深度解析Containers--系统架构
什么是 Containers?
随着Kubernetes,Docker Compose,Mesos OS,Consul等出现,容器是这些云计算时代的头条新闻。
要真正了解容器的架构组合,您需要首先了解以下几点:
- Linux Kernel User & System Space
- Syscalls and Capabilities
- Cgroups
- Namespaces
- EIAF (Everything Is A File), a description of the Unix based Filesystem
尽管Mac内核符合POSIX且基于OpenBSD,但是这5件事对于真正了解容器的工作原理以及为什么需要Linux VM在Windows和Mac上运行容器很重要。
为什么我要这样开始?
我将深入探讨有关容器的文章,重点是Docker,Dockerfiles和诸如docker build -t之类的命令。相当小的部分仍会在后面的部分中讲述,但是它们如何工作的基础是我今天介绍的内容。
因此,我采用了不同的方法,直接研究了使容器正常工作的因素,以及容器的外观和功能。
让我们从了解Linux内核系统和用户空间入手,以深入了解容器的实际作用。
Linux 内核空间
在Linux中,我们通常有两个运行应用程序的空间,即内核系统空间和用户空间。通常,在默认的内核配置下,用户空间占用0–3GB空间,而内核空间占用3-4GB空间。
内核空间是我们为运行内核的低级应用程序提供系统内存的位置。用户空间是我们用户进程运行和执行的环境。
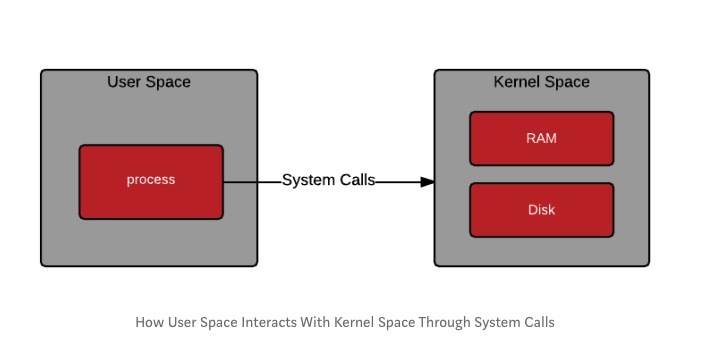
这两个内存空间被称为“ Rings”的微调权限层隔开。这些环定义了在可以授予某些操作之前需要满足应用程序要求的特权或特权的程度。
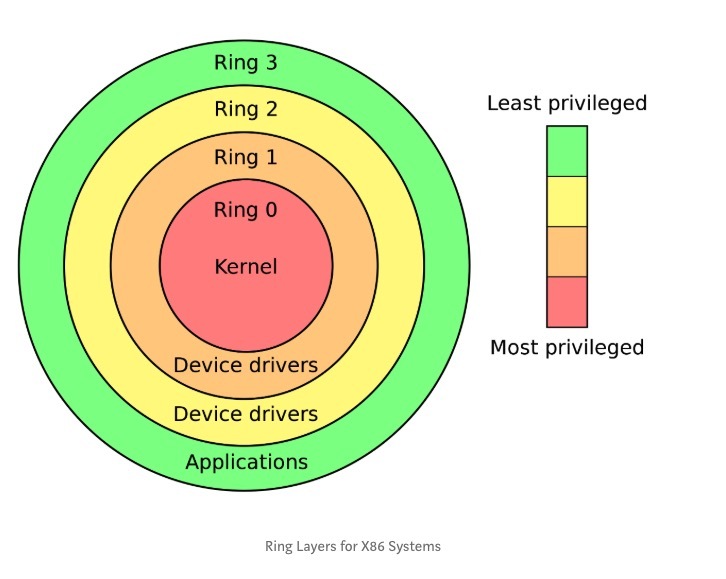
这些环并不是Linux特有的,而是在操作系统中定义明确的布局,尽管每个级别的功能区域都是根据操作系统所运行的CPU架构分配的。为了在用户空间和内核空间之间切换,我们通过系统调用(简称为syscall)应用操作。
这使用可从用户空间应用程序访问的已定义内核功能来请求访问内核级功能。下图完美地说明了如何定义此顺序。
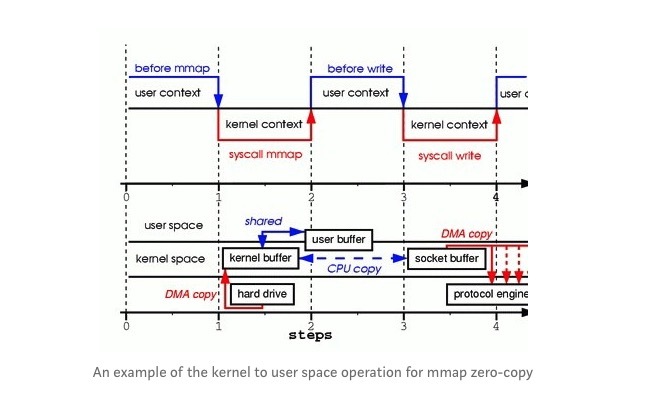
