MyBatis 笔记
前言
是什么?为什么要用?
MyBatis 是支持定制化 SQL、存储过程以及高级映射的优秀的持久层框架。MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集。
MyBatis可以使用简单的 XML 或注解用于配置和原始映射,将接口和 Java 的 POJO(Plain Old Java Objects,普通的Java对象)映射成数据库中的记录。
JDBC– SQL 夹在 Java 代码块里,耦合度高导致硬编码内伤。 – 维护不易且实际开发需求中sql是有变化,频繁修改的情况多见。
// 大学的代码
public List<CompetitionInfo> ContestSearchByState(int state) {
JdbcUnit jdbcUnit = JdbcUnit.getInstance();
Connection con = jdbcUnit.createConn(); // 连接数据库
String sql = "Select b.CompetitionName,a.StartTime,a.EndTime,a.ContestState,a.ContestObject,a.ContestexamType " +"from competition b,contest a where a.CompetitionId = b.CompetitionId and " +"a.ContestState=" + state + " GROUP BY b.CompetitionName";
System.out.println("List<CompetitionInfo> ContestSearchByState(int state) 大赛首页根据赛事状态查找赛事列表: " + sql);
List<CompetitionInfo> competitionInfos = new ArrayList<CompetitionInfo>();
CompetitionInfo competitionInfo = null;
PreparedStatement ps = jdbcUnit.prepare(con, sql);
try {
ResultSet rs = ps.executeQuery(sql);
while (rs.next()) {
String CompetitionName=rs.getString(1);
String StartTime=rs.getString(2);
String EndTime=rs.getString(3);
int ContestState=rs.getInt(4);
int ContestObject=rs.getInt(5);
String ContestexamType=rs.getString(6);
competitionInfo=new CompetitionInfo(CompetitionName, StartTime, EndTime,ContestState,ContestObject,ContestexamType);
competitionInfos.add(competitionInfo);
}
con.close();
ps.close();
} catch (SQLException e) {
e.printStackTrace();
}
return competitionInfos;
}
复制代码
Hibernate 和 JPA– 长难复杂 SQL,对于 Hibernate 而言处理也不容易。 – 内部自动生产的 SQL,不容易做特殊优化。 – 基于全映射的全自动框架,大量字段的POJO进行部分映射时比较困难。导致数据库性能下降。
// webapi
public interface TransRecordService {
TransRecord getTransRecord(String enterpriseNum, String fgTradeNo);
// ....
List<TransRecord> findForActiveQuery(String enterpriseNum, String period);
boolean updateState(TransRecord transRecord, WebAPIPayStateEnum webAPIPayStateEnum);
boolean updateForQuery(String transRecordId, String state, String bankOrder, Date cycleDate);
// ....
boolean updateChannelType(String enterpriseNum, String fgTradeNo, String channelType);
void updateBankOrderNo(String enterpriseNum, String fgOrderNo, String bankOrderNo);
void updateCircPaymentNo(String enterpriseNum, String fgOrderNo, String circPaymentNo);
// ....
}
复制代码
五分钟入门
- 引入 jar
<!-- Mybatis 非常轻量,核心只有一个包 -->
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.4</version>
</dependency>
<!-- 对应的数据库连接包 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.48</version>
</dependency>
<dependency>
<groupId>com.oracle</groupId>
<artifactId>ojdbc6</artifactId>
<version>11.2.0.4.0</version>
</dependency>
<!-- 如果和 Spring 结合还需要适配包 -->
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis-spring</artifactId>
<version>2.0.3</version>
</dependency>
复制代码
- 新建环境:mysql、oracle 表结构
- 创建测试方法
/**
* 1、创建 mybatis 配置文件
* 2、得到配置文件流
* 3、创建会话工厂,配置文件流
* 4、通过工厂得到 SqlSession
* 5、通过 SqlSession 操作数据库
* 6、释放资源
*/
@Test
public void test1() throws Exception {
String resource = "simple-mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
SqlSession sqlSession = sqlSessionFactory.openSession();
// 第一个参数:映射文件中statement的id,等于=namespace+"."+statement的id
