使用netty徒手撸一个简单的kafkaClient
使用netty徒手撸一个ZkClient
使用netty徒手撸一个RedisClient
前两天博文我们介绍了如何使用netty徒手撸一个kafka的客户端. 所谓的kafka客户端就是kafka的producer和consumer了.
吐槽一下kafka的api设计
大家都知道, kafka的客户端是重构过一版的. 之前0.8的producer和consumer是使用scala开发的,后来因为各种原因, 实在是改不动了. 到了0.9版本的时候,使用java重构了kafka的客户端.
虽然现在java版的客户端还在广泛使用,而且没有什么太大的性能问题. 但是根据我这些天对kafka客户端的api的研究, 我总觉得, 总有一天, kafka的客户端还得来一次彻底的重构.因为什么呢? 因为实在是太--乱--啦:
1. 多版本问题. 每个api都有好几个版本, 但是每个api使用的版本都不一致. 举个例子, 在kafka-client 1.0.0中,broker的版本是2.3.0时: METADATA(拉取topic元数据)的api有1个version, 当前使用版本是1. PRODUCE(生产消息)的api有6个version, 当前使用版本是6 FETCH(拉取消息)的api有5个version, 当前使用版本是5 2. 报文的数据结构巨复杂 等下实现生产消息的报文的时候,你们会看到,这个报文嵌套了6层,即有6个子结构体. 复制代码
以上我对kafka api的小小吐槽. 当然也可能是我水平不够,未能理解到它这么设计的用意和深意~~
kafka的消息格式
kafka一直在不断地优化自身, 因此它的消息格式也是一直在变.
在<<Apache kafka实战 (胡夕著)>> 一书中(基于kafka 1.0.0), 作者介绍了到目前为止, 一共有3种消息格式V0,V1,V2. 其中V0和V1由于各种弊端, 早就逐渐的被淘汰了. 现在新版kafka使用的都是V2版本的消息格式. 本文就是在kafka2.3.0上实现的, 使用V2格式的消息能测试通过.
因此这里介绍的消息格式都是V2版本的.
在开始介绍kafka的消息格式之前, 大家还要理解一个概念: 可变长度. 常规的长度字段要么就是使用4个字节,要么就是使用8个字节来表示, 总之这个字段使用的字节数一般都是固定的. 但是在kafka的v2版本的消息里就不一样了. 它参考了Zig-zag的编码方式, 可以使用不同长度的字段来表示不同的数值. 简单来说就是这样: 用 0 来表示 0 用 1 来表示 1 用 2 来表示 -1 用 3 来表示 2 用 4 来表示 -2 ..... 这样的好处就是可以用比较少的字节数来表示绝对值比较小的数字, 不用每个数字都占用4个或8个字节, 从而可以节省很大的空间 复制代码
了解了"可变长度"这个概念后就可以来看kafka的v2版本的消息格式了. 如下图(截图自<<Apache kafka实战 (胡夕著)>> 一书):

我们来一个一个了解这些字段
1. 消息总长度. 顾名思义, 就是这条消息的总长度啦. 用的是Zig-zag编码表示 2. 属性. 一个字节表示(8位), 其中第三位用来表示压缩方式.高5位保留,没有用到 由于我这里的实现没有用到压缩,所以这个字段总是0 3. 时间戳增量.也是用Zig-zag编码. 所谓增量, 是指针对该消息batch的第一条消息的时间戳的增量. 消息batch接下来会介绍. 4. 位移增量. 跟时间戳增量含义差不多 5. key length. 每条kafka消息都可以有key, 这个就表示key的字节数 6. key. 这个字段就是kafka消息里面的key. 7. value size. 更key length含义差不多 8 value. 就是kafka消息的内容 9. header个数. kafka消息也可以带有header 10. header. kafka的header 复制代码
看到第3和第4个字段是不是有点一脸懵?没关系, 继续往下看你就明白了.
kafka发送消息的时候并不是有一条发送一条的, 而是把多条消息集中在一起, 然后再一并发送的. 这就是所谓的kafka 消息batch.
而且这消息batch发送到kafka的broker之后, 它也同样不会拆开, 而是原封不动地把这个消息batch发给消费者,或存储到日志文件中.
因此理解这个消息batch对我们实现发送消息和消费消息都是必要的.
消息batch的格式如下图所示:
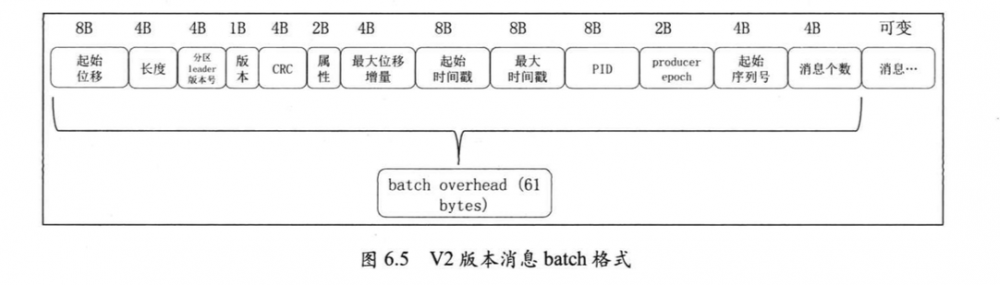
是不是一下子有点奔溃, 一下子冒出了这么多的字段. 没得办法, 我们再来一个个地看.