每当应用程序向内核级功能发出请求时,都会发送一个中断,通知处理器停止正在执行的操作并处理该特定请求,如果可以简化理解,则可以将其视为上下文切换。如果用户空间应用程序具有相关权限,则可以在内核空间中进行上下文切换,在上下文切换启动后,用户空间应用程序将等待响应,并通过适当的中断处理程序在内核空间中执行所需的程序/功能。
tmp/_buf = mmap(file, len); # mmap here is from a C library/# This is called a memory map and it's a C function /# It allocates a certain amount of memory for a task, file etc. /# Since memory is a kernel space resource, a syscall is made to the mmap syscall in the linux kernel to make this request possible
SysCalls 和 Capabilities
系统调用又名syscall是一个API,它允许一小部分内核功能公开给用户级应用程序。真正强调的一小部分是告知任何阅读者,系统调用是有限的,并且通用于特定目的。它们在每个操作系统上都不相同,并且在访问的定义和访问方式上也有所不同。
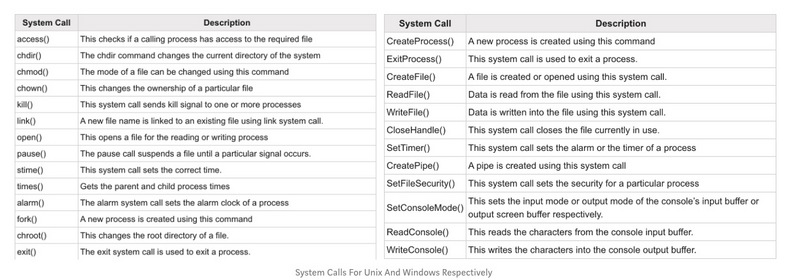
追溯到先前的mmap示例,该接口未在列表中列出,因为它只是一小部分,可在此处获得linux中syscall的完整列表。
有时,我们有一组要组合在一起的系统调用,我们使用名为Capabilities的Linux内核功能来实现。这些是预定义的特权集,正在运行的程序可以访问这些特权或受其限制。
通过将相关调用分组为可立即授予或拒绝的已定义特权,功能进一步增强了系统调用。这甚至防止了根级应用程序利用保留的权限来利用受限的内核空间。
有几种linux功能,以后将在大多数文章中访问它们,以了解它们如何使用SecComp等配置文件与容器进行集成,更具体地说是使用AppArmor,SELinux等LSM(Linux安全模块)进行集成,但是您可以在此处的 手册 页中引用列表。
Cgroups
控制组(通常称为cgroup)是Linux内核允许将流程组织为分层的功能,然后可以限制其使用各种类型资源的组并进行监控。内核的cgroup接口通过 伪文件系统,称为cgroupfs。分组在 核心cgroup内核代码,而资源跟踪和限制是 在一组每个资源类型的子系统(内存,CPU, 等等)。
