再谈JVM内存参数调整(200331)
记得在2010年左右,在我博客上写过一些关于JVM内存参数优化的文章,主要是当时项目遇到了频繁的full gc和内存溢出的问题。后面不断的优化调整JVM启动参数后有了明显的改善。
首先我们看下这篇文章的一些关键总结:
https://blog.csdn.net/qq_38777579/article/details/82321717
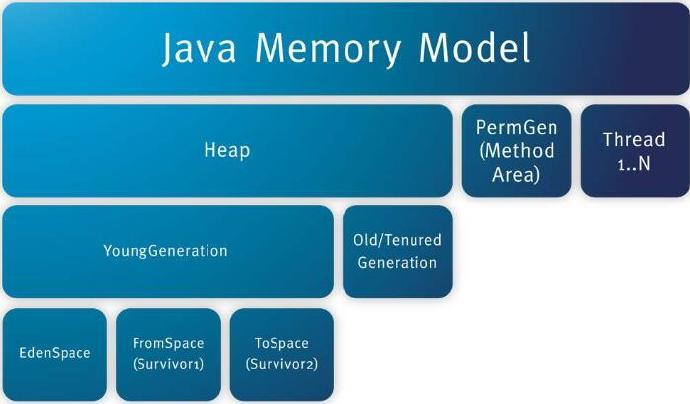
1.堆内存占据了JVM的大部分内存 ,同时它又可以细分为年轻代(Young Generation)和老年代(Old Generation)两块,其中新生代又可进一步细分为伊甸区(Eden Space),幸存者区域(Survivor Space), 默认情况下年轻代按照 8:1:1比例分配。
2.方法区存储类信息,常量,静态变量等数据 ,与堆内存同属线程共享区,为与。
注意新内存模型下这块对应到Metaspace。
3.栈区分为虚拟机栈(和本地栈(native method stack)用于方法的执行,为线程私有。
补充:Java堆是垃圾收集器管理的主要区域,因此很多时候也被称做“GC堆”。如果从内存回收的角度看,由于现在收集器基本都是采用的分代收集算法,所以Java堆中还可以细分为:新生代和老年代;再细致一点的有Eden空间、From Survivor空间、To Survivor空间等。
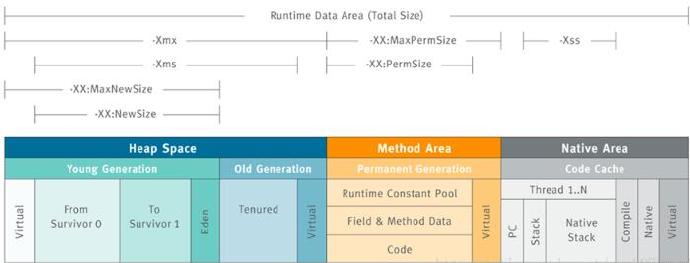
其中JVM启动的主要控制参数说明如下:
-Xmx设置最大堆空间
-Xms设置最小堆空间
-XX:MaxNewSize设置最大新生代空间
-XX:NewSize设置最小新生代空间
-XX:MaxPermSize设置最大永久代空间(注:新内存模型已经替换为Metaspace)
-XX:PermSize设置最小永久代空间(注:新内存模型已经替换为Metaspace)
-Xss设置每个线程的堆栈大小
那么这些值究竟设置多大合适,我们再看下这篇文章的一些说明:
https://blog.csdn.net/losetowin/article/details/78569001
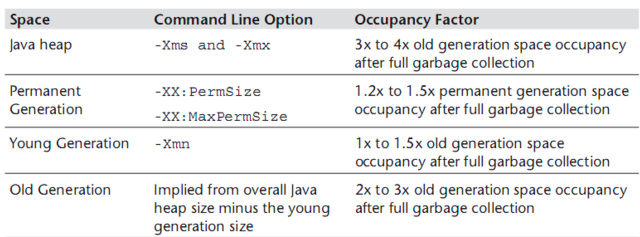
具体来讲:
Java整个堆大小设置,Xmx 和 Xms设置为老年代存活对象的3-4倍,即FullGC之后的老年代内存占用的3-4倍
永久代 PermSize和MaxPermSize设置为老年代存活对象的1.2-1.5倍。
年轻代Xmn的设置为老年代存活对象的1-1.5倍。
老年代的内存大小设置为老年代存活对象的2-3倍。
BTW:
1. Sun官方建议年轻代的大小为整个堆的3/8左右, 所以按照上述设置的方式,基本符合Sun的建议。
2. 堆大小=年轻代大小+年老代大小, 即xmx=xmn+老年代大小 。 Permsize不影响堆大小。
3. 为什么要按照上面的来进行设置呢? 没有具体的说明,但应该是根据多种调优之后得出的一个结论。
如何确认老年代存活对象大小?
