Flink —— 基本组件与 WordCount
小白的新手学习笔记,请大佬轻喷
本文归档于 GitHub ,欢迎大家批评指正
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Flink has been designed to run in all common cluster environments , perform computations at in-memory speed and at any scale .
以上为 Flink 的官方定义,其核心表达为:Apache Flink 是一个分布式处理引擎框架,用于无边界和有边界的流式状态计算,且有部署及性能等诸多优势。
Flink 的数据处理方法基于流式处理架构,是一种真正的流处理、流计算框架,其中的很多概念及思想模式对于大数据处理方法具有启发意义。 Flink 官网 对于 Stream , State , Time 等组件做了详细的解释和说明。在下文中完成大数据版 Hello,World 的编写与运行,同时继续理解官方文档。
Demo
本实例采用 JDK11 环境搭建。
Maven 依赖
首先,创建一个 Maven 项目,并添加必要的依赖。
<properties>
<flink.version>1.10.0</flink.version>
<scala.version>2.12</scala.version>
<log.version>2.0.0-alpha1</log.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
<!--IDEA 运行时需要注释-->
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.version}</artifactId>
<version>${flink.version}</version>
<!--IDEA 运行时需要注释-->
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>${log.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${log.version}</version>
</dependency>
</dependencies>
复制代码
官方教程中指出,所有这些依赖项的作用域都应该设置为 provided ,这意味着需要这些依赖进行编译,但不应将它们打包到项目生成的应用程序 jar 文件中– 因为这些依赖项是 Flink 的核心依赖,在应用启动前已经是可用的状态了。
但是,将这些依赖的作用域设置为 provided 时运行程序会出现 java.lang.NoClassDefFoundError 错误。所以,在使用 IDEA 运行程序时,将作用域更改为 compile 。
批处理示例搭建
本次实例搭建采用官方的 WordCount 示例,进行少许的改动,代码如下。
public class Main {
public static void main(String[] args) throws Exception {
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSet<String> text = env.fromElements(
"Who's there?",
"I think I hear them. Stand, ho! Who's there?");
DataSet<Tuple2<String, Integer>> counts =
// 把每一行文本切割成二元组,每个二元组为: (word,1)
text.flatMap(new Tokenizer())
// 根据二元组的第“0”位分组,然后对第“1”位求和
.groupBy(0)
.sum(1);
counts.print();
}
public static class Tokenizer implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
// 统一大小写并把每一行切割为单词
String[] tokens = value.toLowerCase().split("//W+");
// 消费二元组
for (String token : tokens) {
if (token.length() > 0) {
out.collect(new Tuple2<String, Integer>(token, 1));
}
}
}
}
}
复制代码
使用 IDEA 运行程序,在解决上述的依赖编译问题之后,程序可以正常运行,并输出如下结果。
(hear,1) (ho,1) (s,2) (i,2) (stand,1) (who,2) (them,1) (there,2) (think,1) 复制代码
异常警告处理
虽然如上文所言,程序正常运行且输出正确结果,但是同时也会有 log4j 的警告输出。
log4j:WARN No appenders could be found for logger (org.apache.flink.api.java.ExecutionEnvironment). log4j:WARN Please initialize the log4j system properly. log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info. 复制代码
该错误由于没有配置日志的输出源导致,可以通过添加 log4j 的输出源相关配置解决,添加配置文件 log4j.properties 。
log4j.rootLogger=WARN, console log4j.appender.console=org.apache.log4j.ConsoleAppender log4j.appender.console.layout=org.apache.log4j.PatternLayout log4j.appender.console.layout.conversionPattern=%5p [%t] (%F:%L) - %m%n 复制代码
日志输出源的问题得到解决,但是由于 JDK9 之后禁止从类路径上的代码进行非法的反射访问,会出现如下警告信息。