简单来说,cgroup控制着我们可以使用的功能。它们的功能列表如下所示:
- 资源限制:可以将组配置为不超过指定的内存限制或使用的处理器数量不超过期望的数量,或者限制为特定的外围设备。
- 优先级:可以将一个或多个组配置为利用更少或更多的CPU或磁盘I / O吞吐量。
- 记帐:监视和衡量组的资源使用情况。
- 控制:可以冻结或停止并重新启动进程组。
Cgroup通过使用子系统/控制器来运行,这些子系统/控制器可以修改进程的运行时环境。在v1和v2两个版本中有多个控制器可用。
在v1控制器领域,我们具有以下优势:
blkio cpu cpuacct cpuset devices freezer memory net_cls net_prio ns perf_event hugetlb pids rdma
对于v2控制器空间,由于未实现某些控制组,因此我们具有v1的某些功能,linux系统可以同时使用这两个功能,但是v2系统更紧凑,cgroup更少。
io memory pids perf_event rdma cpu
您会注意到,它在功能方面与版本1控制器相同。每个cgroup提供限制一个或多个资源的功能。有关此问题的库和工具将在以后的部分中进行重新介绍。
Namespaces
命名空间使容器相信它们存在于完全隔离的环境中,而不是在主宿主系统中。更具体地说,容器内的进程将自身视为系统内唯一的进程。
您可以认为它在盒子里,而在盒子里,您认为自己是盒子的主人,但是您只是在实际上拥有两个盒子的另一个人的盒子里玩梦境。由于具有此功能,因此可以在容器中运行容器,尽管稍后会涉及到一些问题。
对于名称空间功能,它嵌入在Linux组成部分中。

这些名称空间提供了不同的功能。
IPC Network Mount PID User UTS
所有这些名称空间都是使用 unshare 系统调用实现的,以隔离资源。
Linux FileSystem
在Linux中首先要注意的是,所有内容都是一个文件。我不骗你,从存储设备,串行设备等所有 /dev//* 一直到 /proc/fileystems 中的文件系统列表,一直到主机上运行的cgroup。不同文件系统之间的大多数交互都是由 虚拟文件系统 驱动程序(VFS)处理的,但这是另一个的主题。
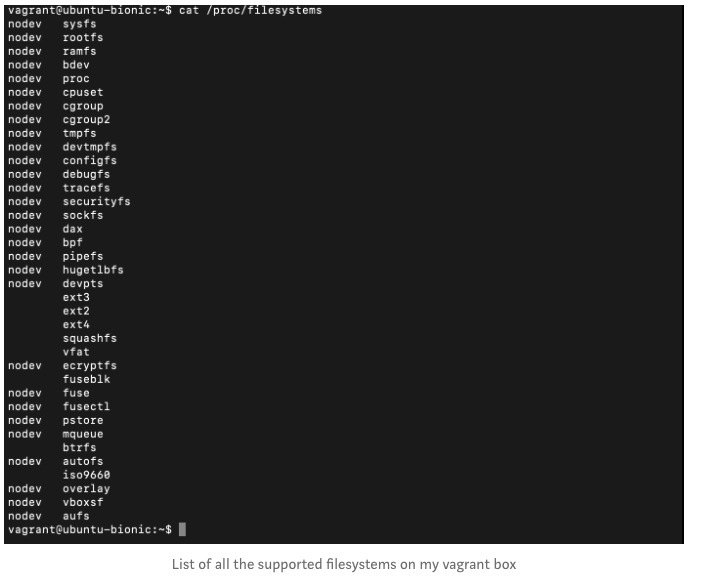
因为所有内容都是文件,所以我可以从字面上 cat 以查看受支持的配置。