// 第二个参数:指定和映射文件中所匹配的parameterType类型的参数
// sqlSession.selectOne 结果 是与映射文件中所匹配的 resultType 类型的对象
QueryOrgInfoReq orgInfoReq = QueryOrgInfoReq.builder().id(2).build();
OrgInfoPo po = sqlSession.selectOne("com.ariclee.mybatis.org.mapper.OrgInfoMapper.getBy", orgInfoReq);
System.out.println(po);
sqlSession.close();
}
复制代码
全局配置文件
properties
在 mabatis 中引入 .properties 文件
<properties resource="external.properties">
<!--<property name="username" value="dev_user"/>-->
<!--<property name="password" value="F2Fa3!33TYyg"/>-->
</properties>
复制代码
setting
- mapUnderscoreToCamelCase:是否开启驼峰命名映射
等后面用到时,再讲解。
typeAliases
类型别名,重命名为简短字符,降低冗余的全限定类名书写。 不区分大小写 。 常见的类型别名需要大概记一下:简单类型,首字母加下划线。包装类型,首字母小写。
使用 package 子标签可以批量指定别名
<typeAliases>
<package name="com.ariclee.mybatis.mapper"/>
</typeAliases>
复制代码
一般不用自定义别名,缩写比较难找。
typeHandlers:
类型处理器,略过。
plugins
插件,略过。
environments:
配置不同的环境,使用 default 属性静态指定需要用到哪个环境。如:
<environments default="dev_oracle">
<environment id="dev_mysql">
<transactionManager type="jdbc"/>
<dataSource type="POOLED">
<property name="driver" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://172.18.12.64:3306/spms?useSSL=false"/>
<property name="username" value="rhf"/>
<property name="password" value="rhf"/>
</dataSource>
</environment>
<environment id="dev_oracle">
<transactionManager type="jdbc"/>
<dataSource type="POOLED">
<property name="driver" value="oracle.jdbc.driver.OracleDriver"/>
<property name="url" value="jdbc:oracle:thin:@10.60.45.207:1521:dbtest"/>
<property name="username" value="rhf"/>
<property name="password" value="rhf"/>
</dataSource>
</environment>
</environments>
复制代码
其中每个 environment 中子标签 transactionManager、dataSource 是必填项。
-
transactionManager:事务管理器 type 的可选项有 JDBC、MANAGED。
-
dataSource: type 可选项有 UNPOOLED|POOLED|JNDI。也可以自定义数据源类型:实现 DataSourceFactory 接口,返回自定义的 DataSource
这一块了解即可。一般使用 Spring 时自带的管理器来覆盖前面的配置。
databaseIdProvider
数据库厂商标识。数据厂商标识可能比较繁琐,property 标签可以为厂商标识起别名。
<databaseIdProvider type="DB_VENDOR">
<property name="SQL Server" value="sqlserver"/>
<property name="DB2" value="db2" />
<property name="Oracle" value="oracle" />
<property name="MySQL" value="mysql" />
</databaseIdProvider>
复制代码
起好别名以后,就可以在 mapper 文件中引用,如下:
<select id="getBy" databaseId="mysql"
resultType="com.ariclee.mybatis.org.OrgInfoPo">
SELECT * FROM org_info_test where 1=1 and id=#{id}
</select>
<select id="getBy" databaseId="oracle"
resultType="com.ariclee.mybatis.org.OrgInfoPo">
SELECT * FROM org_info_test where 1=1 and id=#{id}
</select>
复制代码
当前 geyBy 方法在不同的数据库下有不同的实现。当连接的是 Oracle 数据库时,mybatis 会自动选择对应 SQL 实现。
mapper
把写好的 SQL 映射文件,注册进 Mybatis。
<mappers>
<mapper resource="./mapper/OrgInfoMapper.xml"/>
<mapper class="com.ariclee.mybatis.org.mapper.OrgInfoAnnotationMapper"/>
</mappers>
复制代码
当使用第一种 resource 形式注册时,mybatis 对 mapper 接口与 xml 文件的路径没有强制性要求,因为只要能定位映射文件,在映射文件中便可找到相对应的 mapper 接口。
但使用第二种 class 方式注册时,就有以下几点需要注意:
- 有 xml 文件,文件名必须和接口同名,并且放在同一目录下
- 没有 xml 文件,使用注解方式实现
当 sql 映射文件存在多个时,可以使用 package 子标签,批量注册。
由于 name 属性中填的是类路径,当使用注解时映射语句与接口放在一起此时不会有问题。
而使用 xml 文件时,可能会存在 xml 文件与接口不在同一文件夹的情况。问题与上文使用 class 注册时,找不到映射文件类似, 为避免此情况,需要将 xml 文件与接口 .java 文件放在一起。(也可以放在 resources 文件下,建立对应 mapper 文件)