WARNING: An illegal reflective access operation has occurred WARNING: Illegal reflective access by org.apache.flink.core.memory.MemoryUtils (file:org/apache/flink/flink-core/1.10.0/flink-core-1.10.0.jar) to constructor java.nio.DirectByteBuffer(long,int) WARNING: Please consider reporting this to the maintainers of org.apache.flink.core.memory.MemoryUtils WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations WARNING: All illegal access operations will be denied in a future release 复制代码
根据警告信息提示,通过设置启动参数 --illegal-access=warn 启动进一步的警告信息,获得详细警告信息如下所示。
WARNING: Illegal reflective access by org.apache.flink.core.memory.MemoryUtils (file:org/apache/flink/flink-core/1.10.0/flink-core-1.10.0.jar) to constructor java.nio.DirectByteBuffer(long,int) WARNING: Illegal reflective access by org.apache.flink.core.memory.HybridMemorySegment (file:org/apache/flink/flink-core/1.10.0/flink-core-1.10.0.jar) to field java.nio.Buffer.address WARNING: Illegal reflective access by WARNING: Illegal reflective access by org.apache.flink.shaded.akka.org.jboss.netty.util.internal.ByteBufferUtil (file:org/apache/flink/flink-runtime_2.12/1.10.0/flink-runtime_2.12-1.10.0.jar) to method java.nio.DirectByteBuffer.cleaner() 复制代码
由警告信息可看出来,主要原因是 java.nio 的访问或反射权限的问题,通过添加 --add-opens java.base/java.nio=ALL-UNNAMED 启动参数来“打开”这个包的访问权限,从而解决该警告问题。
最终,系统最终文件层次结构如下所示。
hello-flink/
│ pom.xml
│
└─src
├─main
│ ├─java
│ │ Main.java
│ │
│ └─resources
│ log4j.properties
│
└─test
└─java
复制代码
流处理示例搭建
本次实例搭建采用官方 API 中的 WordCount Streaming 版示例,进行少许的改动,代码如下。
public class Main {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> text = env.socketTextStream("127.0.0.1", 9000);
DataStream<Tuple2<String, Integer>> dataStream = text.flatMap((FlatMapFunction<String, Tuple2<String, Integer>>) (s, collector) -> {
String[] tokens = s.toLowerCase().split("//W+");
for (String token : tokens) {
if (token.length() > 0) {
collector.collect(new Tuple2<>(token, 1));
}
}
}).keyBy(0).timeWindow(Time.seconds(5)).sum(1);
dataStream.print();
env.execute("Java WordCount from SocketTextStream Example");
}
}
复制代码
注意:
-
如果不启动本地 Flink 集群,则需要先启动 netcat:nc -l -p 9000,否则会出现如下错误:
Exception in thread "main" org.apache.flink.api.common.functions.InvalidTypesException: The return type of function 'main(Main.java:54)' could not be determined automatically, due to type erasure. You can give type information hints by using the returns(...) method on the result of the transformation call, or by letting your function implement the 'ResultTypeQueryable' interface. at org.apache.flink.api.dag.Transformation.getOutputType(Transformation.java:451) at org.apache.flink.streaming.api.datastream.DataStream.getType(DataStream.java:178) at org.apache.flink.streaming.api.datastream.DataStream.keyBy(DataStream.java:321) at Main.main(Main.java:62) Caused by: