Disruptor-高性能线程消息传递框架
一、前言
听到队列相信大家对其并不陌生,在我们现实生活中队列随处可见,去超市结账,你会看见大家都会一排排的站得好好的,等待结账,为什么要站得一排排的,你想象一下大家都没有素质,一窝蜂的上去结账,不仅让这个超市崩溃,还会容易造成各种踩踏事件,当然这些事其实在我们现实中也是会经常发生。 当然在计算机世界中,队列是属于一种数据结构,队列采用的FIFO(first in firstout),新元素(等待进入队列的元素)总是被插入到尾部,而读取的时候总是从头部开始读取。在计算中队列一般用来做排队(如线程池的等待排队,锁的等待排队),用来做解耦(生产者消费者模式),异步等等。
二、JAVA中的常见队列
| 队列 | 是否加锁 | 数据结构 | 技术点 | 是否有界 |
|---|---|---|---|---|
| ArrayBlockingQueue | 是 | 数组array | ReentrantLock | 有界 |
| LinkedBlockingQueue | 是 | 链表 | ReentrantLock | 有界 |
| LinkedTransferQueue | 否 | 链表 | CAS | 无界 |
| ConcurrentLinkedQueue | 否 | 链表 | CAS | 无界 |
我们可以看见,我们无锁的队列是无界的,有锁的队列是有界的。
这里就会涉及到一个问题,我们在真正的线上环境中,无界的队列,对我们系统的影响比较大,有可能会导致我们内存直接溢出,所以我们首先得排除无界队列,当然并不是无界队列就没用了,只是在某些场景下得排除。
其次还剩下ArrayBlockingQueue,LinkedBlockingQueue两个队列,他们两个都是用ReentrantLock控制的线程安全,他们两个的区别一个是数组,一个是链表。
在队列中,一般获取这个队列元素之后紧接着会获取下一个元素,或者一次获取多个队列元素都有可能,而数组在内存中地址是连续的,在操作系统中会有缓存的优化(下面也会介绍缓存行),所以访问的速度会略胜一筹,我们也会尽量去选择ArrayBlockingQueue。 而事实证明在很多第三方的框架中,比如早期的log4j异步,都是选择的ArrayBlockingQueue。
ArrayBlockingQueue,也有自己的弊端,就是性能比较低,为什么jdk会增加一些无锁的队列,其实就是为了增加性能,难道没有既无锁,又有界的队列吗?
三、Disruptor
简介
Disruptor是英国外汇交易公司LMAX开发的一个高性能队列,并且是一个开源的并发框架,能够在无锁的情况下实现Queue的并发操作。
基于Disruptor开发的系统单线程能支撑每秒600万订单。 目前,包括Apache Storm、Camel、Log4j2等等知名的框架都在内部集成了Disruptor用来替代jdk的队列,以此来获得高性能。
Disruptor为什么那么快?
BlockingQueue做对比,disruptor除了能完成同样的工作场景外,能做更多的事,效率也更高, 业务逻辑处理器完全是运行在内存中。
一、无锁(使用CAS替代Lock)
使用 事件源驱动方式(event sourcing) 业务逻辑处理器的核心是Disruptors,能够在 无锁 的情况下实现网络的Queue并发操作。
取而代之的是,在需要确保操作是线程安全的(特别是,在多生产者的环境下,更新下一个可用的序列号)地方,使用CAS(Compare And Swap/Set)操作。
这是一个CPU级别的指令,CAS操作比锁消耗资源少的多,因为它们不牵涉操作系统,它们直接在CPU上操作。
Disruptor中的游标(序列号)就是用java提供的AtomicLong来实现的多线程cas。
二、解决伪共享问题
什么是伪共享?