<mappers>
<package name="com.ariclee.mybatis.org.mapper"/>
</mappers>
复制代码
映射文件
映射器的 XML 文件,是 mybatis 里面最重要的部分。xml 文件中包含以下几个顶级元素(没有顺序):
cache cache-ref resultMap sql insert update delete select
参数处理
#{}
单个参数时,mybatis 不会做特殊处理,直接使用 #{} 取出,无论 {} 中填的是什么值。
**特殊:**如果参数是 List、Array、Set 等集合类型,mybatis 也会把其封装在 Map 中。 如果是 Collection 则 key 为 collect,List、Set 则会被更精确地封装为 list、set。如果是数组,则对应的 key 为 array。
多个参数时,mybatis 会将多个参数封装在 Map 中,key 为 param1...paramN,#{} 其实就是从 Map 中取值,大概如下:
<!-- OrgInfoPo getBy2(Integer id, String orgCode) -->
<select id="getBy2"
resultType="com.ariclee.mybatis.org.OrgInfoPo">
SELECT * FROM org_info_test where 1=1 and id=#{param1} and org_code=#{param2}
</select>
复制代码
但此种方法,可读性过差。此时就可以使用 @Param("") 注解来重命名 Map 的 key,于是就可以在 xml 中直接访问指定 key 的参数值,如下:
<!-- OrgInfoPo getBy2(@Param("id")Integer id, @Param("orgCode")String orgCode) -->
<select id="getBy2"
resultType="com.ariclee.mybatis.org.OrgInfoPo">
SELECT * FROM org_info_test where 1=1 and id=#{id} and org_code=#{orgCode}
</select>
复制代码
如果传入的参数是一个对象(VO、DTO、PO等),在映射文件中,则可以直接使用 #{属性名} 来访问(也是推荐做法);如果该对象是一个 Map,直接使用 #{MapKey} ,也可以访问。
下面是几个传参访问实例:
OrgInfoPo getBy2(@Param("id")Integer id, String orgCode)
OrgInfoPo getBy2(Integer id, OrgInfoPo po)
最佳实践:使用 @Param 注解自定义 param key
其他的属性:javaType、jdbcType、mode(存储过程)、numericScale、resultMap、typeHandler(处理枚举)、jdbcTypeName、expression
尽管上面这些选项很强大,但大多时候,你只须简单指定属性名,顶多要为可能为空的列指定 jdbcType,其他的事情交给 MyBatis 自己去推断就行了。
对于数值类型,还可以设置 numericScale 指定小数点后保留的位数。
#{height,javaType=double,jdbcType=NUMERIC,numericScale=2}
复制代码
对于 Oracle 环境下无法识别 null 值处理
#{orgName, jdbcType=VARCHAR}
<!-- setting -->
<settings>
<setting name="jdbcTypeForNull" value="NULL"/>
</settings>
复制代码
最佳实践:jdbcType 通常在一些可能为空的列名中指定
${}
与 #{} 的区别:
#{}
${}
<!-- 配置 -->
<select id="getBy3"
resultType="com.ariclee.mybatis.org.OrgInfoPo">
SELECT * FROM org_info_test where 1=1 and id=${id} and org_code=#{orgCode}
</select>
<!-- 最终执行的 SQL -->
SELECT * FROM org_info_test where 1=1 and id=2 and org_code=?
复制代码
应用场景:
- 动态表名:spms 商户子表例子、按年份分表等
- 排序:order by 语句后面的字段名
<insert> 标签
- 增删改返回受影响行数 Integer、Long、Boolean(验证 MYSQL 和 Oracle 影响行数区别)
- 新增返回自增主键,MYSQL、Oracle 区别
- 自动提交事务问题
- oracle 创建序列
<select> 标签
属性
| 属性 | 描述 |
|---|---|
| id | 在命名空间中唯一的标识符,可以被用来引用这条语句。 不能存在同名方法,即使方法的参数不一样 |
| parameterType | 将会传入这条语句的参数的类全限定名或别名。 可选 因为 MyBatis 可以通过类型处理器(TypeHandler)推断出具体传入语句的参数,默认值为未设置(unset)。 |
| resultType | 期望从这条语句中返回结果的类全限定名或别名。注意, 如果返回的是集合,那应该设置为集合包含的类型,而不是集合本身的类型。 resultType 和 resultMap 之间只能同时使用一个。 |
| resultMap | 对外部 resultMap 的命名引用。结果映射是 MyBatis 最强大的特性,如果你对其理解透彻,许多复杂的映射问题都能迎刃而解。 resultType 和 resultMap 之间只能同时使用一个。 |
| flushCache | 将其设置为 true 后,只要语句被调用,都会导致本地缓存和二级缓存被清空,默认值:false。 |
| useCache | 将其设置为 true 后,将会导致本条语句的结果被二级缓存缓存起来,默认值:对 select 元素为 true。 |
| timeout | 这个设置是在抛出异常之前,驱动程序等待数据库返回请求结果的秒数。默认值为未设置(unset)(依赖数据库驱动)。 |
| fetchSize | 这是一个给驱动的建议值,尝试让驱动程序每次批量返回的结果行数等于这个设置值。 默认值为未设置(unset)(依赖驱动)。 |
| statementType | 可选 STATEMENT,PREPARED 或 CALLABLE。这会让 MyBatis 分别使用 Statement,PreparedStatement 或 CallableStatement,默认值:PREPARED。 |
| resultSetType | FORWARD_ONLY,SCROLL_SENSITIVE, SCROLL_INSENSITIVE 或 DEFAULT(等价于 unset) 中的一个,默认值为 unset (依赖数据库驱动)。 |
