面试官:能从源码聊聊dubbo的内核吗
dubbo的内核,值的是,dubbo中所有的功能,都是基于它之上完成的。dubbo的内核包括SPI,AOP,DI和Compiler。
dubbo的SPI机制和源码分析
SPI,service provider interface,服务提供者接口,就是服务发现的一种机制。
dubbo的SPI规范
dubbo的SPI机制是在JDK的SPI机制上进行的改进。
- 接口名:接口名称可以随意
- 实现类名:在接口名称前面加上一个可以表示自身功能的标识前缀。
- 提供者配置文件路径:依次查找的顺序
- META-INF/dubbo/internal
- META-INF/dubbo
- META-INF/services
- 提供者配置文件名称:接口的全限定名
- 提供者配置文件内存:文件内容为key=value形式,value为该接口实现类的全限定名,key可以随意,但是一般为前缀标识。一个类名占一行。
- 提供者加载:ExtensionLoader类,用于加载提供者配置文件中的所有类,并创建相应的实例。
Adaptive机制
扩展类的自适应机制,可以指定想要加载的扩展名,不知道就会加载默认扩展类。通过@Adaptive注解实现。而该注解可以修饰方法和类,区别很大。
- 修饰类:被该注解修饰的类称为Adaptive类,表示SPI扩展会按照类中指定的方式去加载扩展类。
- 修饰方法:如果系统中没有找到Adaptive类,找到被注解修饰的方法,则会根据Adaptive方法自动生成Adaptive类,并将其编译。
Adaptive的方法规范:
动态生成Adaptive类的格式
package <SPI 接口所在包>;
public class SPI 接口名$Adpative implements SPI 接口 {
public adaptiveMethod (arg0, arg1, ...) {
// 注意,下面的判断仅对 URL 类型,或可以获取到 URL 类型值的参数进行判断
// 例如,dubbo 的 Invoker 类型中就包含有 URL 属性
if(arg1==null) throw new IllegalArgumentException(异常信息);
if(arg1.getUrl()==null) throw new IllegalArgumentException(异常信息);
URL url = arg1.getUrl();
// 其会根据@Adaptive 注解上声明的 Key 的顺序,从 URL 获取 Value,
// 作为实际扩展类。若有默认扩展类,则获取默认扩展类名;否则获取
// 指定扩展名。
String extName = url.get 接口名() == null?默认扩展前辍名:url.get 接口名();
