Java实习生面试复习(二):HashMap
我是一名很普通的双非大三学生,跟很多同学一样,有着一颗想进大厂的梦。接下来的几个月内,我将坚持写博客,输出知识的同时巩固自己的基础,记录自己的成长和锻炼自己,备战2021暑期实习面试!奥利给!!
Map这个大家庭真的是成员很多呢,我们可以简单回忆一下有哪些,我这里例举几个: HashMap、TreeMap、LikedHashMap、ConcurrentHashMap(线程安全)、WeekHashMap、HashTable 。不记的话,可以搜搜其他文章回顾一下哦。本文只讨论HashMap
HashMap基本是我们在日常使用中频率特别高的一个数据结构类型了,同时也是面试经常问到的,围绕着HashMap能展开一系列问题,比如:
- HashMap底层是如何实现的?
- HashMap的扩容机制?
- HashMap为什么会出现死循环?
- HashMap在1.7和1.8有什么区别?做了哪些优化?
本文不对源码做过深的讨论,因为我觉得实习生应该还不需要了解的那么透彻,我们需要做的是知道这些东西,源码什么的,每一步怎么做的,感兴趣的同学可以自己看一下。
HashMap源码分析
1.HashMap中常见的属性
//HashMap的 初始容量为 16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
//最大容量
static final int MAXIMUM_CAPACITY = 1 << 30;
//默认的扩容因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//转换红黑树的临界值,当链表长度大于此值时,会把链表结构转换为红黑树结构
static final int TREEIFY_THRESHOLD = 8;
//转换链表的临界值,当元素小于此值时,会将红黑树结构转换成链表结构
static final int UNTREEIFY_THRESHOLD = 6;
//当数组容量大于 64 时,链表才会转化成红黑树
static final int MIN_TREEIFY_CAPACITY = 64;
//记录迭代过程中 HashMap 结构是否发生变化,如果有变化,迭代时会 fail-fast
transient int modCount;
//HashMap 的实际大小,可能不准(因为当你拿到这个值的时候,可能又发生了变化)
transient int size;
//存放数据的数组
transient Node<K,V>[] table;
// 扩容的门槛,有两种情况
// 如果初始化时,给定数组大小的话,通过 tableSizeFor 方法计算,数组大小永远接近于 2 的幂次方,比如你给定初始化大小 19,实际上初始化大小为 32,为 2 的 5 次方。
// 如果是通过 resize 方法进行扩容,大小 = 数组容量 * 0.75
int threshold;
/** HashMap中的内部类 **/
//链表的节点 1.7之前叫Entry,1.8之后叫Node
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
}
//红黑树的节点
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {}
复制代码
上面已经对属性写了注释,下面在补充一点:
-
什么是扩容因子("加载因子,负载因子")?扩容因子是用来判断当前数组("哈希桶")什么时候需要进行扩容,假设因子为0.5,那么HashMap的初始化容量是16,则16*0.5 = 8个元素的时候,HashMap就会进行扩容。
-
为什么扩容因子是0.75?这是均衡了时间和空间损耗算出来的值,因为当扩容因子设置比较大的时候,相当于扩容的门槛就变高了,发生扩容的频率变低了,但此时发生Hash冲突的几率就会提升,当冲突的元素过多的时候,变成链表或者红黑树都会增加了查找成本( hash 冲突增加,链表长度变长 )。而扩容因子过小的时候,会频繁触发扩容,占用的空间变大,比如重新计算Hash等,使得操作性能会比较高。
-
HashMap初始化容量是多少?在不指定capacity情况下,初始化容量是16,但 不是初始化的时候就创建了一个16大小的数组,而是在第一次put的时候去判断是否需要初始化 ,我感觉这有一点懒加载的味道。并且我们经常在一些文章,包括阿里巴巴开发手册中看到:" 集合初始化时,指定集合初始值大小 ",如果有很多数据需要储存到 HashMap 中,建议 HashMap 的容量一开始就设置成足够的大小,这样可以防止在其过程中不断的扩容,影响性能,比如 HashMap 需要放置1024 个元素,由于没有设置容量初始大小,随着元素不断增加,容量 7 次被迫扩大,resize 需要重建hash 表,严重影响性能 。
-
初始化容量为什么是16?为什么每次扩容是2的幂次方?因为在使用是2的幂的数字的时候,Length-1的值是所有二进制位全为1,这种情况下,index的结果等同于HashCode后几位的值。只要输入的HashCode本身分布均匀,Hash算法的结果就是均匀的。这是为了实现均匀分布。深入解释可以看这篇文章: HashMap中hash(Object key)原理,为什么(hashcode >>> 16)。
-
Node节点是什么?。node节点在1.7之前也叫entry节点,是HashMap存储数据的一个节点,主要有四个属性,hash,key,value,next,其实就是一个标准的链表节点,很容易理解。
-
链表什么时候会转换成红黑树?当链表长度大于等于 8 时,此时的链表就会转化成红黑树,转化的方法是:treeifyBin,此方法有一个判断, 当链表长度大于等于 8,并且整个数组大小大于 64 时 ,才会转成红黑树,当数组大小小于 64 时,只会触发扩容,不会转化成红黑树
-
增强 for 循环进行删除,为什么会出现ConcurrentModificationException?因为增强 for 循环过程其实调用的就是迭代器的 next () 方法,当你调用 map#remove () 方法进行删除时,modCount 的值会 +1,而这时候迭代器中的 expectedModCount 的值却没有变,导致在迭代器下次执行 next () 方法时,expectedModCount != modCount 就会报 ConcurrentModificationException 的错误。这其实是一种 快速失败的机制 ,java.util下面的集合类基本都是快速失败的,实现都一样,都是依靠这两个变量。
可以使用迭代器的remove()方法去删除,因为 Iterator.remove () 方法在执行的过程中,会把最新的modCount 赋值给 expectedModCount,这样在下次循环过程中,modCount 和 expectedModCount 两者就会相等。
HashMap在1.7和1.8有什么区别?做了哪些优化?