伪共享的问题也是基于CPU级别的机制引起的。正常情况下现在的大多数机器的内存分级机制如下图所示
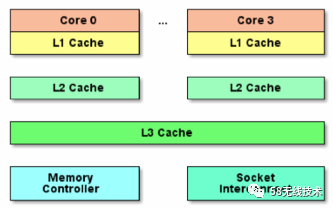
一般内存会再分为如上图所示的3层,多核CPU,每个CPU核心都有自己的私有内存空间L1,L1上层会有一个比较大的L2内存空间,L2上层有一个同一个插槽的CPU共享的L3内存空间,再上层就是所有插槽的CPU共享的主内存空间。每个CPU核心存取离自己越近的内存空间速度越快,越往上速度越慢。所以为了提高性能,就需要尽量将数据存放在L1区域,而尽量避免到主内存中取数据。
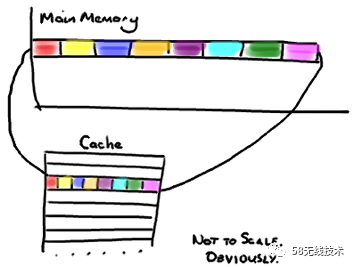
缓存系统是以缓存行为单位存储的,每个缓存行一般64字节,为了提高数据访问性能,CPU在拉起一个变量的值到L1空间时,会将相邻一共达到64字节的变量一起拉倒L1空间中。这种情况正常是没有问题的,因为CPU访问相邻变量会变得很快。 如果你访问一个 long 数组,当数组中的一个值被加载到缓存中,它会额外加载另外 7 个。因此你能非常快地遍历这个数组。事实上,你可以非常快速的遍历在连续的内存块中分配的任意数据结构,这就是缓存行带来的免费加载的好处。
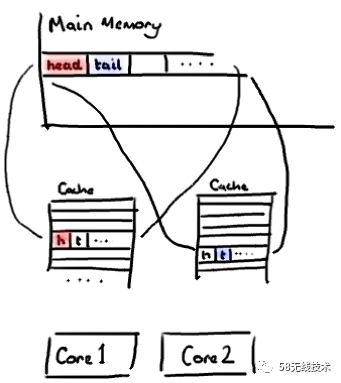
但是有一个问题,就是如果相邻的变量对该CPU而言是不相干的,也就是说CPU1只关心变量1 ,CPU2只关心变量2,但是CPU1和CPU2在分别拉取变量1和变量2的都将这两个变量拉倒了自己的L1空间。 此时如果CPU1修改了变量1的值, CPU为了保障修改的值被其他CPU看到,基于内存屏障的机制,会将修改的变量立即刷新到主内存中。 而此时CPU2在获取变量2的值时,却不得不到主内存中获取。 CPU2修改变量2的值时,也会影响CPU1对变量1的访问。 这就是伪共享。
解决方案
那么Disruptor是怎么解决伪共享的问题的呢 ? 就是通过缓存行填充。
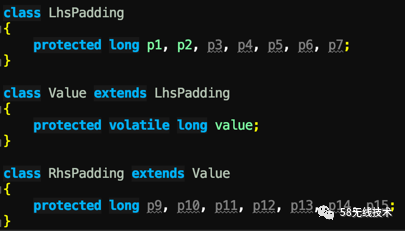
Sequence是Disruptor中的一个重要组件,用于跟踪并发的进度。 Sequence 继承了RhsPadding 实现了缓存行填充,生产者然后通过写value值来更新进度。 既然每个CPU会将访问的变量相邻的64字节的变量拉倒自己的内存空间,那么可以在该变量上再新建几个空变量满足64个字节不就可以了么。 即使出现伪共享,也不会影响其他CPU。 可以看到有几个Long类型的变量P1,P2,P3,P4,P5,P6,P7,就是为了填充。
三 、RingBuffer数据结构
正如名字所说的一样,它是一个环(首尾相接的环),你可以把它用做在不同上下文(线程)间传递数据的buffer。
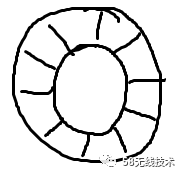
通过数组预分配内存 - 减少节点操作空间释放和申请的过程,从而减少GC次数。并且由于数据元素内存地址是连续的,基于缓存行的机制,数组中的数据会被预加载到CPU的L1空间中,就无需到主内存中加载下一个元素,从而提高了数据访问性能。
求余操作优化 - 我们在新建Disruptor的实例时,需要设置bufferSize,并且官方说明该值必须是2的N次方,否则会抛出异常。那么为什么会需要2的N次方呢?主要是为了求余的优化。求余操作本身是一个高耗费的操作,但是在Disruptor中,通过位操作来高效实现求余,这需要值是2的N次方才能保证结果的唯一性。
