Java构建高效结果缓存方法示例
缓存是现代应用服务器中非常常用的组件。除了第三方缓存以外,我们通常也需要在java中构建内部使用的缓存。那么怎么才能构建一个高效的缓存呢? 本文将会一步步的进行揭秘。
使用HashMap
缓存通常的用法就是构建一个内存中使用的Map,在做一个长时间的操作比如计算之前,先在Map中查询一下计算的结果是否存在,如果不存在的话再执行计算操作。
我们定义了一个代表计算的接口:
public interface Calculator<A, V> {
V calculate(A arg) throws InterruptedException;
}
该接口定义了一个calculate方法,接收一个参数,并且返回计算的结果。
我们要定义的缓存就是这个Calculator具体实现的一个封装。
我们看下用HashMap怎么实现:
public class MemoizedCalculator1<A, V> implements Calculator<A, V> {
private final Map<A, V> cache= new HashMap<A, V>();
private final Calculator<A, V> calculator;
public MemoizedCalculator1(Calculator<A, V> calculator){
this.calculator=calculator;
}
@Override
public synchronized V calculate(A arg) throws InterruptedException {
V result= cache.get(arg);
if( result ==null ){
result= calculator.calculate(arg);
cache.put(arg, result);
}
return result;
}
}
MemoizedCalculator1封装了Calculator,在调用calculate方法中,实际上调用了封装的Calculator的calculate方法。
因为HashMap不是线程安全的,所以这里我们使用了synchronized关键字,从而保证一次只有一个线程能够访问calculate方法。
虽然这样的设计能够保证程序的正确执行,但是每次只允许一个线程执行calculate操作,其他调用calculate方法的线程将会被阻塞,在多线程的执行环境中这会严重影响速度。从而导致使用缓存可能比不使用缓存需要的时间更长。
使用ConcurrentHashMap
因为HashMap不是线程安全的,那么我们可以尝试使用线程安全的ConcurrentHashMap来替代HashMap。如下所示:
public class MemoizedCalculator2<A, V> implements Calculator<A, V> {
private final Map<A, V> cache= new ConcurrentHashMap<>();
private final Calculator<A, V> calculator;
public MemoizedCalculator2(Calculator<A, V> calculator){
this.calculator=calculator;
}
@Override
public V calculate(A arg) throws InterruptedException {
V result= cache.get(arg);
if( result ==null ){
result= calculator.calculate(arg);
cache.put(arg, result);
}
return result;
}
}
上面的例子中虽然解决了之前的线程等待的问题,但是当有两个线程同时在进行同一个计算的时候,仍然不能保证缓存重用,这时候两个线程都会分别调用计算方法,从而导致重复计算。
我们希望的是如果一个线程正在做计算,其他的线程只需要等待这个线程的执行结果即可。很自然的,我们想到了之前讲到的FutureTask。FutureTask表示一个计算过程,我们可以通过调用FutureTask的get方法来获取执行的结果,如果该执行正在进行中,则会等待。
下面我们使用FutureTask来进行改写。
FutureTask
@Slf4j
public class MemoizedCalculator3<A, V> implements Calculator<A, V> {
private final Map<A, Future<V>> cache= new ConcurrentHashMap<>();
private final Calculator<A, V> calculator;
public MemoizedCalculator3(Calculator<A, V> calculator){
