再谈Serverless无服务器架构(1.4)
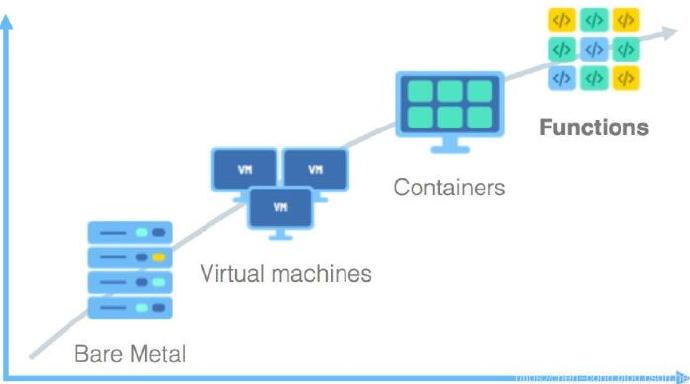
在19年的10月23日我整理过一篇Serverless架构学习的文章,今天再谈下对这个的理解。
首先我们还是看下对Serverless无服务器架构的一个基础说明。
Serverless是一种构建和管理基于微服务架构的完整流程,允许你在服务部署级别而不是服务器部署级别来管理你的应用部署。它与传统架构的不同之处在于,完全由第三方管理,由事件触发,存在于无状态(Stateless)、暂存(可能只存在于一次调用的过程中)计算容器内。构建无服务器应用程序意味着开发者可以专注在产品代码上,而无须管理和操作云端或本地的服务器或运行时。Serverless真正做到了部署应用无需涉及基础设施的建设,自动构建、部署和启动服务。
过去是“构建一个框架运行在一台服务器上,对多个事件进行响应”,Serverless则变为“构建或使用一个微服务或微功能来响应一个事件”,做到当访问时,调入相关资源开始运行,运行完成后,卸载所有开销,真正做到按需按次计费。这是云计算向纵深发展的一种自然而然的过程。
下面再谈下对Serverless无服务器架构的一些关键理解
通过拆分实现对应用基础设施的进一步弱化(中间件,容器,开发框架)
首先可以看到Serverless架构下本身就体现了微服务,而且这种微服务API的粒度更加细,更加小,一个API往往仅仅能够完成一个微功能。因此不再像传统应用必须是一个大的组件模块,实现多个功能并打包在一起。
大的功能拆分为微功能-》微功能本身拆分为无状态的微服务API
在完成了这种拆分后,要实现一个大功能那么就是对诸多的微服务API的的组装过程。
我们还是从传统的云平台说起,在传统的应用开发和云平台模式下,我们开发一个应用还是能够明确的感受到虚拟机,感受到中间件容器资源,同时应用开发必须依托一个很重的开发框架,类似springcloiud,类似传统的ssh框架等等。
但是新架构下可以看到没有复杂的开发框架,也没有重的中间件容器,只有一个个新粒度的微服务API,微功能的实现,这些实现也不存在传统的打包和部署动作。也就是说整个软件的开发过程实现完全的面向服务化,你可以使用第三方已有的服务,你开发完成的微功能也是服务,你呈现给用户的是多个服务的串联和组装。
在这种场景下没有任何的中间件资源需要你去关心和维护,类似传统模式下我们可能需要关心和运维我们的数据库,关心和运维我们的Tomcat容器服务器,我们有复杂的编译构建,打包部署动作,而这些在无服务器架构模式下都没有了。体现出现的是函数或事件,而函数本身也是服务。
传统云平台计费模式的一大转变-真正实现使用次数来计费
这个可以讲是Serverless无服务器架构带来的第二大转变,真正实现按使用次数计费。在传统云平台模式下可以看到,虚拟机或计算资源是固定分配给你了的,即使某天你的业务系统没有任何的访问请求,你也需要给云服务商缴费。
你为何需要固定分配的资源,简单来说还是你拿到一个虚拟机后,你还有很多的应用基础设施需要在虚拟机上安装部署和搭建,比如我们前面讲的中间件容器,网关,基础框架包,应用部署包等。而这些应用基础设施越重就越难以灵活的响应。
而到了Serverless无服务器架构下可以看到应用已经拆分为足够细的微功能或API,而这些微功能的运行本身需要极少的轻量化资源即可,因此我们能够实现对类似动态容器能力,快速申请获取容器资源,使用完成后快速的销毁释放资源。