if(extName==null) throw new IllegalStateException(异常信息);
SPI 接口 extension = ExtensionLoader.getExtensionLoader(SPI 接口.class)
.getExtension(extName);
return extension.adaptiveMethod(arg0, arg1, ...);
}
public unAdaptiveMethod( arg0, arg1, ...) {
throw new UnsupportedOperationException(异常信息);
}
}
复制代码
从上面生成的格式中知道,生成的Adpative类是用过参数URL获取知道要加载的扩展类的类名,如果没有获取到扩展名,则获取默认的扩展类。因此,对应Adpative类的规范是其参数类型是URL,或者能获取到URL类型的值。
Wrapper机制
扩展类的包装机制,就是对扩展类中SPI接口方法进行增强,进行包装,wrapper是装饰者模式的应用,一个SPI包括多个wrapper。注意,wrapper类不属于扩展类。 Wrapper类是通过Wrapper类实现的。 Wrapper定义的时候需要遵循如下规范:
- 该类中要实现SPI接口
- 该类中需要有SPI接口的引用
- 在实现的方法中要调用SPI接口对应的方法
- 正常需要以Wrapper结尾
Active机制
扩展类的激活机制,通过指定条件来激活当前的扩展类,是通过@Active注解实现的。直接加在扩展类上就可以了,用来添加一个可用于加载选择的标签。一共有5种熟悉,两种过时了,对应的意义为:
- group:为扩展类指定所属的类别。String[],表示一个扩展类可以属于多个组。
- value:为当前扩展类指定的key,是当前扩展类的一个标识。String[]类型,值就是配置文件中扩展类的扩展名。
- order:指定相同的扩展类的加载顺序,序号越小,优先级越高,默认为0。若相同,则按照注册顺序的倒序进行加载。
SPI的源码分析
我们先来理下扩展类的一个获取过程,首先要获取一个扩展类,就要获取这个扩展类的ExtensionLoader实例,而ExtensionLoader实例是需要通过ExtensionFactory创建的,而ExtensionFactory又需要ExtensionFactory的ExtensionLoader,这个ExtensionFactory的ExtensionLoader的ExtensionFactory是null。下面我们看下整个流程图,会清晰一些:
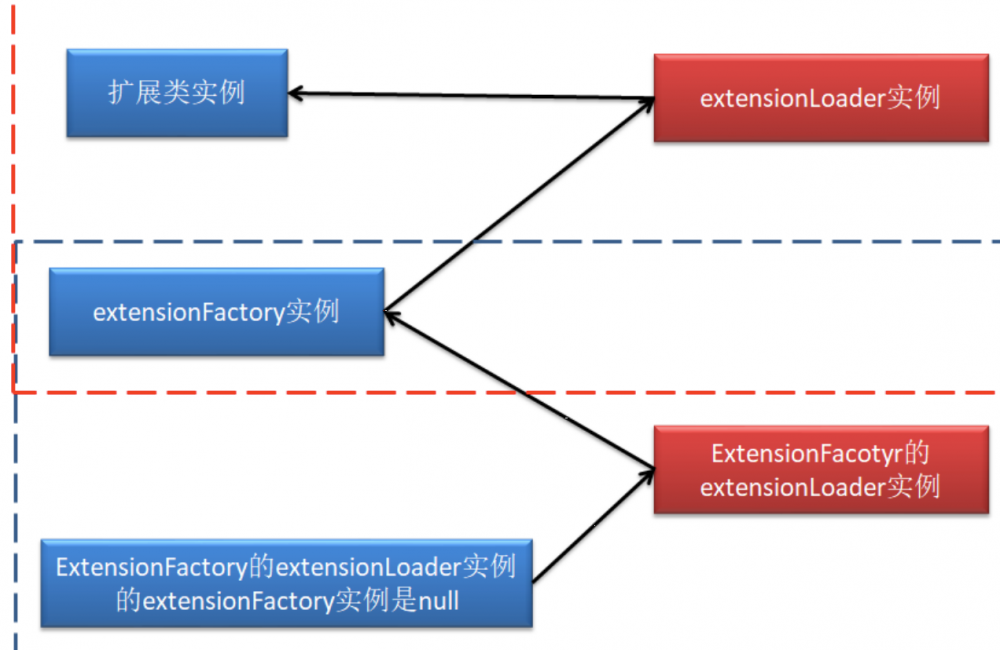
我们可以从ExtensionLoader的getExtensionLoader开始