this.calculator=calculator;
}
@Override
public V calculate(A arg) throws InterruptedException {
Future<V> future= cache.get(arg);
V result=null;
if( future ==null ){
Callable<V> callable= new Callable<V>() {
@Override
public V call() throws Exception {
return calculator.calculate(arg);
}
};
FutureTask<V> futureTask= new FutureTask<>(callable);
future= futureTask;
cache.put(arg, futureTask);
futureTask.run();
}
try {
result= future.get();
} catch (ExecutionException e) {
log.error(e.getMessage(),e);
}
return result;
}
}
上面的例子,我们用FutureTask来封装计算,并且将FutureTask作为Map的value。
上面的例子已经体现了很好的并发性能。但是因为if语句是非原子性的,所以对这一种先检查后执行的操作,仍然可能存在同一时间调用的情况。
这个时候,我们可以借助于ConcurrentHashMap的原子性操作putIfAbsent来重写上面的类:
@Slf4j
public class MemoizedCalculator4<A, V> implements Calculator<A, V> {
private final Map<A, Future<V>> cache= new ConcurrentHashMap<>();
private final Calculator<A, V> calculator;
public MemoizedCalculator4(Calculator<A, V> calculator){
this.calculator=calculator;
}
@Override
public V calculate(A arg) throws InterruptedException {
while (true) {
Future<V> future = cache.get(arg);
V result = null;
if (future == null) {
Callable<V> callable = new Callable<V>() {
@Override
public V call() throws Exception {
return calculator.calculate(arg);
}
};
FutureTask<V> futureTask = new FutureTask<>(callable);
future = cache.putIfAbsent(arg, futureTask);
if (future == null) {
future = futureTask;
futureTask.run();
}
try {
result = future.get();
} catch (CancellationException e) {
log.error(e.getMessage(), e);
cache.remove(arg, future);
} catch (ExecutionException e) {
log.error(e.getMessage(), e);
}
return result;
}
}
}
}
上面使用了一个while循环,来判断从cache中获取的值是否存在,如果不存在则调用计算方法。
上面我们还要考虑一个缓存污染的问题,因为我们修改了缓存的结果,如果在计算的时候,计算被取消或者失败,我们需要从缓存中将FutureTask移除。
本文的例子可以参考 https://github.com/ddean2009/learn-java-concurrency/tree/master/MemoizedCalculate
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
时间:2020-04-24
详细介绍高性能Java缓存库Caffeine
1.介绍 在本文中,我们来看看Caffeine- 一个高性能的 Java 缓存库. 缓存和 Map 之间的一个根本区别在于缓存可以回收存储的 item. 回收策略为在指定时间删除哪些对象.此策略直接影响缓存的命中率 - 缓存库的一个重要特征. Caffeine 因使用 Window TinyLfu 回收策略,提供了一个近乎最佳的命中率. 2.依赖 我们需要在 pom.xml 中添加 caffeine 依赖: <dependency> <groupId>com.github.ben-