| databaseId | 如果配置了数据库厂商标识(databaseIdProvider),MyBatis 会加载所有不带 databaseId 或匹配当前 databaseId 的语句;如果带和不带的语句都有,则不带的会被忽略。 |
| resultOrdered | 这个设置仅针对嵌套结果 select 语句:如果为 true,将会假设包含了嵌套结果集或是分组,当返回一个主结果行时,就不会产生对前面结果集的引用。 这就使得在获取嵌套结果集的时候不至于内存不够用。默认值:false。 |
| resultSets | 这个设置仅适用于多结果集的情况。它将列出语句执行后返回的结果集并赋予每个结果集一个名称,多个名称之间以逗号分隔。 |
resultType、resultMap
resultType:自动封装;resultMap:自定义 javaBean 封装规则,高级结果集映射 - resultType 比较简单,如果列名和类字段名能对应上或者是符合自动映射规则,则使用 resultType。若对不上,或者需要使用更加强大的映射功能选择 resultMap - 查询语句两者必须指定一个,但不能同时指定 log Caused by: org.apache.ibatis.executor.ExecutorException: A query was run and no Result Maps were found for the Mapped Statement 'com.ariclee.mybatis.org.mapper.OrgInfoMapper.getBy3'. It's likely that neither a Result Type nor a Result Map was specified.
- 返回一个 Map:key 为列名,value 为值
<select id="getBy4" resultType="map">
SELECT * FROM org_info_test where 1=1 and id=#{id}
</select>
复制代码
- 返回一个 Map:Map<Inetger, Bean>(MapKey)
@MapKey("id")
Map<String, OrgInfoPo> getBy5(String orgCode);
<select id="getBy5" resultType="com.ariclee.mybatis.org.OrgInfoPo">
SELECT * FROM org_info_test where 1=1 and org_code like #{orgCode}
</select>
复制代码
实体之间的关联查询:一对一
假设一个组织下面只挂一个商户
public class OrgWithMchInfoPo {
private MchInfoPO mch;
}
复制代码
映射文件 resultMap 写法
<!-- 对象访问符实现 -->
<resultMap id="OrgInfoPoWithMchInfoMap1" type="com.ariclee.mybatis.org.OrgWithMchInfoPo">
<id property="id" column="id"/>
<result column="mit_id" property="mch.id"/>
<result column="mit_code" property="mch.code"/>
<result column="mit_name" property="mch.name"/>
</resultMap>
<!-- association 标签实现 -->
<resultMap id="OrgInfoPoWithMchInfoMap1" type="com.ariclee.mybatis.org.OrgWithMchInfoPo">
<id property="id" column="id"/>
<association property="mch" javaType="com.ariclee.mybatis.mch.MchInfoPO">
<result column="mit_id" property="id"/>
<result column="mit_code" property="code"/>
<result column="mit_name" property="name"/>
</association>
</resultMap>
<select id="getBy6" resultMap="OrgInfoPoWithMchInfoMap1">
SELECT
oit.id as id,
oit.org_code as org_code,
oit.org_name as org_name,
mit.id as mit_id,
mit.code as mit_code,
mit.name as mit_name
FROM org_info_test oit left join mch_info_test mit on oit.id=mit.org_id
where 1=1 and oit.id=#{id}
</select>
复制代码
<association> 实现分步查询+延时查询
<resultMap id="OrgInfoPoWithMchInfoMap1_1" type="com.ariclee.mybatis.org.OrgWithMchInfoPo">
<id property="id" column="id"/>
<association property="mch"
javaType="com.ariclee.mybatis.mch.MchInfoPO"
select="getMchInfoByOrgId" column="id" fetchType="lazy">
</association>
</resultMap>
<!-- 主方法 -->
<select id="getBy6_1" resultMap="OrgInfoPoWithMchInfoMap1_1">
SELECT *
FROM org_info_test
where 1=1 and id=#{id}
</select>
<!-- 根据组织 id 查询商户 -->
<select id="getMchInfoByOrgId" resultType="com.ariclee.mybatis.mch.MchInfoPO">
SELECT *
FROM mch_info_test
where 1=1 and org_id=#{id}
</select>
复制代码
当书写完分步查询 SQL 映射文件后,需要使用全局配置 lazyLoadingEnabled 开关或者使用 association fetchType 属性来指定。官网解释如下:
lazyLoadingEnabled:延迟加载的全局开关。当开启时,所有关联对象都会延迟加载。 特定关联关系中可通过设置 fetchType 属性来覆盖该项的开关状态。
association、collection 标签中传多列值,column="{key1=v1, key2=v2}"
<association property="mch"
javaType="com.ariclee.mybatis.mch.MchInfoPO"