不删除数据 - 对数组中数据的删除也是比较消耗性能的,因为涉及到索引的重新排位,而RingBuffer中并不会删除已经被消费的数据,而是等到有新的数据覆盖它们。这就意味着不需要花大量的时间用于垃圾回收。此外,不像链表那样,需要为每一个添加到其上面的对象创造节点对象—对应的,当删除节点时,需要执行相应的内存清理操作。
四、Disruptor中RingBuffer的使用
-
环形拥有一个序号,这个序号指向数组中下一个可用的元素。
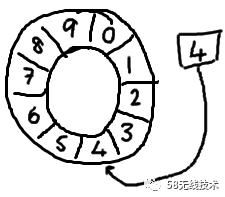
-
随着你不停地填充这个buffer,可能也会有相应的读这个序号会一直增长,直到绕过这个环。
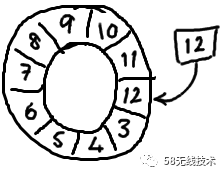
-
要找到数组中当前序号指向的元素,可以通过mod操作:
sequence mod array length = array index
以上面的ringbuffer为例(java的mod语法):12 % 10 = 2。很简单吧。
事实上,上图中的ringbuffer只有10个槽完全是个意外。如果槽的个数是2的N次方更有利于基于二进制的计算机进行计算。
-
听起来,环形buffer非常适合这个场景。它维护了一个指向尾部的序号,当收到nak(校对注:拒绝应答信号)请求,可以重发从那一点到当前序号之间的所有消息。如果你看了维基百科里面的关于环形buffer的词条,你就会发现,RingBuffer与其最大的区别在于:没有尾指针。只维护了一个指向下一个可用位置的序号。这种实现是经过深思熟虑的—选择用环形buffer的最初原因就是想要提供可靠的消息传递。将已经被服务发送过的消息保存起来,这样当另外一个服务通过nak (校对注:拒绝应答信号)告诉我们没有成功收到消息时,我们能够重新发送给他们,听起来,环形buffer非常适合这个场景。它维护了一个指向尾部的序号,当收到nak(校对注:拒绝应答信号)请求,可以重发从那一点到当前序号之间的所有消息:
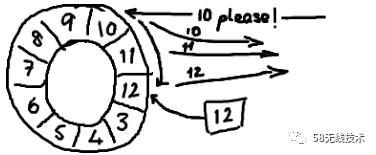
-
Disruptor中实现的ring buffer和大家常用的队列之间的区别是,不删除buffer中的数据,也就是说这些数据一直存放在buffer中,直到新的数据覆盖他们。这就是和维基百科版本相比,不需要尾指针的原因。ringbuffer本身并不控制是否需要重叠(决定是否重叠是生产者-消费者行为模式的一部分)
四、总结
CPU是你机器的心脏,最终由它来执行所有运算和程序。 主内存(RAM)是你的数据(包括代码行)存放的地方。 做为一个开发者你可以逃避不去了解CPU,数据结构, 如果你知道这些知识并应用它,你能写出一些非常巧妙和非常快速的代码。
也许 仅仅是针对 CPU和R AM的些许优化带来的就是天翻地覆的优化。

正文到此结束
热门推荐










相关文章

近期评论
-
收到
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
-
-
-
https://pplx.ai/floraliu4199466 这个链接打不开是什么原因?
-
-
-
-
来看看,最近更新了一波,顺着友联过来的,几年过去了,网站越搞越好,厉害
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