org.apache.flink.api.common.functions.InvalidTypesException: The generic type parameters of 'Collector' are missing. In many cases lambda methods don't provide enough information for automatic type extraction when Java generics are involved. An easy workaround is to use an (anonymous) class instead that implements the 'org.apache.flink.api.common.functions.FlatMapFunction' interface. Otherwise the type has to be specified explicitly using type information. at org.apache.flink.api.java.typeutils.TypeExtractionUtils.validateLambdaType(TypeExtractionUtils.java:350) at org.apache.flink.api.java.typeutils.TypeExtractionUtils.extractTypeFromLambda(TypeExtractionUtils.java:176) at org.apache.flink.api.java.typeutils.TypeExtractor.getUnaryOperatorReturnType(TypeExtractor.java:571) at org.apache.flink.api.java.typeutils.TypeExtractor.getFlatMapReturnTypes(TypeExtractor.java:196) at org.apache.flink.streaming.api.datastream.DataStream.flatMap(DataStream.java:634) at Main.main(Main.java:54) 复制代码 -
如果 JDK 版本为 9 以上,则启动参数中添加
--add-opens java.base/java.lang=ALL-UNNAMED,原因同批处理。
Stream
Stream 可以通过任何形式、任何类型的数据形成,例如:系统日志、交易记录等。它是流处理系统最核心要素,也是 Flink 框架的最基本组件。正如官方定义中所说的,它可以用于无边界的流式计算也可以用于有边界的流式计算。流的边界及其处理方式成为学习理解 Flink 框架使用及其思想模式的重要内容。
流的界限
流可以分为 有界流 与 无界流 。
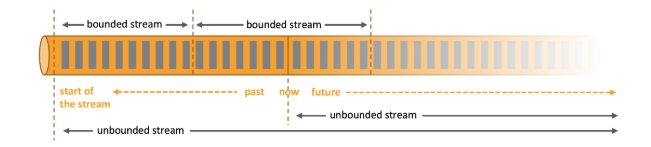
正如上文所提到的系统日志和交易记录,这两种流可以理解为 无界流 ,因为这种数据只定义了开始,而没有定义结束时间。它会随着时间的推移,无休止地产生数据,逐渐膨胀,且不会有尽头。因此,无界流必须被 持续 地处理,即当事件发生或者数据产生时就立刻进行计算。
有界流 则不同,它有始有终。例如本次完成的 WrodCount 的文档版次数统计,就是一种有界流处理。再比如说传统的数据分析系统 OLAP ,通过对历史数据的多维展示达到数据分析的目的。 有界流 有一个重要的特点,就是可以对流或者数据进行精确地度量,比如 1000 词的文档,或者 1TB 的历史数据。因此, 有界流 可以在某个时间节点精准的开始和结束。
数据处理方式
数据流分为有界和无界,同时也会对应不同的数据处理方式: 批处理 和 流处理 。
在 Flink 的架构观中,一切都是流。所以在流式处理中,输入数据来一个处理一个,并流式输出处理结果,如下图所示。
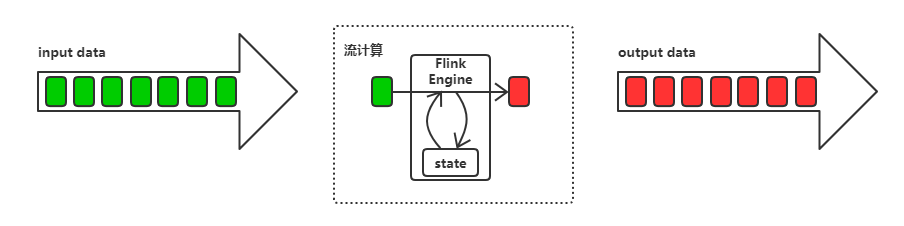
Flink 的批处理依然是基于流式的处理。简而言之,就是把输入数据切割为一段段有界流,然后经过数据引擎的处理之后流式地输出多段有界流的结果。
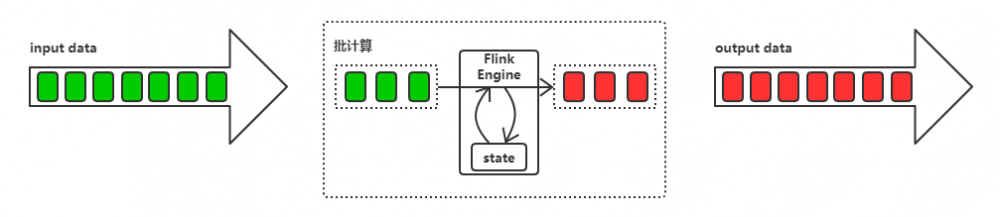
为了加深对 Flink 流式的架构观,进行 Spark 批处理思想的对比,一种完全不同的架构观念。
在 Spark 的架构观,一切都是“批”或者“批次”。会在存储一定量的批数据之后进行统一的数据计算处理,也就是所谓的来一批处理一批,并批量输出结果。

相比于 Flink 的流式处理,Spark Streaming 可以称为准流式处理,也就是微批处理。就是将批次做的足够小,即一个为一批,可以做到来一个处理一批。

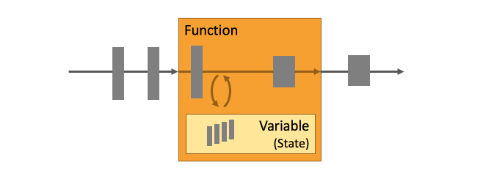
State
只有在每一个单独的事件上进行转换操作的应用才不需要状态,换言之,每一个具有一定复杂度的流处理应用都是有状态的。任何运行基本业务逻辑的流处理应用都需要在一定时间内存储所接收的事件或中间结果,以供后续的某个时间点(例如收到下一个事件或者经过一段特定时间)进行访问并进行后续处理。
如批处理实例中的 flatMap 操作将文本切割成二元组,并作为状态存在内存中,以提供后续分组求和时使用。
Time
时间是流处理应用另一个重要的组成部分。因为事件总是在特定时间点发生,所以大多数的事件流都拥有事件本身所固有的时间语义。进一步而言,许多常见的流计算都基于时间语义,例如窗口聚合、会话计算、模式检测和基于时间的 join。流处理的一个重要方面是应用程序如何衡量时间,即区分事件时间(event-time)和处理时间(processing-time)。
正文到此结束
- 本文标签: 参数 java Word 大数据 IO HTML dist maven map FAQ 代码 lambda value rmi http https IDE NIO App example 编译 Logging apr GitHub token key 统计 git 数据 ORM CTO final root kk 集群 Netty 分布式 XML core struct UI Action 注释 部署 dependencies apache ACE cat API id 实例 src pom 配置 scala 时间 stream
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

