jdk1.8-Java集合框架之--LinkedList源码分析
上一篇我们通过简单的ArrayList的源码分析,分析了ArrayList为什么有序,为什么读操作快?为什么写操作慢?详情请穿越 jdk1.8-Java集合框架之二-ArrayList源码分析
这篇我们讲解的是LinkedList,同样我们是带着问题来的:
- LinkedList为什么是有序的,它的数据结构是什么??
- LinkedList为什么是读效率低,写效率高呢??
- LinkedList中能否存在重复的值??是否允许添加null值??
按部就班
套路一(先看长相):先看LinkedList的类继承关系图。
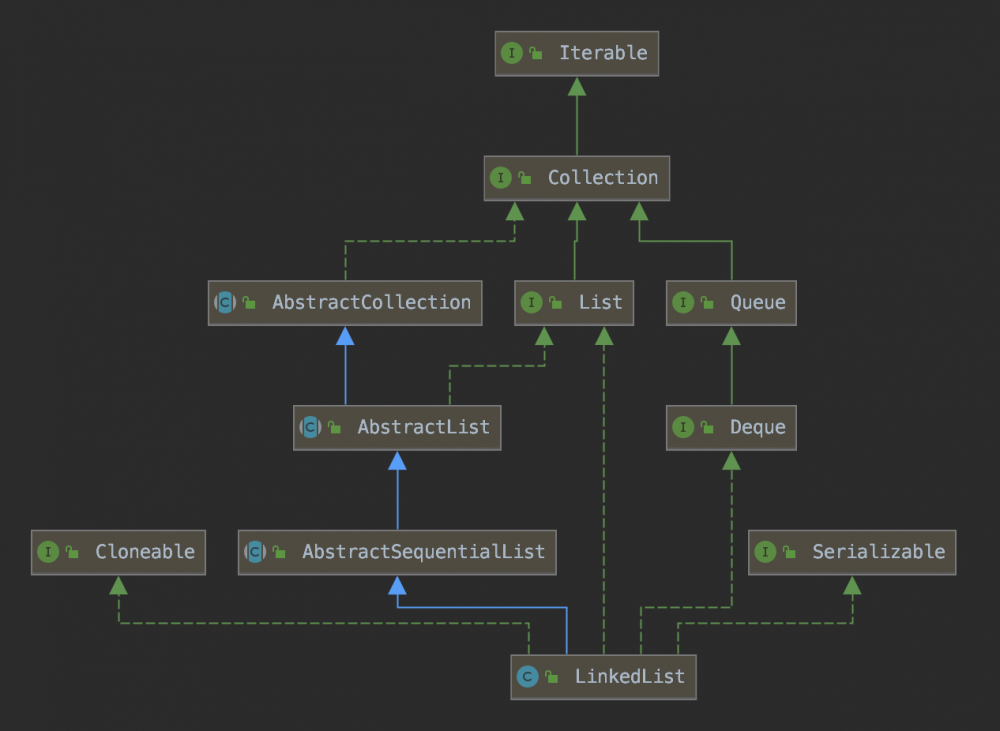
可以看出,LinkedList继承了一个父类AbstractSequentialList,另外实现了4个接口,分别是Cloneable、List、Deque、Serializable。
父类AbstractSequentialList是一个抽象类,提供部分已经实现的功能,单与本次讲解的LinkedList内容关系不大,暂且不谈,有兴趣的同学可以自行了解,
回想一下ArrayList的源码,发现ArrayList实现的接口与LinkedList实现的接口差别就在于ArrayList实现了RandomAccess接口而LinkedList没有,LinkedList实现了Deque接口而ArrayList没有。
what?Deque接口又是什么鬼??
public interface Deque<E> extends Queue<E> 复制代码
Deque接口是Queue接口的子接口,且从名字上我们可以猜出,应该是双向队列。
从继承关系图可以得出两个结论,1:LinkedList没有实现RandomAccess接口说明LinkedList不支持快速访问;2.LinkedList实现了Deque接口说明是一个双向队列的数据结构。
套路二(再看身材):再看LinkedList定义的属性
//长度 transient int size = 0; //指向第一个节点的指针 transient Node<E> first; //指向最后一个节点的指针 transient Node<E> last; 复制代码
就这样完了??
