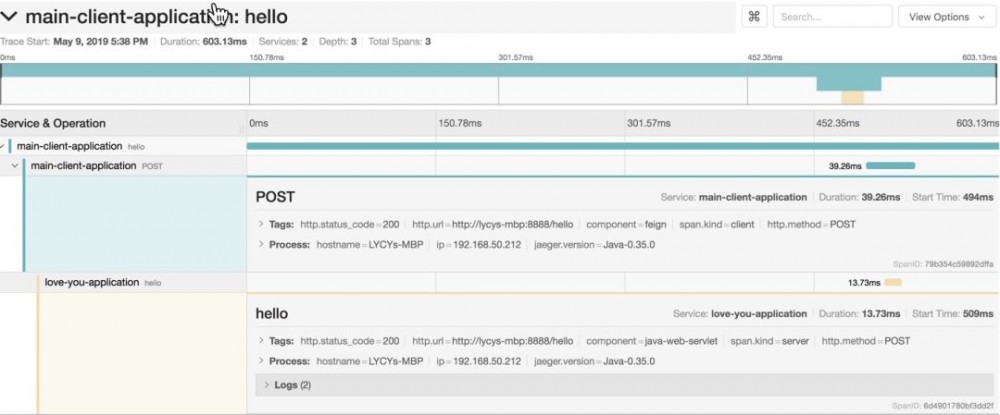 可以看到。Feign的整个调用过程都被记录下来了。
可以看到。Feign的整个调用过程都被记录下来了。
5.5 如何实现多线程
https://github.com/opentracing-contrib/java-concurrent
5.6、Feign的调用原理
Feign通过Header传递参数。首先看下Feign的Request构造函数。
public static Request create(
String method,
String url,
Map<String, Collection<String>> headers,
byte[] body,
Charset charset) {
return new Request(method, url, headers, body, charset);
}
如代码,完全可以通过在headers参数中追加我们需要的信息进行传递。
接着源代码往下找:
Client ->
LoadBalancerFeignClient execute() ->
executeWithLoadBalancer() ->
IClient ->
再往下,IClient实现有
OkHttpLoadBalancingClient
RibbonLoadBalancingHttpClient(基于apache的包)
等,它们都可以很容易的设置其Header
最终,我们的请求还是由这些底层的库函数发起,默认的是HttpURLConnection。
读过Feign和Ribbon源码的人都知道,这部分代码不是一般的乱,但好在上层的Feign是一致的。
使用委托包装Client
通过实现 feign.Client 接口,结合委托,可以重新封装 execute 方法,然后将信息 inject 进Feign的scope中。
使用Aop自动拦截Feign调用
@Aspect
class TracingAspect {
@Around("execution (* feign.Client.*(..)) && !within(is(FinalType))")
public Object feignClientWasCalled(final ProceedingJoinPoint pjp) throws Throwable {
Object bean = pjp.getTarget();
if (!(bean instanceof TracingClient)) {
Object[] args = pjp.getArgs();
return new TracingClientBuilder((Client) bean, tracer)
.withFeignSpanDecorators(spanDecorators)
.build()
.execute((Request) args[0], (Request.Options) args[1]);
}
return pjp.proceed();
}
}
利用spring boot starter技术,我们不需要任何其他改动,就可以拥有trace功能了。
5.7、Web端的发送和接收原理
了解spring的人都知道,最适合做http头信息添加和提取的地方,就是拦截器和过滤器。
发送
对于普通的http请求客户端来说,是通过添加一个
ClientHttpRequestInterceptor
拦截器来实现的。过程不再表诉,依然是使用inject等函数进行头信息设置。
接收
而对于接收,则使用的是Filter进行实现的。通过实现一个普通的servlet filter。可以通过 extract 函数将trace信息提取出来,然后将context作为Request的attribute进行传递。
相关代码片段如下。
if (servletRequest.getAttribute(SERVER_SPAN_CONTEXT) != null) {
chain.doFilter(servletRequest, servletResponse);
} else {
SpanContext extractedContext = tracer.extract(Format.Builtin.HTTP_HEADERS,
new HttpServletRequestExtractAdapter(httpRequest));
final Span span = tracer.buildSpan(httpRequest.getMethod())
.asChildOf(extractedContext)
.withTag(Tags.SPAN_KIND.getKey(), Tags.SPAN_KIND_SERVER)
.start();
httpRequest.setAttribute(SERVER_SPAN_CONTEXT, span.context());