Java缓存Map设置过期时间实现解析
这篇文章主要介绍了Java缓存Map设置过期时间实现解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 前言 最近项目需求需要一个类似于redis可以设置过期时间的K,V存储方式.项目前期暂时不引进redis,暂时用java内存代替. 解决方案 1. ExpiringMap 功能简介 : 1.可设置Map中的Entry在一段时间后自动过期. 2.可设置Map最大容纳值,当到达Maximum size后,再次插入值会导致Map中的第一个值过期.
如何在 Java 中实现一个 redis 缓存服务
缓存服务的意义 为什么要使用缓存?说到底是为了提高系统的运行速度.将用户频繁访问的内容存放在离用户最近,访问速度最快的地方,提高用户的响应速度.一个 web 应用的简单结构如下图. web 应用典型架构 在这个结构中,用户的请求通过用户层来到业务层,业务层在从数据层获取数据,返回给用户层.在用户量小,数据量不太大的情况下,这个系统运行得很顺畅.但是随着用户量越来越大,数据库中的数据越来越多,系统的用户响应速度就越来越慢.系统的瓶颈一般都在数据库访问上.这个时候可能会将上面的架构改成下面的来缓解数
在Java中使用redisTemplate操作缓存的方法示例
背景 在最近的项目中,有一个需求是对一个很大的数据库进行查询,数据量大概在几千万条.但同时对查询速度的要求也比较高. 这个数据库之前在没有使用Presto的情况下,使用的是Hive,使用Hive进行一个简单的查询,速度可能在几分钟.当然几分钟也并不完全是跑SQL的时间,这里面包含发请求,查询数据并且返回数据的时间的总和.但是即使这样,这样的速度明显不能满足交互式的查询需求. 我们的下一个解决方案就是Presto,在使用了Presto之后,查询速度降到了秒级.但是对于一个前端查询界面的交互式查询来
JavaWeb禁止浏览器缓存当前Web页面的方法
所谓浏览器缓存,是指当第一次访问网页时,浏览器会将这些网页缓存到本地,当下一次再访问这些被缓存的网页时,浏览器就会直接从本地读取这些网页的内容,而无需再从网络上获取. 虽然浏览器提供的缓存功能可以有效地提高网页的装载速度,但对于某些需要实时更新的网页,这种缓存机制就会影响网页的正常显示.幸好在HTTP响应消息头中提供了三个字段可以关闭客户端浏览器的缓存功能.下面三条语句分别使用这三个字段来关闭浏览器的缓存: response.setDateHeader("Expires", 0); r
Java内存缓存工具Guava LoadingCache使用解析
这篇文章主要介绍了Java内存缓存工具Guava LoadingCache使用解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 一.Guava介绍 Guava是Google guava中的一个内存缓存模块,用于将数据缓存到JVM内存中.实际项目开发中经常将一些公共或者常用的数据缓存起来方便快速访问. Guava Cache是单个应用运行时的本地缓存.它不把数据存放到文件或外部服务器.如果不符合需求,可以选择Memcached.Redis等工具
如何基于LoadingCache实现Java本地缓存
这篇文章主要介绍了如何基于LoadingCache实现Java本地缓存,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 前言 Guava是Google开源出来的一套工具库.其中提供的cache模块非常方便,是一种与ConcurrentMap相似的缓存Map. 官方地址:https://github.com/google/guava/wiki/CachesExplained 开始构建 一. 添加依赖 <dependency> <groupI
Java本地缓存的实现代码
使用场景 在 Java 应用中,对于访问频率高,更新少的数据,通常的方案是将这类数据加入缓存中.相对从数据库中读取来说,读缓存效率会有很大提升. 在集群环境下,常用的分布式缓存有 Redis . Memcached 等.但在某些业务场景上,可能不需要去搭建一套复杂的分布式缓存系统,在单机环境下,通常是会希望使用内部的缓存( LocalCache ). 实现 这里提供了两种 LocalCache 的实现,一种是基于 ConcurrentHashMap 实现基本本地缓存,另外一种是基于 Linked
实现 Java 本地缓存的方法解析
缓存,我相信大家对它一定不陌生,在项目中,缓存肯定是必不可少的.市面上有非常多的缓存工具,比如 Redis.Guava Cache 或者 EHcache.对于这些工具,我想大家肯定都非常熟悉,所以今天我们不聊它们,我们来聊一聊如何实现本地缓存.参考上面几种工具,要实现一个较好的本地缓存,平头哥认为要从以下三个方面开始. 1.存储集合的选择 实现本地缓存,存储容器肯定是 key/value 形式的数据结构,在 Java 中,也就是我们常用的 Map 集合.Map 中有 HashMap.Hashta