LinkedList只定义了三个实例变量,没有其他的了。既然这样,那我们就先撩一下看这个Node是哪个小妖精。。
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
复制代码
其实这个Node类是LinkedList的私有静态内部类。这个类定义了三个属性,一个是与LinkedList范型一致的item,另外两个属性类型都是Node,next指向Node对象的下一个Node对象,prev指向Node对象的前一个Node对象。
很明显,Node类这样的设计,我们可以回答一开始带来的第一个问题,LinkedList就是一个链表的数据结构设计,每一个对象都持有指向前一个对象的引用,也都持有指向后一个对象的引用,这种结构天生就是有序的。
套路三(看内在):看具体的实现
先从构造方法入手,LinkedList提供了两个构造方法,无参数的构造方法没有任何实现,我们直接看有参数的构造方法:
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
复制代码
该构造方法需要传入一个Collection集合实现类对象,直接将集合对象放进addAll方法里,我们再看allAll方法:
public boolean addAll(Collection<? extends E> c) {
return addAll(size, c);
}
复制代码
addAll方法又调用了addAll的重载方法,并传入了两个参数,第一个是LinkedList的实例变量size,第二个是构造方法传进来的Collection集合对象。继续看addAll的这个重载方法:
public boolean addAll(int index, Collection<? extends E> c) {
//检查index是否合法
checkPositionIndex(index);
//将Collection实例转为Object数组
Object[] a = c.toArray();
int numNew = a.length;
if (numNew == 0)
return false;
Node<E> pred, succ;
//index等于size时,只有两种情况:
//1.LinkedList中没有元素
//2.要添加的元素位置等于LinkedList长度
if (index == size) {
succ = null;
pred = last;
} else {
//寻找index位置存在的元素
succ = node(index);
//找到index位置存在的元素的前一个元素
pred = succ.prev;
}
for (Object o : a) {
@SuppressWarnings("unchecked") E e = (E) o;
//将对象包装成一个Node对象
Node<E> newNode = new Node<>(pred, e, null);
if (pred == null)
//如果index位置前一个元素为null,表示当前添加的是第一个元素
//将当前元素的包装对象设置为第一个
first = newNode;
else
//否则设置index位置前一个元素的下一个元素为当前新添加的元素
pred.next = newNode;
//添加完成,需要将pred设置为新添加的元素
pred = newNode;
}
if (succ == null) {
//如果添加前长度为0
//或者添加元素的位置在LinkedList长度之外
//那么LinkedList最后元素应该是最后添加的元素
last = pred;
} else {
//否者表示在已有元素中间添加元素
//那么最后添加的元素的下一个元素应该是添加前index位置对应的元素
pred.next = succ;
//添加前index位置的元素,设置前一个元素为最后添加的元素
succ.prev = pred;
}
//LinkedList长度增加
size += numNew;
modCount++;
return true;
}
复制代码
核心代码的逻辑相对ArrayList复杂了点,但也是比较简单的。其实整个LinkedList的结构就像俄罗斯套娃,每层套娃都用线连着外面和里面的套娃。
那么针对第二个问题,LinkedList为什么是读效率低,写效率高呢,我们接着往下看:
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
Node<E> node(int index) {
//因为LinkedList实现了Deque接口,所以LinkedList还是双向队列
//所以此处查找元素,最大的查找范围是最大长度的1/2
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
复制代码
还记得ArrayList的读操作吗,是通过数组下标直接找到对应元素,复杂度是O(1),而LinkedList是链表结构的,并没有下标,所以只能从头到尾遍历,或者从尾到头遍历查找,复杂度是O(n),所以LinkedList相对ArrayList来说,读效率很低。
那么为什么又说写效率高呢??我们接着看:
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
复制代码
上面代码不难看出,LinkedList添加元素,其实只需要设置添加的元素的前后元素引用,并将前后元素的相关属性设置为所需要添加的元素的引用,就完成了元素的添加。同理,删除元素,只需要移除元素,并将元素的前后元素相关属性重新设置,则完成删除操作。整个LinkedList的单个元素写操作,最多涉及3个元素的修改。
相对ArrayList添加或者删除元素都需要重新计算容量甚至扩容,再将部分甚至全部元素复制再移位的操作来说,LinkedList的写操作效率实在高太多。
对于最后一个问题,讲到目前为止,相信不用说大家都知道了。LinkedList允许添加重复的值,也允许添加null值,因为LinkedList并不是直接维护添加的元素,而是将添加的元素包装成Node对象来维护,所以添加什么元素都无所谓了。
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