就这样,整个链条就穿插起来啦。
5.8、使用instrumentation自动装配
类似pinpoint和SkyWalking的所实现的一样。opentracing-contrib还基于 bytebuddy 写了一套比较全的agent套件。
https://github.com/opentracing-contrib/java-specialagent
已经有以下客户端被支持。
OkHttp3 JDBC API (java.sql) Concurrent API (java.util.concurrent) Java Web Servlet API (javax.servlet) Mongo Driver Apache Camel AWS SDK Cassandra Driver JMS API (javax.jms v1 & v2) Elasticsearch6 Client RxJava 2 Kafka Client AsyncHttpClient RabbitMQ Client RabbitMQ Spring Thrift GRPC Jedis Client Apache HttpClient Lettuce Client Spring Web Spring Web MVC Spring WebFlux Redisson Grizzly HTTP Server Grizzly AsyncHttpClient Reactor Hazelcast
但是, bytebuddy 的性能是较差的,你可能需要参考这些代码,使用 asm 一类的api进行构建。
关于更详细的javaagent技术,可以参考小姐姐味道的另外一篇文章:
冷门instrument包,功能d炸天End
随着OpenTracing规范越来越完善,它的使用也越来越流行。在设计自己的软件时,可以提前考虑预留接口(通常给予重要功能实现拦截器),以便在扩展时,能够方便的将自己加入到调用链链路上来。
剩下的,就是工作量了。
温馨提示。本文的代码仓库,参见:
https://github.com/xjjdog/example-jaeger-tracing
作者简介: 小姐姐味道 (xjjdog),一个不允许程序员走弯路的公众号。聚焦基础架构和Linux。十年架构,日百亿流量,与你探讨高并发世界,给你不一样的味道。我的个人微信xjjdog0,欢迎添加好友,进一步交流。
近期热门文章
《 996的乐趣,你是无法想象的 》
魔幻现实主义,关爱神经衰弱
《 一切荒诞的傲慢,皆来源于认知 》
不要被标题给骗了,画面感十足的消遣文章
《必看!java后端,亮剑诛仙》
后端技术索引,中肯火爆。全网转载上百次。
《学完这100多技术,能当架构师么?(非广告)》
精准点评100多框架,帮你选型
《Linux上,最常用的一批命令解析(10年精选)》
CSDN发布首日,1k赞。点赞率1/8。

正文到此结束
- 本文标签: JMS cat EnableAutoConfiguration URLs linux Nginx HTTP协议 数据 QPS REST JDBC API example maven springboot GitHub 文章 数据库 Feign 程序员 bean 安装 equals key zip final cmd id 大数据 限流 core git mongo UDP 微信公众号 压力 consul Document root AOP 调试 Reactor 软件 tag Connection db zipkin SDN python grep ribbon App constant map 索引 分布式事务 java 开发 源码 服务端 Bootstrap 测试环境 src ip bug TCP 线程池 进程 注册中心 parse web Collection UI Proxy 组织 并发 线下 node 高并发 多线程 ACE tar springcloud CTO Service sql HashMap json spring dependencies 测试 十年 IDE Agent 部署 client servlet Elasticsearch 时间 Logging 线程 Sleuth 解析 IO 基金 JDBC list apache Logback 企业 remote 分布式 API http js javaagent CEO queue 标题 架构师 实例 目录 协议 MQ redis pinpoint 参数 tk build rabbitmq 代码 下载 广告 配置中心 Cassandra ORM 配置 连接池 value wget 性能问题 端口 Spring Boot 管理 微服务 统计 https 性能优化 空间
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