首先最后的"消息"就是上面介绍的v2版本格式的消息,可能会有x个, x就是倒数第二个字段"消息个数".
剩下的字段:
1. 起始位移 最后面的"消息"中第一条消息的位移offset 2. 长度 表示接下来的报文的长度, 即"消息batch的总长度" - 8Byte(起始位移字段) - 4Byte(长度字段) 3. 分区leader版本号 我这里的实现写死为-1 4. 版本号 就是magic. 我们这里是V2,所以是2 5. CRC 是指接下来的所有字段的CRC码 6. 属性 跟上面消息中的属性的含义一致 7. 最大位移增量 就是最后一条消息的"位置增量"的值 8. 起始时间戳 就是第一条消息的时间戳 9. 最大时间戳 最后一条消息的时间戳 10. 后面三个pid epoch, seq三个字段都是跟事务等相关的,我们这里没有用到, 所以都写死为-1 复制代码
这里的"消息"和"消息batch"我在代码中定义的bean分别是KafkaMsgRecordV2和KafkaMsgRecordBatch. 如果看上面的文字和图片确实不好理解的话, 可以跟着代码看, 或者可以理解得更加深刻. 代码请见文末的github地址.
当然如果你理解了这一段, 那很好.不过也别开心太早.因为上面说了, kafak发送消息的数据结构嵌套了6层, 而这里才两层. 也就是还有4层等着我们去理解. 当然, 那4层相对是比较简单的. 最难理解的部分已经过去了
requestHeader和responseHeader
kafka每个api的请求都必须带有一个请求的header, 而每个api的响应体中也都带有一个响应的header.requestHeader和responseHeader分别如图所示:
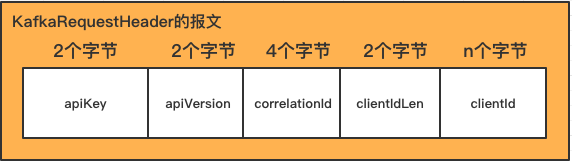

响应的header比较简单, 就是一个correlationId,这个id其实是客户端发送给服务端, 服务端原封不动的返回了. 作用跟zookeeper的xid一样.
我们来看看requestHeader
apikey 和 apiVersion
public enum ApiKeys {
/**
* 发送消息
*/
PRODUCE(0, "Produce", (short) 5),
/**
* fetch 消息
*/
FETCH(1, "Fetch", (short)6),
/**
* 拉取元数据
*/
METADATA(3, "Metadata", (short) 1);
public final short id;
public final String name;
public short apiVersion;
ApiKeys(int id, String name, short apiVersion) {
this.id = (short) id;
this.name = name;
this.apiVersion = apiVersion;
}
}
复制代码
代码中的id字段就是apiKey, apiVersion对应的就是header中的apiVersion. 正如我们开头吐槽的一样, 每个api的版本都是不一样的. 在这次实现里, 我只实现了3个api. 但实际上kafka提供十几个api.
correlationId
关联性Id和zkClient中的xid作用是一样的, 主要是把请求和响应对应起来. kafka的响应报文中会包含这个字段.
clientIdLen和clientId
不管是kafka生产者还是消费者, 都需要指定一个clientId. 在官方的客户端中,如果我们不指定的话, 也会自动生成一个clientId.
最后值得一提的是, 这里的clientIdLen是用两个字节表示的. kafka里面都是用2个字节表示字符串长度的. 这个跟zookeeper里面是不一样的.
生产者
生产者的逻辑实现在KafkaClient的send方法:
public ProduceResponse send(KafkaProduceConfig config, String topic , String key, String val) 复制代码
正如上面一直提到的, 生产者的请求报文一共嵌套了6层, 具体表现为:
1. ProduceRequest继承KafkaRequestHeader, 持有TopicProduceData对象 2. TopicProduceData 持有PartitionData对象 3. PartitionData持有Record对象 4. Record持有KafkaMsgRecordBatch对象 5. KafkaMsgRecordBatch持有KafkaMsgRecordV2对象 复制代码
可以看到, 其实是以"broker信息" => "topic信息" =>"分区信息" => "记录信息" => "消息batch" => "消息"等层次逐渐包装的.
报文的的字段和图示这里就不再给出了,有兴趣的同学可以跟一下代码, 直接从序列化入手, 就可以理解kafka生产者的通讯协议了, 大体逻辑如下所示:
- ProduceRequest.serializable()
- KafkaRequestHeader.serializable()
- TopicProduceData.serializable()
- PartitionData.serializable()
- Record.serializable()
- KafkaMsgRecordBatch.serializable()
- KafkaMsgRecordV2.serializable()
复制代码
经过上面的一系列serializable, 最终把一个ProduceRequest对象转换成一个ByteBuf,发往kafka的broker, 一条消息就成功的产生了.