这里我们看到创建过程就是直接new 了一个ExtensionLoader,那么我们看下对应的构造方法

这里我们就可以看到,如果需要获取的扩展类的类型是ExtensionFactory那就返回null,也就是刚才说的ExtensionFactory的ExtensionLoader的ExtensionFactory是null,否则就获取ExtensionFactory的ExtensionLoader,并且获取ExtensionFactory的自适应扩展类。我们可以直接查看ExtensionFactory的自适应扩展类是AdaptiveExtensionFactory。到这里我们就已经获取到了扩展类的ExtensionLoader。 接下去需要通过ExtensionLoader去获取对应的扩展类,因此,我们跟入ExtensionLoader的getExtension方法。

这里我们看到了,dubbo使用Holder和双重检测锁来构建一个单例,也就是每个扩展类都是单例模式。我们继续进入createExtension。我们先看第一行

我们进行进入getExtensionClasses方法
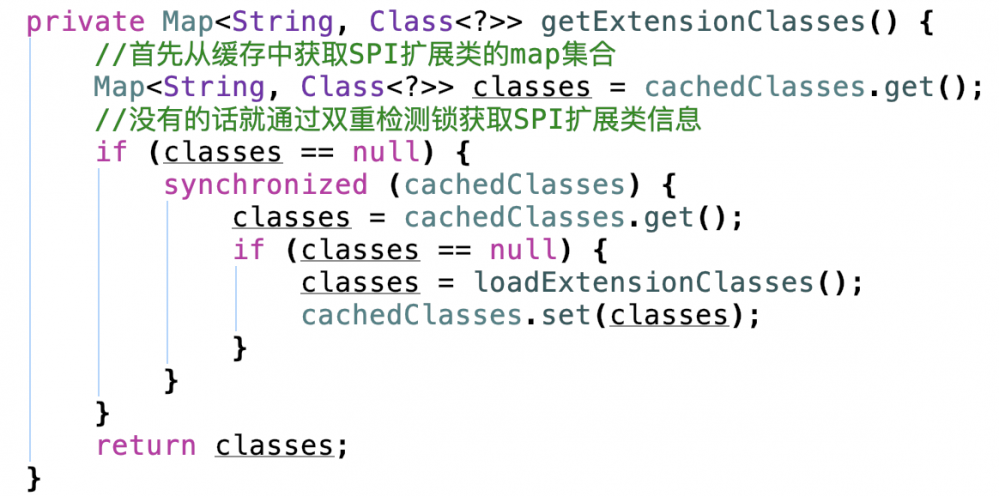
这里同样用了双重检测所和Holder模式,因为这个map集合用的是HashMap。继续进入loadExtensionClasses方法。

这里就是加载我们之前说的三个路径下的扩展类信息。 下面我们继续回到createExtension方法

获取到class对象后,就可以创建实例对象了,下面就是对实例对象进行属性注入和,增强。这两块内容后面会详细说明,至此,通过SPI机制获取扩展类的整个过程我们就已经分析完毕。
dubbo的属性注入源码解析
上面我们已经知道了这个方法,我们继续跟进去

主要通过set方法去判断是否需要注入,然后从SPI和Spirng容器中去获取对应的实例。大家有兴趣可以直接跟进去看,Spi就是获取这个SPI接口的自适应类,容器就是通过类型和名称获取相应的bean。
dubbo中AOP的源码分析
在上面的createExtension方法中,我们也看到了包装目标类,增强扩展类的入口:

这里我们看到了,这个增强类中的扩展类引用就通过上面的方法,进行属性注入,把我们的增强类进行包装。这个包装的层次是跟配置文件配置顺序有关,最后的wapper在最外层。然后一层一层进行包装。
dubbo中Compile机制的源码分析
dubbo中的动态编译器有两种,一种是javassitCompile,一种是JDKCompile,dubbo默认使用的是javassit。 我们先来看下使用javassit的一个过程,再进入代码。
- 首先先生成Adaptive类,类名:SPI接口名$Adaptive
- 然后获取到编译器的自适应类AdaptiveComlile
- 通过自适应类获取到默认的编译器,JavassitCompiler,并调用compiler()方法
- 首先获取到类名,然后尝试加载其class到内存,这时第一次会失败,然后会捕获异常,再通过javassit进行编译
这里我们通过获取Protocal的Adaptive类进行解析: 首先进入ExtensionLoader的getAdaptiveExtension方法
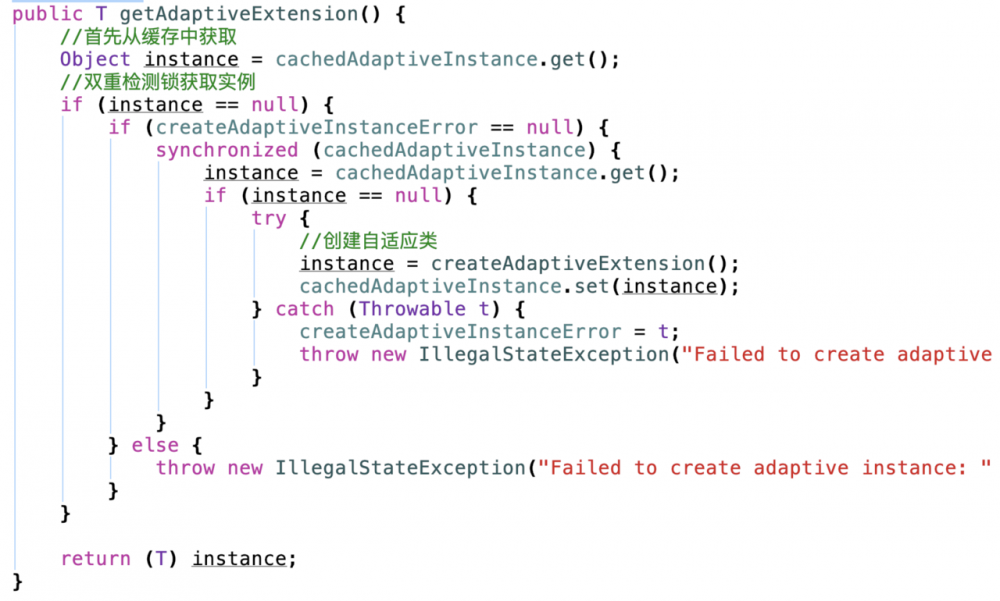
首先也是先通过缓存区获取,然后再通过双重检测锁去创建自适应类,接着进入到createAdaptiveExtension方法

这里的属性注入我们就不看了,直接进到getAdaptiveExtensionClass方法

这个getExtensionClasses方法上面也说过了,继续往下,进入createAdaptiveExtensionClass方法

这里就是生成代码,上面有生成code的一个模板,然后获取编译器进行编译,继续进入comlile方法。进入AbstractCompiler的compiler方法。
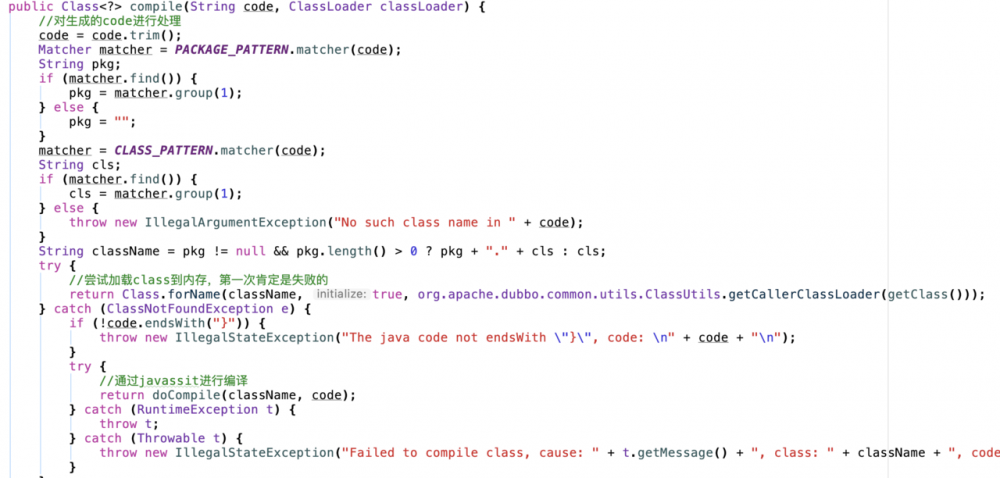
首先对code进行处理,然后尝试加载到内存,第一次肯定是失败的,然后在异常中调用JavassitCompile的doCompile方法进行真正的编译。
至此dubbo内核大部分的源码分析,我们就都跟了一遍了,dubbo就是通过这套内核机制,实现了高扩展的一个能力。
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