如前所述,容器是进程。我们都了解了容器和VM之间的区别的方式是,容器共享主机的内核及其某些资源。这里的主要提示是资源,容器使用不同的根文件系统开始自己的操作,容器(提示:它们是进程)开始使用的实际文件系统是镜像。
镜像是一个Linux文件系统,大部分经过压缩,然后使用一些COW(写时复制)文件系统(例如AUFS,device-mapper,Btrfs,XFS等)从中执行。
对于安装了docker的用户,您可以运行以下命令以查看docker镜像的内部结构(不是容器,容器是进程,正在运行的镜像等。)
mkdir rootfs && / docker export $(docker create ubuntu:18.04) | tar -C rootfs -xvf -
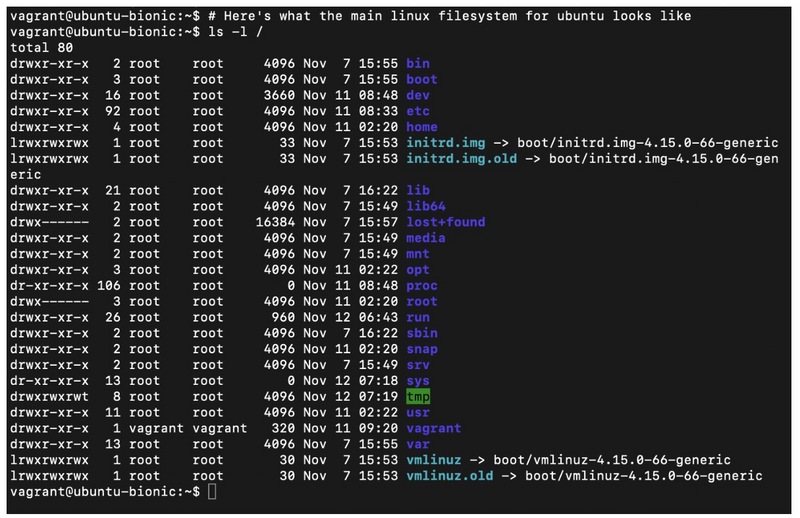
主要的linux文件系统非常特殊,因为您会注意到 vmlinuz 和 initrd.img ,我稍后会再提到。
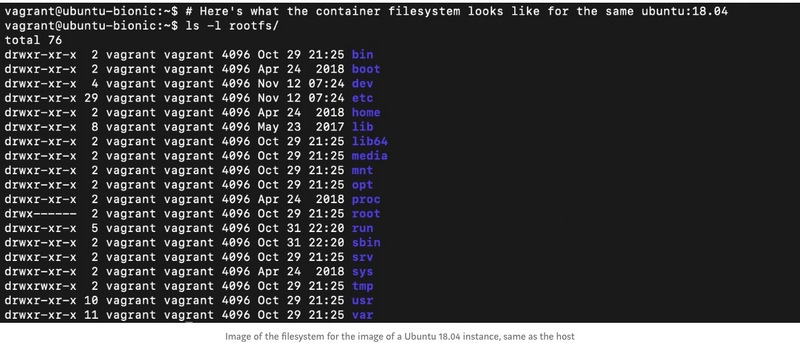
在这里,我们注意到我们没有在主文件系统上看到的 initrd 和 vmlinuz 文件,这是因为这两个文件是内核文件。
InitRD — Init Ram Disk
初始RAM磁盘(initrd)是在实际根文件系统可用之前安装的初始根文件系统。 initrd绑定到内核,并作为内核引导过程的一部分进行加载。然后,内核将此initrd挂载为两阶段引导过程的一部分,以加载模块以使实际文件系统可用并获得真实的根文件系统。
VMLinuz —Virtual Memory LINUx gZip
vmlinuz是Linux内核可执行文件的名称。 vmlinuz是压缩的Linux内核,它能够将操作系统加载到内存中,从而使计算机可用并可以运行应用程序。
在linux上,您可能会遇到vmlinux或vmlinuz。它们相同,但其中之一被压缩。
vmlinuz = V irtual M emory LINU x g Z ip = Compressed Linux kernel Executable
vmlinux = V irtual M emory LINU X = Non-compressed Linux Kernel Executable
vmlinuz和initrd文件都在引导时使用。
现在,这是主要原因,在容器文件系统或镜像中没有这两个文件。
容器使用主机内核!