消费者
生产者的逻辑实现在KafkaClient的poll方法:
public Map<Integer, List<ConsumerRecord>> poll(KafkaConsumerConfig consumerConfig, String topic, int partition, long fetchOffset) 复制代码
相对于生产者来说, 消费者的请求报文相对简单,也是一个从"broker配置"=>"topic信息" => "分区信息"的包装过程
如下所示:
1. FetchRequest 继承KafkaRequestHeader, 持有FetchTopicRequest对象 2. FetchTopicRequest持有FetchTopicPartitionRequest对象 复制代码
然而, 消费者的响应体就相对比生产者的响应体要复杂的多了.
因为上面说过, 生产者发送broker的"消息batch", broker是不会把它解析成具体的消息的. 而且原封不动地把它保存到日志中去, 从而也是原封不动的被消费者消费到. 因此这个解析消息的工作自然而然地就落到了消费者的肩上.
具体请参见KafkaClient#parseResp()方法
代码运行
和之前的ZkClient和RedisClient一样, 这里也同样实现了一个kafkaClientTest,方便体验和调试.
这次针对了几种场景进行测试:
- 在kafkaClientTest中生产消息, 利用kafka自带的kafka-console-consumer.sh 进行消费
生产消息:
private final static String host = "localhost";
private final static int port = 9092;
private final static String topic = "testTopic1";
@Test
public void testProducer(){
KafkaClient kafkaClient = new KafkaClient("producer-111", host, port);
KafkaProduceConfig kafkaConfig = new KafkaProduceConfig();
// 注意这里设置为0时, broker不会响应任何数据, 但是消息实际上是发送到broker了的
short ack = -1;
kafkaConfig.setAck(ack);
kafkaConfig.setTimeout(30000);
ProduceResponse response = kafkaClient.send(kafkaConfig, topic,"testKey","helloWorld1113");
assert ack == 0 || response != null;
System.out.println(new Gson().toJson(response));
}
复制代码
可以在控制台看到消息被消费了:
lhhMacBook-Air:bin$ sh kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic testTopic1 helloWorld1113 复制代码
- 在kafkaClientTest中生产消息(场景1的消息), 在kafkaClientTest消费消息:
private final static String host = "localhost";
private final static int port = 9092;
private final static String topic = "testTopic1";
@Test
public void testConsumer(){
// 如果broker上不存在这个topic的话, 直接消费可能会报错, 可以fetch一下metadata, 或先生产消息
// testMetaData();
// testProducer();
KafkaClient kafkaClient = new KafkaClient("consumer-111", host, port);
KafkaConsumerConfig consumerConfig = new KafkaConsumerConfig();
consumerConfig.setMaxBytes(Integer.MAX_VALUE);
consumerConfig.setMaxWaitTime(30000);
consumerConfig.setMinBytes(1);
Map<Integer, List<ConsumerRecord>> response = kafkaClient.poll(consumerConfig, topic, 0, 0L);
assert response != null && response.size() > 0;
Set<Map.Entry<Integer, List<ConsumerRecord>>> entrySet =response.entrySet();
for(Map.Entry<Integer, List<ConsumerRecord>> entry : entrySet){
Integer partition = entry.getKey();
System.out.println("partition" + partition + "的数据:");
for(ConsumerRecord consumerRecord : entry.getValue()){
System.out.println(new Gson().toJson(consumerRecord));
}
}
}
复制代码
控制台打印出刚刚生产的消息(包含了之前测试的消息), 说明消费成功:
partition0的数据:
{"offset":0,"timeStamp":1573896186007,"key":"testKey","val":"helloWorld"}
{"offset":1,"timeStamp":1573896202787,"key":"testKey","val":"helloWorld"}
{"offset":2,"timeStamp":1573896309808,"key":"testKey","val":"helloWorld111"}
{"offset":3,"timeStamp":1573899639313,"key":"testKey","val":"helloWorld1113"}
{"offset":4,"timeStamp":1574011584095,"key":"testKey","val":"helloWorld1113"}
复制代码
- 利用kafka-console-producer.sh生产消息, 在kafkaClientTest消费消息:
生产消息:
lhhMacBook-Air:bin$ sh kafka-console-producer.sh --broker-list localhost:9092 --topic testTopic222 >hi >h 复制代码
消费消息输出, 说明消费成功
partition0的数据:
{"offset":0,"timeStamp":1574012251856,"val":"hi"}
{"offset":1,"timeStamp":1574012270368,"val":"h"}
复制代码
正文到此结束
- 本文标签: 解析 setTimeout 协议 图片 zookeeper Netty value http https zab 调试 空间 性能问题 apache 自动生成 apr API key src git id UI 时间 final java bean tar Bootstrap json client db 服务端 配置 代码 开发 scala tk redis parse consumer 测试 IO map GitHub list producer js 并发 数据
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
收到
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
-
-
-
https://pplx.ai/floraliu4199466 这个链接打不开是什么原因?
-
-
-
-
来看看,最近更新了一波,顺着友联过来的,几年过去了,网站越搞越好,厉害
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