方式1(推荐/比较稳妥)
JVM参数中添加GC日志,GC日志中会记录每次FullGC之后各代的内存大小,观察老年代GC之后的空间大小。可观察一段时间内(比如2天)的FullGC之后的内存情况,根据多次的FullGC之后的老年代的空间大小数据来预估FullGC之后老年代的存活对象大小(可根据多次FullGC之后的内存大小取平均值)
方式2:(强制触发FullGC, 会影响线上服务,慎用)
方式1的方式比较可行,但需要更改JVM参数,并分析日志。同时,在使用CMS回收器的时候,有可能不能触发FullGC(只发生CMS GC),所以日志中并没有记录FullGC的日志。在分析的时候就比较难处理。BTW:使用jstat -gcutil工具来看FullGC的时候, CMS GC是会造成2次的FullGC次数增加。 具体可参见之前写的一篇关于jstat使用的文章。所以,有时候需要强制触发一次FullGC,来观察FullGC之后的老年代存活对象大小。
注:强制触发FullGC,会造成线上服务停顿(STW),要谨慎,建议的操作方式为,在强制FullGC前先把服务节点摘除,FullGC之后再将服务挂回可用节点,对外提供服务。在不同时间段触发FullGC,根据多次FullGC之后的老年代内存情况来预估FullGC之后的老年代存活对象大小
其它说明:
GC(Allocation Failure)
注意出现该错误, 说明的是本次是一次minor gc,但是引起这次gc收集的原因不是老年代内存不够用了,而是新生代内存空间不够 。但是本次执行这次gc的时候新老年代的内存都会进行回收。
如果出现这个错误,需要看下上面谈到的堆内存大小和新生代内存大小的比例关系。比如两种说法都可以,一种说法是新生代占整个堆的3/8,如果堆内存为8个g,那么新生代最大内存设置应该为3g。另外一种说明是新生代和老生代的比例为1:3左右,即堆整体大小的时候新生代设置为2g,老生代则为6给。
因此在整体的堆内存分配为8g的情况下,实际新生代内存分配应该在2到3g之间。
注:在gc日志里面有 GC(Allocation Failure) 是正常的,说明因为新生代不够而进行minor gc,不需要刻意去解决。同时也可以看到在进行minor gc的时候新老生代的内存都会进行回收。而实际上如果将新生代内存调整到2g或更大,往往会触发更多的cms gc和full gc操作。
MetaspaceSize 和 PermSize
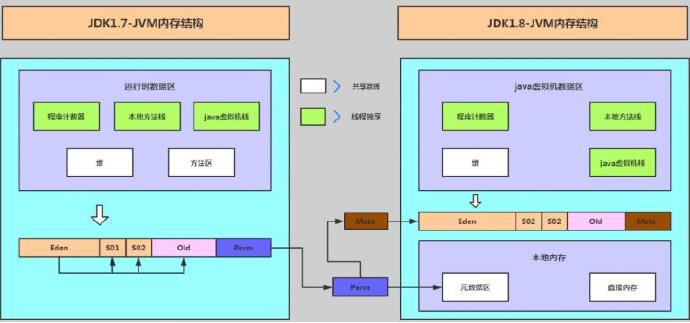
随着JDK8的到来,永久代最终被移除,方法区移至Metaspace,字符串常量移至Java Heap。JVM不再有PermGen。但类的元数据信息(metadata)还在,只不过不再是存储在连续的堆空间上,而是移动到叫做“Metaspace”的本地内存(Native memory)中。
https://www.cnblogs.com/duanxz/p/3520829.html
JDK8+移除了Perm,引入了Metapsace,它们两者的区别是什么呢?Metasace上面已经总结了,无论-XX:MetaspaceSize和-XX:MaxMetaspaceSize两个参数如何设置,都会从20.8M开始,随着类加载越来越多不断扩容调整,上限是-XX:MaxMetaspaceSize,默认是几乎无穷大。
而Perm的话,我们通过配置-XX:PermSize以及-XX:MaxPermSize来控制这块内存的大小,jvm在启动的时候会根据-XX:PermSize初始化分配一块连续的内存块,这样的话,如果-XX:PermSize设置过大,就是一种赤果果的浪费。
Metaspace的组成
Klass Metaspace :Klass Metaspace就是用来存klass的,klass是我们熟知的class文件在jvm里的运行时数据结构,不过有点要提的是我们看到的类似A.class其实是存在heap里的,是java.lang.Class的一个对象实例。
