HashMap 多知多用
前言
在面试中我面试包括我参见的一些面试一直比较喜欢问HashMap原理,不是其原理有多深奥,是因为HashMap几乎是面试的必问点,然而还有大部分的人不能清楚的描述。觉得有必要写一篇来记录一下,一来希望可以帮助有需要的人,二来让自己加深印象。在写这篇之前我也是把源码看了又看,博客翻了又翻,生怕描述错误,如果大家有发现错误的地方还望指正,另外大牛勿喷。以下进入正题:
HashMap 是什么?
这是百度百科给的定义:基于 哈希表 的 Map 接口的实现。此实现提供所有可选的映射操作,并允许使用 null 值和 null 键,特别是它不保证该顺序恒久不变。通俗的讲,其实HashMap如何有效的存、取、键值对。
为什么面试喜欢问HashMap?
现在Java开发面试、Android开发面试,大家好像都喜欢问HaspMap的实现原理,我曾经遇到过一个面试,面试就问了一个HaspMap,从头到尾面了接近30分钟,然后我就被淘汰了...。其实好多同事也会问,HashMap有什么可聊的,开发中直接使用就可以了,如果要用到的时候直接去网上一百度不是都有吗?但是面试了很多候选人,就算在面试前告诉他们会问到HashMap,还是有大部分人挂在这,这其中涉及对数据结构的不理解,对策略的不理解。个人感觉深入的问其原理无非是想从一个点开始,逐渐打开你的知识体系,了解你对基础数据结构、策略的掌握程度,由点及面储备知识的广度,从而更能考验候选人的能力。
怎样表示一个键值对?
其实表示键值对非常简单,在Java的知识体系中声明一个类即可,如下:这个类就可以代表键值对,包含两个属性 K 和 V。
static class Node<K,V> {
final K key;
V value;
}
只有一个类还是不够的,根据Java的面向设计规则,需要一个接口来描述一些动作,在Map接口中还提供了一个内部接口 Entry<K , V>,它表示Map中的一个实体,接口中有 getKey() , getValue() 方法。所以在HashMap中上面这类定义为:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
}
下面是Entry接口:
interface Entry<K, V> {
K getKey();
V getValue();
}
K-V键值对在HashMap中是如何存储的?
在Java中,最基础的存储结构就是两种,一种是数组,另一种是引用,这两个存储结构可以构造所有的数据结构,在Java1.8以前采用数据+链表,在1.8以后采用数组+链表+红黑树的方式构成的。HashMap本质上是一种叫做"链表散列"的数据结构,也就是我们通常所说的数组和链表,关于数组和链表的优缺点其实大家已经非常了解了。
- 数组优点:使用方便,查询效率比链表高,内存一般为连续内存。缺点:插入和删除的性能差
- 链表优点:可动态添加删除 大小可变,插入和删除性能高。缺点:只能通过顺次指针访问,查询效率低
- 红黑树的描述请自行参考,至于为什么选用红黑树,网上是这么解释的:
因为Map中桶的元素初始化是链表保存的,其查找性能是O(n),而树结构能将查找性能提升到O(log(n))。当链表长度很小的时候,即使遍历,速度也非常快,但是当链表长度不断变长,肯定会对查询性能有一定的影响,所以才需要转成树。
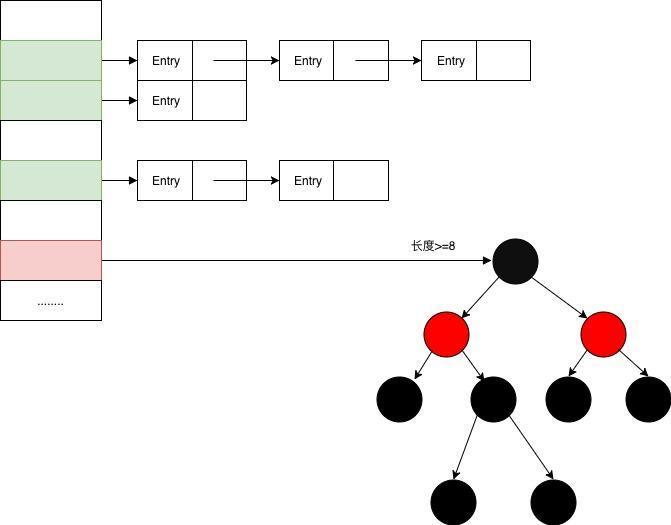
在使用中到底会选用哪种方式来存储呢?查找、插入、删除的场景在实际的开发中都会用到,其实在使用的时候考虑到查找的需求会比较多,因为可以直接用下标定位到数组存储的位置,所以HashMap采用的数组存储的方法。下面截取了一段。可以看到确实是使用了数组进行存储。
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
}
上面说到,以数组的形式来存储key-value对象,那在HashMap中是怎样确定数组索引的位置的呢?
- 第一步:对Key值做Hash运算
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
- 第二步:对
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
/*table就是数组中的索引,如果为null或0就初始化*/
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
/*根据计算的下标,如果有值则直接覆盖,如果没有值则直接插入,n是一个2的幂*/
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
/*到这里说明发生了碰撞,这个时候就会进行碰撞处理*/
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
/*如果节点属于树,说明碰撞程度已经超过8个了,就转为红黑树来处理*/
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
/*如果大于了链表碰撞预设大小,判断是扩容还是专用红黑树了*/
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
/*碰撞的key相等,这时会新老节点替换*/
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
/* 超过了预定的值,这时候就需要扩容了*/
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
当然后边还有插入红黑树的操作,这里不做分析,有兴趣请查看putTreeVal()这个函数。
java中是怎样处理Hash冲突的
下面有一个拓展阅读我觉得讲的特别详细 Hash冲突
总结
HashMap设计的初衷是希望可以存储一组键值对,并且可以快速的查找
- 在快速查找上,HashMap在设计上使用数组实现,利用数组查找索引速度快的优势
- 在数组的存储上,使用了Object的Hash算法,通过Hash算法对Key值进行计算,然后对数组长度进行取&运算,获取数组最终的索引。虽然进行复杂的计算,但还是会有Hash冲突,为了解决Hash冲突,设计者又设计了链表地址法,冲突之后转换为链表存储。那么在数据量比较大或者极端的时候,冲突的链表会越来越大,这个时候设计者为了解决性能问题,在链表大于8的时候把链表转换为红黑树,将o(n)复杂度的提升至o(log n)。


今天不想跑,所以才去跑,这才是长距离跑者的思维方式.
欢迎关注个人公众号 HenryFusu,希望一起成长.
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