select="getMchInfoByOrgId" column="{orgId=id,orgId=id}" fetchType="lazy">
</association>
复制代码
实体之间的关联查询:一对多
假设一个组织下面挂了多个商户
public class OrgWithMchInfoPo2 {
private List<MchInfoPO> mchs;
}
复制代码
连表一次查询
<resultMap id="OrgInfoPoWithMchInfoMap2" type="com.ariclee.mybatis.org.OrgWithMchInfoPo2">
<id property="id" column="id"/>
<collection property="mchs" ofType="com.ariclee.mybatis.mch.MchInfoPO">
<id column="mit_id" property="id"/>
<result column="mit_code" property="code"/>
<result column="mit_name" property="name"/>
</collection>
</resultMap>
复制代码
同样的, collection 也支持分段查询和延时加载 ,映射文件 resultMap 写法
<resultMap id="OrgInfoPoWithMchInfoMap2" type="com.ariclee.mybatis.org.OrgWithMchInfoPo2">
<id property="id" column="id"/>
<collection property="mchs" select="getMchInfosByOrgId" column="id" />
</resultMap>
复制代码
使用 channel 和 channel_param 的例子
discriminator 鉴别器
判断某列的值,改变封装行为。例子如下:当 id 为 1 时,查出关联的商户信息;id 为 2 时,对 orgName 字段赋值。
<resultMap id="OrgInfoPoWithMchInfoMap3" type="com.ariclee.mybatis.org.OrgWithMchInfoPo">
<id property="id" column="id"/>
<discriminator javaType="integer" column="id">
<case value="1">
<association property="mch"
javaType="com.ariclee.mybatis.mch.MchInfoPO"
select="getMchInfoByOrgId" column="id" >
</association>
</case>
<case value="2">
<result property="orgName" column="org_name"/>
</case>
</discriminator>
</resultMap>
<select id="getBy8" resultMap="OrgInfoPoWithMchInfoMap3">
SELECT * FROM org_info_test where 1=1 and id=#{id}
</select>
复制代码
使用 mch_info 和 xxx_mch_info 的例子
<update> 标签
<update id="update1">
update org_info_test set org_name = #{orgName} where id=#{id}
</update>
复制代码
<delete> 标签
<!-- 单笔删除 -->
<delete id="delete1">
delete from org_info_test where id = #{id}
</delete>
<!-- 批量删除 -->
<delete id="batchDelete1">
delete from org_info_test where id in
<foreach collection="ids" separator="," item="id" open="(" close=")">
#{id}
</foreach>
</delete>
复制代码
动态 SQL
如果你使用过 JDBC 或其它类似的框架,你应该能理解根据不同条件拼接 SQL 语句有多痛苦,例如拼接时要确保不能忘记添加必要的空格,还要注意去掉列表最后一个列名的逗号。
动态 SQL 包含的标签: if、choose (when, otherwise)、trim (where, set)、foreach
OGNL 表达式
官方文档: commons.apache.org/proper/comm…
常用语法:
- e1 or e2
- e1 and e2
- e1 == e2,e1 eq e2
- e1 != e2,e1 neq e2
- e1 lt e2:小于
- e1 lte e2:小于等于,其他 gt(大于),gte(大于等于)
- e1 in e2
- e1 not in e2
- e1 + e2,e1 * e2,e1/e2,e1 - e2,e1%e2
- !e,not e:非,求反
- e.method(args):调用对象方法
- e.property:对象属性值
- e1[ e2 ]:按索引取值,List,数组和Map
- @class@method(args):调用类的静态方法
- @class@field:调用类的静态字段值
使用场景:
- 动态 SQL 表达式中:
<if test="">、<bind value=""> -
${}参数中,在#{}中不适用
注意 XML 文档中的转义字符 " & 等
<if> 标签
条件后面 and 问题解决方案:
<where>
在条件字符串前面加上 where 字符串,并且覆盖后面的 and 字符
<trim prefix="where" prefixOverrides="" suffix="" suffixOverrides="and">
<if test="orgCodeLike!=''">
org_code like #{orgCodeLike} and
</if>
</trim>
复制代码
<choose> 标签
当满足一个条件时,会立即 break,不会再执行下面的操作。当同时满足 orgCodeLike!='' 和 id != null 时,id 条件不会被拼接。
<select id="getBy12" resultType="com.ariclee.mybatis.org.OrgWithMchInfoPo">
SELECT * FROM org_info_test
<where>
<choose>
<when test="orgCodeLike!=''">
and org_code like #{orgCodeLike}
</when>
<when test="id != null">
id=#{id}
</when>
</choose>
</where>
</select>
复制代码
<set> 标签
where 用来封装查询条件, set 来封装更新条件。 本质为了去掉更新字段后面多出的逗号问题