不需要启动序列即可获取内核,容器中应用程序的所有可能请求都是通过主机调用通过主机调用发出的,该调用通过rings, capabilities, seccomp, LSMs等强制执行,一直返回到所有普通的linux程序。
这里的主要思想是容器只使用完全不同的文件系统,但是它们共享相同的Linux内核。对于那些稍微了解linux的人来说,我们知道我们可以将 chroot 转换为外部linux文件系统,并在其中进行操作,就好像文件系统已启动一样,前提是来自主机的所有必要文件都通过绑定安装在该文件夹中。
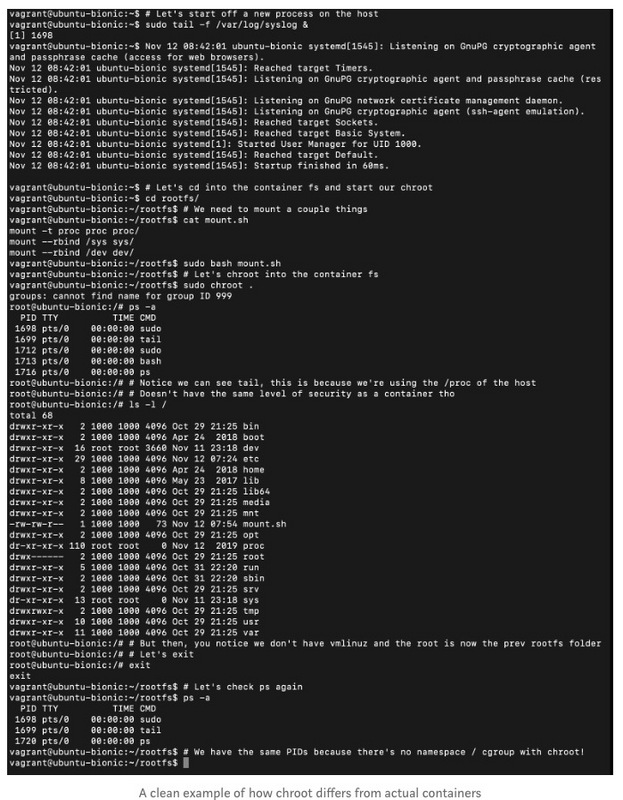
如果您已经读了该文章的某些部分,您会发现容器类似chroot,只不过与名称空间,cgroup和许多其他很酷的功能打包在一起,以使应用程序沙箱在同一主机上尽可能安全。
Summary
容器是在命名空间内执行的运行时进程,该命名空间由cgroup和各种其他LSM和安全功能管理,以确保在运行时完全隔离进程。容器中的这些过程以及诸如Docker之类的容器运行时尤其是自动化的,它简化了很多讨论的事情,但是我所解释的主要基础层仍然是相同的。
正文到此结束
- 本文标签: 自动化 ACE map Dockerfile App lib zip tar IO UI 组织 windows http 安全 id 空间 build Ubuntu mapper 系统架构 Docker tab 主机 cat mmap 代码 Uber 云 https 处理器 配置 解析 ask unix 进程 文件系统 API linux ip 文章 安装 consul Kubernetes src root description 工作原理 管理 操作系统
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章

近期评论
-
不会英语啊。
-
前100名用户会展示特殊的纪念徽章
-
-
https://pplx.ai/floraliu4199466 这个链接打不开是什么原因?
-
-
-
-
来看看,最近更新了一波,顺着友联过来的,几年过去了,网站越搞越好,厉害
-
哥太牛了
-
是呀,看您的IP显示在美国,还以为您移民了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