从文章开头贴出的代码属性中我们可以看出,1.8版本的HashMap的底层实际上是一个 数组+链表+红黑树 的结构,但是在 1.7的时候是没有红黑树 的,这正是1.8版本中对查询的优化,我们都知道链表的查询时间复杂度是O(n)的,因为它需要一个一个去遍历链表上所有的节点,所以当链表长度过长的时候,会严重影响 HashMap 的性能,而红黑树具有快速增删改查的特点,这样就可以有效的解决链表过长时操作比较慢的问题。于是在1.8中引入了红黑树。
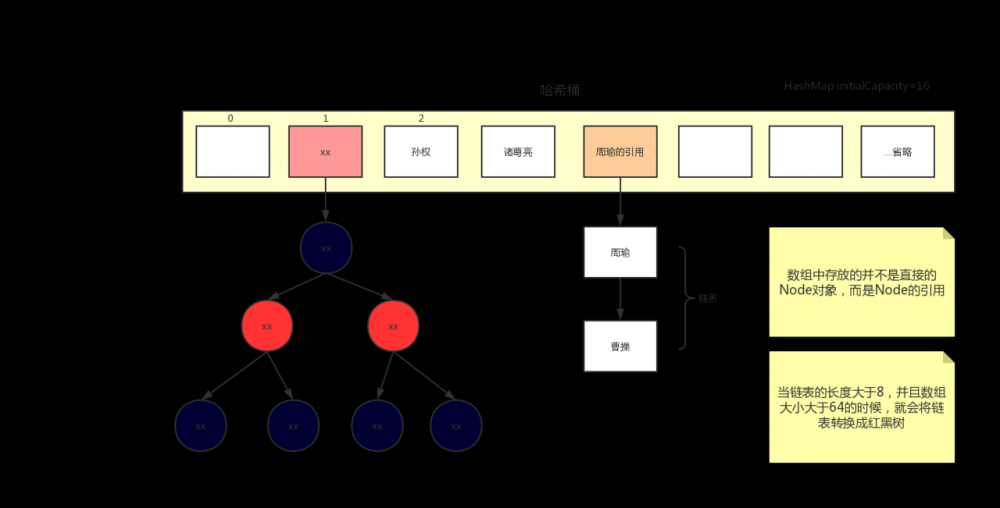
HashMap的新增
我们来看 1.8中HashMap的新增 图示,就不在晒那一大段的新增代码了。
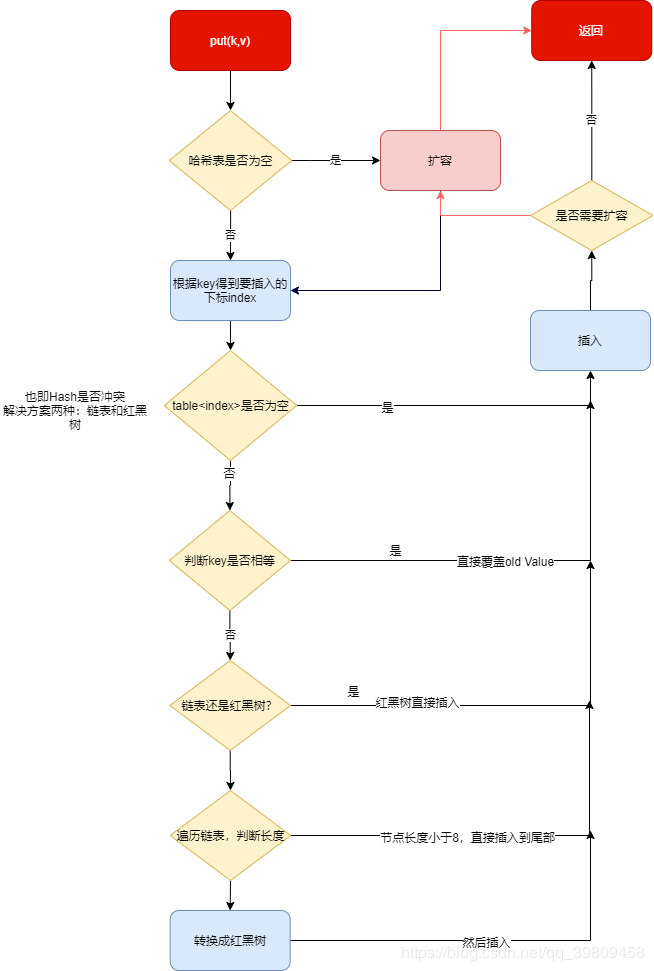
我们在文字总结描述一下,新增大概的步骤如下:
- 判断哈希表(数组)是否为空,第一次put的时候需要扩容(初始化);
- 通过 key 的 hash 计算出index,找到数组中对应的位置,并判断是否有值,有就跳转到 6,否则到 3;
- 如果 hash冲突,两种解决方案:链表 or 红黑树;
- 判断是红黑树,调用红黑树新增的方法;
- 如果是链表,递归循环,判断长度会不会大于8,大于8就先转换成红黑树,在调用4;
- 根据 onlyIfAbsent 判断是否需要覆盖,然后插入;
- 判断是否需要扩容,需要扩容进行扩容,结束。
HashMap的扩容
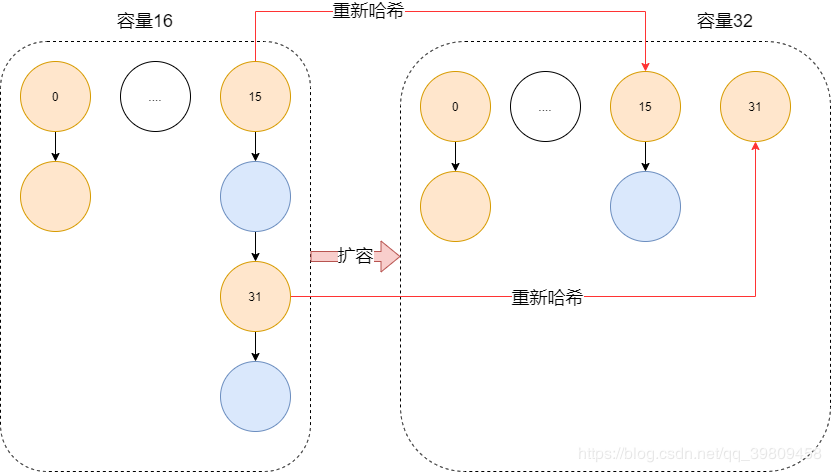
的时候会触发扩容,那么它是怎么扩容的? 注意:这样的元素个数和数组大小是有区别的,元素个数是指hashmap中node的个数,并不是指数组的大小。
- 扩容:创建一个新的Node(Entry)空数组,长度是原数组的2倍。
- ReHash:遍历原Node(Entry)数组,把所有的Node重新Hash到新数组。
为什么需要重新计算Hash?
1.7中计算下标:
static int indexFor(int h, int length) {
return h & (length-1);
}
// n 表示数组的长度,i 为数组索引下标
1.8中计算下标:tab[i = (n - 1) & hash])
// 1.8中的高位运算
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