<update id="update3">
update org_info_test
<set>
<if test="orgCode != ''">
org_code=#{orgCode},
</if>
<if test="orgName != ''">
org_name=#{orgName},
</if>
<if test="createTime != null">
create_time=#{createTime},
</if>
</set>
where id=#{id}
</update>
复制代码
同样也可以使用 <trim> 来达到相同的目的
<update id="update3">
update org_info_test
<trim prefix="set" prefixOverrides="" suffix="" suffixOverrides=",">
<if test="orgCode != ''">
org_code=#{orgCode},
</if>
<if test="orgName != ''">
org_name=#{orgName},
</if>
<if test="createTime != null">
create_time=#{createTime},
</if>
</trim>
where id=#{id}
</update>
复制代码
foreach 标签
- 批量删除
<delete id="batchDelete1">
delete from org_info_test where id in
<foreach collection="ids" separator="," item="id" open="(" close=")">
#{id}
</foreach>
</delete>
复制代码
- MYSQL 下批量新增的两种方式
<insert id="batchAdd1">
<!-- 方式一 -->
insert into org_info_test(org_code, org_name, create_time) values-->
<foreach collection="pos" item="po" separator=",">
(#{po.orgCode}, #{po.orgName}, #{po.createTime})
</foreach>
<!-- 需要手动开启,不仅可以批量保存,还可以批量更新 -->
<!-- mysql allowmultiqueries -->
<foreach collection="pos" item="po" separator=";">
insert into org_info_test(org_code, org_name, create_time) values
(#{po.orgCode}, #{po.orgName}, #{po.createTime})
</foreach>
</insert>
复制代码
- Oracle 下批量新增两种方式:begin end+临时表
<insert id="batchAdd2">
begin
<foreach collection="pos" item="po">
insert into org_info_test (id, org_code, org_name, create_time)
values(t_org_info_test_seq.nextval, #{po.orgCode}, #{po.orgName}, #{po.createTime});
</foreach>
end;
</insert>
复制代码
第二种临时比较复杂,省略;
两个内置参数: _paramter 、 _databaseId
_paramter:封装好的参数 Map。增加为 null 判断,提高鲁棒性
<select id="getBy13" resultType="com.ariclee.mybatis.org.OrgWithMchInfoPo">
SELECT * FROM org_info_test where 1=1
<if test="_parameter != null">
and id=#{id}
</if>
</select>
复制代码
bind 标签
<select id="getBy14" resultType="com.ariclee.mybatis.org.OrgWithMchInfoPo">
<bind name="_orgCodeLike" value="'%'+orgCodeLike+'%'" />
SELECT * FROM org_info_test where 1=1
and org_code like #{_orgCodeLike}
</select>
复制代码
sql 标签
抽取可重用的 SQL 片段。使用 include 标签引用。
<sql id="common_condition">
1=1
<if test="appCodeList != null and appCodeList.size()>0">
and application_code in
<foreach collection="appCodeList" open="(" separator="," close=")" item="appCodeItem">#{appCodeItem}
</foreach>
</if>
</sql>
<select id="queryOverviewPageData" resultMap="OverviewPageMap">
select
sum(cost) as cost
from daily_trans_report
where <include refid="common_condition"/>
</select>
复制代码
缓存机制
MyBatis 包含一个非常强大的查询缓存特性,且非常方便地配置和定制。缓存可以极大的提升查询效率。MyBatis 框架中默认定义了两级缓存:一级缓存和二级缓存。
- 默认情况下,只有一级缓存(SqlSession 级别的缓存,也称为本地缓存)开启。
- 二级缓存需要手动开启和配置,基于 namespace 级别的缓存。
- 为了提高扩展性。MyBatis 定义了缓存接口 Cache。可以通过实现 Cache 接口来自定义二级缓存。
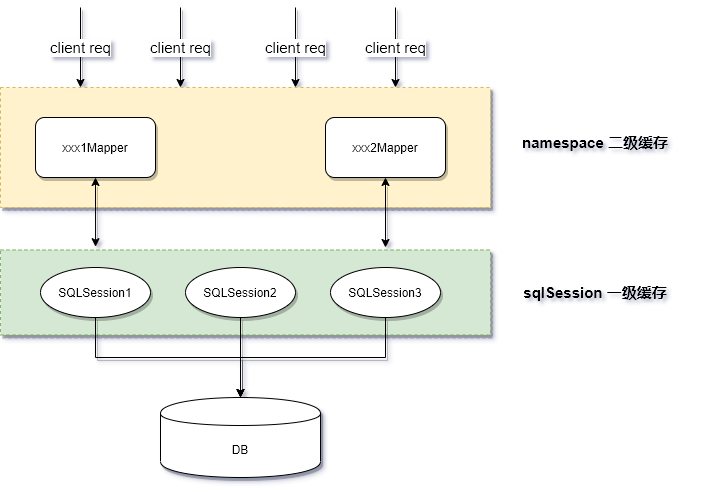
一级缓存
一级缓存(local cache),即本地缓存,作用域默认为 sqlSession 。**当 Session flush 或 close 后, 该 Session 中的所有 Cache 将被清空。**可以调用 clearCache() ,来清空本地缓存。当全局配置 localCacheScope 值为 STATEMENT 时,相当于禁用掉了一级缓存。
一级缓存失效的四种情况:
- 不同的 SqlSession 对应不同的一级缓存
- 同一个 SqlSession 但是查询条件不同
- 同一个 SqlSession 两次查询期间执行了任何一次增删改操作
- 同一个 SqlSession 两次查询期间手动清空了缓存
二级缓存
二级缓存(second level cache),全局作用域缓存 namespace 级别。