Java LocalCache 本地缓存的实现实例
源码地址: GitHub 使用场景 在Java应用中,对于访问频率高,更新少的数据,通常的方案是将这类数据加入缓存中.相对从数据库中读取来说,读缓存效率会有很大提升. 在集群环境下,常用的分布式缓存有Redis.Memcached等.但在某些业务场景上,可能不需要去搭建一套复杂的分布式缓存系统,在单机环境下,通常是会希望使用内部的缓存(LocalCache). 实现 这里提供了两种LocalCache的实现,一种是基于ConcurrentHashMap实现基本本地缓存,另外一种是基于Linked
Java中LocalCache本地缓存实现代码
前言 本次分享探讨java平台的本地缓存,是指占用JVM的heap区域来缓冲存储数据的缓存组件. 一.本地缓存应用场景 localcache有着极大的性能优势: 1. 单机情况下适当使用localcache会使应用的性能得到很大的提升. 2. 集群环境下对于敏感性要求不高的数据可以使用localcache,只配置简单的失效机制来保证数据的相对一致性. 哪些数据可以存储到本地缓存? 1.访问频繁的数据: 2.静态基础数据(长时间内不变的数据): 3.相对静态数据(短时间内不变的数据). 二.jav
微信小程序基于本地缓存实现点赞功能的方法
本文实例讲述了微信小程序基于本地缓存实现点赞功能的方法.分享给大家供大家参考,具体如下: wxml中的写法 注意: 1. 使用wx:if="{{condition}}" wx:else实现图标的切换效果: 2. 为图片绑定点击事件bindtap="toCollect",两个image标签都要绑定! <image wx:if="{{collection}}" src="/images/icon/pic1.png" bind
基于JavaMail的Java实现复杂邮件发送功能
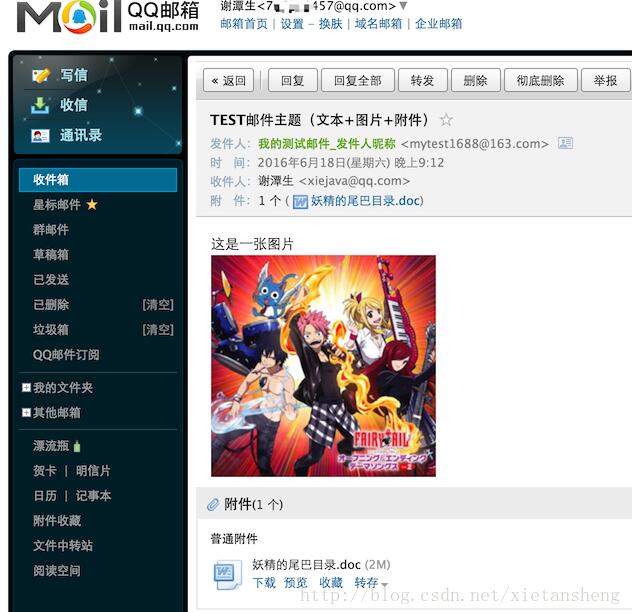
上一篇文章 基于 JavaMail 的 Java 邮件发送:简单邮件发送 讲解了邮件的基本协议,JavaMail组件,创建并发送一封简单邮件的详细步骤.本文将介绍如何创建并发送一封包含图片和附件的复杂邮件. 一封复杂的邮件内容可以看做是由很多节点(或者可以说是"片段"/"部分"/"零件")组成,文本.图片.附件等都可以看成是邮件内容中的一个节点.这些节点之间又可以相互关联组合成一个节点.最终组合成一个大节点就是邮件的正文内容. 完整代码演示: p
Nginx服务器中浏览器本地缓存和虚拟机的相关设置
自动列出目录配置: 下载过开源软件的都知道,一个很简单的页面列出了所有版本的源码包,这就是开启了自动列出目录 如下配置,在虚拟主机location / {--}目录控制中配置自动列出目录: location / { autoindex on; } 浏览器本地缓存设置: 浏览器是为了加速浏览,浏览器在用户磁盘上对最近请求过的文件进行存储,当访问者再次请求这个页面, 浏览器可以从本地磁盘显示文件,以达到加速浏览的效果,节约了网络资源,提高了网络效率 关键字: expires 默认值: off 作用域
Android开发之ImageLoader本地缓存
ImageLoader是一个图片缓存的开源库,提供了强大的图片缓存机制,很多开发者都在使用,今天给大家介绍Android开发之ImageLoader本地缓存,具体内容如下所示: 本地缓存在缓存文件时对文件名称的修改提供了两种方式,每一种方式对应了一个Java类 1) HashCodeFileNameGenerator ,该类负责获取文件名称的hashcode然后转换成字符串. 2) Md5FileNameGenerator ,该类把源文件的名称同过md5加密后保存. 两个类都继承了FileNam
正文到此结束
- 本文标签: sql ask cache 多线程 分布式 Nginx XML 并发 数据库 开源 开发者 ACE Collection 需求 HashMap pom REST 安全 src 业务层 IDE id web 实例 缓存 final UI 删除 IO 代码 数据库访问 源码 软件 集群 dist message redis Master java 解析 synchronized https 开发 配置 http 图片 GitHub Presto 协议 value cat explain 下载 数据 希望 目录 Android JVM git 参数 map 主机 数据缓存 Google 一致性 服务器 key 加密 线程 Java类 开源软件 文章 页缓存 时间 ConcurrentHashMap mail 快的
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