所以你可以看到实现微服务化,实现FaaS或声明式API编程是走向按次动态收费的基础。
可以参考:
https://zhuanlan.zhihu.com/p/31122433
1. Serverless 是真正的按需使用,请求到来时才开始运行
2. Serverless 是按运行时间和内存来算钱的
3. Serverless 应用严重依赖于特定的云平台、第三方服务
对于AWS 官方对于 Serverless 的介绍是这样的: 无服务器架构是基于互联网的系统,其中应用开发不使用常规的服务进程。相反,它们仅依赖于第三方服务(例如AWS Lambda服务),客户端逻辑和服务托管远程过程调用的组合。
在一个基于 AWS 的 Serverless 应用里,应用的组成是:
1. 网关 API Gateway 来接受和处理成千上万个并发 API 调用,包括流量管理、授权和访问控制、监控等
2. 计算服务 Lambda 来进行代码相关的一切计算工作,诸如授权验证、请求、输出等等
3. 基础设施管理 CloudFormation 来创建和配置 AWS 基础设施部署,诸如所使用的 S3 存储桶的名称等
4. 静态存储 S3 作为前端代码和静态资源存放的地方
5. 数据库 DynamoDB 来存储应用的数据
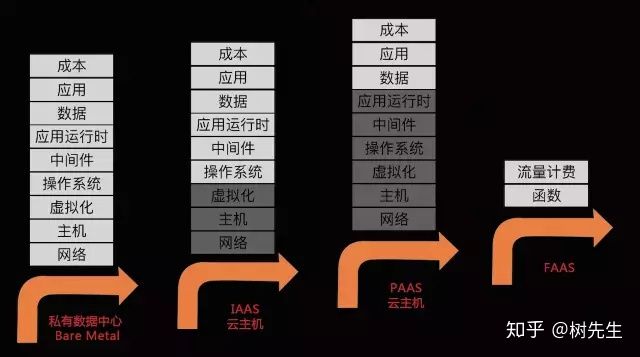
在Serverless架构下开发人员不再关心底层逻辑
简单来说最早的开发往往会涉及到操作系统,进一步的会涉及到数据库,应用中间件容器,然后是各类的开发框架,而这些在Serverless架构下开发人员不再关心,更多的是关心业务场景和业务功能的实现。
这里的不关心包括两个方便,一个是不会直接去安装部署和配置这些中间件,其次是不用去关心这些中间件或容器运行在哪里?更加不用自己运维这些中间件容器。简单来说,你真正要运维的就是你实现的服务API接口,你实现的事件或函数。
图片来源: https://zhuanlan.zhihu.com/p/79112228
目前业界的各类 Serverless 实现按功能而言,主要为应用服务提供了两个方面的支持:函数即服务(Function as a Service,FaaS)以及后台即服务(Backend as a Service,BaaS)。
而实际上我们看到最难的仍然是在类似数据库等原来的中间件资源能力的服务化,即我们对数据库的需求也变成了一个个可以拆分的微服务API请求。比如我们仅仅是一个爬虫采集后的数据存储这种单一场景往往比较容易实现,但是类似企业信息化系统这种底层复杂数据模型,强关系和强事务场景下往往就很难实现彻底意义上的数据库能够服务化。
正是这个原因我们看到类似Serverless架构前期更加适用于移动互联网,物联网IOT,面向互联网的聚合类应用实现上面,而对于传统企业信息化应用软件至少短期难看很难适用。
对于企业内的信息化,在企业传统IT架构转型过程中,重点还是云原生里面的微服务,服务网格和DevOps几个关键能力。即首先是微服务化拆分,其次通过服务网格去中心化,再次通过Devops实现和云端的快速对接和持续交付能力。
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