- 二级缓存默认不开启,需要手动配置
- MyBatis 提供二级缓存的接口以及实现,要求 POJO 实现 Serializable 接口
- 二级缓存在 SqlSession 关闭或提交之后才会生效
cache 标签的属性
<cache eviction="FIFO" flushInterval="60000" size="512" readOnly="true"/> 复制代码
这个更高级的配置创建了一个 FIFO 缓存,每隔 60 秒刷新,最多可以存储结果对象或列表的 512 个引用,而且返回的对象被认为是只读的,因此对它们进行修改可能会在不同线程中的调用者产生冲突。可用的清除策略有:
-
LRU – 最近最少使用:移除最长时间不被使用的对象。(默认)
-
FIFO – 先进先出:按对象进入缓存的顺序来移除它们。
-
SOFT – 软引用:基于垃圾回收器状态和软引用规则移除对象。
-
WEAK – 弱引用:更积极地基于垃圾收集器状态和弱引用规则移除对象。
-
flushInterval(刷新间隔)属性:可以被设置为任意的正整数,设置的值应该是一个以毫秒为单位的合理时间量。 默认情况是不设置,也就是没有刷新间隔,缓存仅仅会在调用语句时刷新。
-
size(引用数目)属性:可以被设置为任意正整数,要注意欲缓存对象的大小和运行环境中可用的内存资源。默认值是 1024。
-
readOnly(只读)属性:可以被设置为 true 或 false。只读的缓存会给所有调用者返回缓存对象的相同实例。 因此这些对象不能被修改。这就提供了可观的性能提升。而可读写的缓存会(通过序列化)返回缓存对象的拷贝。 速度上会慢一些,但是更安全,因此默认值是 false。
开启二级缓存步骤:
<cache />
与其他标签中缓存配置的相互作用:
-
select标签中useCache打开和关闭的是二级缓存 -
insert、update、delete标签中flushCache默认是打开的,且对一级、二级缓存都有影响 -
sqlSession.clearCache()该方法只会影响当前一级缓存 - 全局配置中的
localCacheScope默认值为 SESSION(一级缓存开启),配置为 STATEMENT,相当于禁用掉了一级缓存
Spring 整合
官方文档: mybatis.org/spring/gett…
- 引入适配包
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis-spring</artifactId>
<version>2.0.3</version>
</dependency>
复制代码
- spring 常规配置
<!-- 数据源配置 -->
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" >
<property name="url" value="jdbc:mysql://172.18.12.64:3306/spms?useSSL=false"/>
<property name="username" value="rhf"/>
<property name="password" value="rhf"/>
</bean>
<!-- 事务管理器配置 -->
<bean id="txManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource"/>
</bean>
<!-- 注解 -->
<tx:annotation-driven transaction-manager="txManager"/>
复制代码
- Mybatis 适配配置
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean">
<property name="dataSource" ref="dataSource"/>
<property name="configLocation" value="classpath:mybatis-config-with-spring.xml"/>
<property name="mapperLocations" value="classpath:mapper/*.xml"/>
</bean>
<!-- 推荐方式 -->
<mybatis:scan factory-ref="sqlSessionFactory" base-package="com.ariclee.mybatis.org.mapper"/>
<!-- 老版本方式 -->
<!--<bean class="org.mybatis.spring.mapper.MapperScannerConfigurer">-->
<!--<property name="basePackage" value="com.ariclee.mybatis.org.mapper"/>-->
<!--<property name="sqlSessionFactoryBeanName" value="sqlSessionFactory"/>-->
<!--</bean>-->
复制代码
扩展
分页插件(PageHelper)
官方文档: github.com/pagehelper/…
- 引入 jar
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper</artifactId>
<version>5.1.5</version>
</dependency>
复制代码
- 添加 mybatis 配置
<plugins>
<plugin interceptor="com.github.pagehelper.PageInterceptor"/>
</plugins>
复制代码
- 使用
// 使用返回值获取分页信息
Page<Object> page = PageHelper.startPage(1, 3);
List<OrgWithMchInfoPo> res1 = mapper.getBy16();
res1.forEach(System.out::println);
System.out.println("总页数:" + page.getPages());
System.out.println("总条数:" + page.getTotal());
// 使用 PageInfo 包装后获取分页信息
PageHelper.startPage(1, 3);
List<OrgWithMchInfoPo> res1 = mapper.getBy16();
PageInfo<OrgWithMchInfoPo> pageInfo = new PageInfo<>(res1);
res1.forEach(System.out::println);
System.out.println("总页数:" + pageInfo.getPages());
System.out.println("总条数:" + pageInfo.getTotal());
复制代码
自定义类型处理
- 实现
BaseTypeHandler接口
下面是一个通用的枚举处理器
@MappedTypes(value = {
SceneEnum.class
})