复制代码
在jdk1.7中有indexFor(int h, int length)方法。jdk1.8里没有1.8中用tab[(n - 1) & hash]代替但原理一样。从上我们可以看出是因为长度扩大以后,Hash的规则也随之改变。这在1.7和1.8中差别不大,但是1.7需要与新的数组长度进行重新hash运算,这个方式是相对耗性能的,而在1.8中对这一步进行了优化,采用高位运算取代了ReHash操作,其实这是一种规律,因为每次扩容,其实元素的新位置就是 原位置+原数组长度 ,不懂的可以看 jdk8之HashMap resize方法详解(深入讲解为什么1.8中扩容后的元素新位置为原位置+原数组长度)
既然说到扩容,那么肯定会扯出1.7HashMap的死循环问题
我们都知道1.7之前,JDK是头插法,考虑头插法的原因是不用遍历链表,提高插入性能,但在JDK8已经改为尾插法了,不存在这个死循环问题,所以问题就出在头插法这。 我觉得这篇文章在这写的很清楚,想深入了解一下产生死循环的过程,可以看这篇文章: 老生常谈,HashMap的死循环 。总结一下来说就是:Java7在多线程操作HashMap时可能引起死循环,原因是扩容转移后前后链表顺序倒置,在转移过程中修改了原来链表中节点的引用关系。Java8在同样的前提下并不会引起死循环,原因是扩容转移后前后链表顺序不变,保持之前节点的引用关系。
那么1.8之后,HashMap就是线程安全的了嘛? 首先我们要知道所谓线程安全是对(读/写)两种情况都是数据一致而言的,而只读且不变化的话,HashMap也是线程安全的,之所以不安全是在写的时候,索引构建的时候会产生构建不一致的情况,比如无法保证上一秒put的值,下一秒get的时候还是原值,所以线程安全还是无法保证,所以要问面试官有没有读写并存的情况。且java.util下面的集合类基本都不是线程安全的。所以HashMap 是非线程安全的,我们可以自己在外部加锁,或者通过 Collections#synchronizedMap 来实现线程安全,Collections#synchronizedMap 的实现是在每个方法上加上了 synchronized 锁;或者使用ConcurrentHashMap
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