NoKlass Metaspace:NoKlass Metaspace 专门来存klass相关的其他的内容,比如method,constantPool等,这块内存是由多块内存组合起来的,所以可以认为是不连续的内存块组成的。这块内存是必须的,虽然叫做NoKlass Metaspace,但是也其实可以存klass的内容,上面已经提到了对应场景。
对于MetaspaceSize
如果没有配置参数-XX:MetaspaceSize,那么触发FGC的阈值就是21807104(约20.8M);
如果配置了参数-XX:MetaspaceSize=256m,那么触发FGC的阈值就是配置的值256M;
所以可以看到MetaspaceSize值也不能设置的太小,否则容易频繁的触发full gc操作。另外你开始设置的大实际仍然不会起左右,都会从20m左右的最小值开始递增。
Java虚拟机内存区域概述: https://www.cnblogs.com/wanxi/p/6476244.html
CMS GC的详细过程说明
参考: https://www.cnblogs.com/zhangxiaoguang/archive/2016/08/23/5792468.html
参考: https://www.jianshu.com/p/d6dc357b7770
CMS,全称Concurrent Low Pause Collector ,是jdk1.4后期版本开始引入的新gc算法,在jdk5和jdk6中得到了进一步改进,它的主要适合场景是对响应时间的重要性需求 大于对吞吐量的要求,能够承受垃圾回收线程和应用线程共享处理器资源,并且应用中存在比较多的长生命周期的对象的应用。
CMS是用于对tenured generation的回收,也就是年老代的回收,目标是尽量减少应用的暂停时间,减少full gc发生的几率,利用和应用程序线程并发的垃圾回收线程来标记清除年老代。 在我们的应用中,因为有缓存的存在,并且对于响应时间也有比较高的要求,因此希望能尝试使用CMS来替代默认的server型JVM使用的并行收集器,以便获得更短的垃圾回收的暂停时间,提高程序的响应性。
1.初始标记:为了收集应用程序的对象引用需要暂停应用程序线程,该阶段完成后,应用程序线程再次启动。
2.并发标记:从第一阶段收集到的对象引用开始,遍历所有其他的对象引用。
3.并发预清理:改变当运行第二阶段时,由应用程序线程产生的对象引用,以更新第二阶段的结果。
4.重标记:由于第三阶段是并发的,对象引用可能会发生进一步改变。因此,应用程序线程会再一次
被暂停以更新这些变化,并且在进行实际的清理之前确保一个正确的对象引用视图。
这一阶段十分重要,因为必须避免收集到仍被引用的对象。
5.并发清理:所有不再被应用的对象将从堆里清除掉。
6.并发重置:收集器做一些收尾的工作,以便下一次GC周期能有一个干净的状态。
其中4个阶段(名字以Concurrent开始的)与实际的应用程序是并发执行的,而其他2个阶段需要暂停应用程序线程(STW)。
注:在我们观察gc回收数据的时候看到,实际在进行cms gc操作的时候,在 GC (CMS Final Remark)这个步骤后,堆内存并没有降低下来。但是后续的minor gc已经显示堆内存明显减少。在这个中间也没有看到有进行full gc的日志数据信息。暂时不清楚具体原因。
CMS是不会整理堆碎片的,因此为了防止堆碎片引起full gc,通过会开启CMS阶段进行合并碎片选项:-XX:+UseCMSCompactAtFullCollection,开启这个选项一定程度上会影响性能,可以通过配置适当的CMSFullGCsBeforeCompaction来调整性能。
默认CMS是在tenured generation占满68%的时候开始进行CMS收集,如果你的年老代增长不是那么快,并且希望降低CMS次数的话,可以适当调高此值:-XX:CMSInitiatingOccupancyFraction=80
这里修改成80%占满的时候才开始CMS回收。
注意,我们看到当NewSize新生代的大小调整大后,每次从新生代朝老生代搬移的内存也随着增大,这个时候如果仍然保留80%才进行cms gc操作的话,往往会导致更加频繁的cms gc操作。
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