public class EnumValueTypeHandler<E extends LabelAndValue> extends BaseTypeHandler<E> {
private Class<E> type;
private final E[] enums;
public EnumValueTypeHandler(Class<E> type) {
if (type == null) {
throw new IllegalArgumentException("Type argument cannot be null");
}
this.type = type;
this.enums = type.getEnumConstants();
if (this.enums == null) {
throw new IllegalArgumentException(type.getSimpleName() + " does not represent an enum type.");
}
}
@Override
public void setNonNullParameter(PreparedStatement ps, int i, E parameter, JdbcType jdbcType) throws SQLException {
ps.setString(i, parameter.getValue());
}
@Override
public E getNullableResult(ResultSet rs, String columnName) throws SQLException {
String value = rs.getString(columnName);
if (rs.wasNull()) {
return null;
}
else {
try {
return getEnumByValue(value);
} catch (Exception ex) {
throw new IllegalArgumentException(
"Cannot convert " + value + " to " + type.getSimpleName() + " by ordinal value.", ex);
}
}
}
protected E getEnumByValue(String value) {
for (E e : enums) {
if (e.getValue().equals(value)) {
return e;
}
}
return null;
}
@Override
public E getNullableResult(ResultSet rs, int columnIndex) throws SQLException {
String i = rs.getString(columnIndex);
if (rs.wasNull()) {
return null;
} else {
try {
return getEnumByValue(i);
} catch (Exception ex) {
throw new IllegalArgumentException(
"Cannot convert " + i + " to " + type.getSimpleName() + " by ordinal value.", ex);
}
}
}
@Override
public E getNullableResult(CallableStatement cs, int columnIndex) throws SQLException {
String i = cs.getString(columnIndex);
if (cs.wasNull()) {
return null;
} else {
try {
return getEnumByValue(i);
} catch (Exception ex) {
throw new IllegalArgumentException(
"Cannot convert " + i + " to " + type.getSimpleName() + " by ordinal value.", ex);
}
}
}
}
复制代码
- 全局配置文件中指定类型处理器,或者在单个方法中指定类型处理器
<!-- 全局指定 -->
<typeHandlers>
<typeHandler javaType="com.ariclee.mybatis.org.SceneEnum" handler="com.ariclee.mybatis.org.EnumValueTypeHandler"/>
</typeHandlers>
<!-- 在使用时指定 -->
<resultMap id="OrgInfoMap" type="com.ariclee.mybatis.org.OrgInfoPo">
<result column="scene" property="scene" javaType="com.ariclee.mybatis.org.SceneEnum" typeHandler="com.ariclee.mybatis.org.EnumValueTypeHandler"/>
</resultMap>
<insert id="insertWithEnum">
insert into org_info_test (org_code, org_name, create_time, scene)
values(#{orgCode}, #{orgName}, #{createTime}, #{scene, typeHandler=com.ariclee.mybatis.org.EnumValueTypeHandler});
</insert>
复制代码
正文到此结束
- 本文标签: 删除 java JDBC GitHub constant db2 XML 二级缓存 Oracle 参数 build session 数据 JPA ssl zab 空间 mapper git 组织 final 垃圾回收 安全 http spring 静态方法 API Service tab 实例 executor find 分页 Connection 集合类 UI Enterprise web 缓存 时间 SqlSessionFactory ip list 开发 Collection cat core 目录 equals 管理 Action classpath pagehelper Select cache tar mybatis dataSource 本质 配置 ACE apache ResultSet 需求 SqlSessionFactoryBuilder mina value 一对多 IO 线程 src mysql ArrayList NSA Property 测试 druid App plugin Result Maps SQL Server id map Word update Statement 代码 bean db key 关联查询 一级缓存 数据库 lib 索引 IDE 处理器 定制 stream CTO sqlsession https 插件 provider iBATIS sql
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

