面试中的HashMap、Hashtable和ConcurrentHashMap,你知道多少?
前言
学过数据结构的读者们想必其实也都学过HashMap,面试官问你的时候,想来你都是很清楚的知道HashMap是怎样的一个构成?确实很简单,就是数组加链表嘛。那再问你Hashtable和HashMap的区别是什么?脑子也不用想,又能出来一个答案 线程安全和线程不安全 ,Hashtable不允许存在空值呗。那继续往深处问,HashMap是怎么做性能优化的?这个时候你是怎么样的反应呢?如果知道红黑树,那就能答出来;不知道的话那不是就凉了,因为这个时候连ConcurrentHashMap都需要放弃回答了!!!
部分图片引自JDK1.7 HashMap 导致循环链表
HashMap源码导读
其实思路大致都是相同的,所以这里只分析一个HashMap,先贴出他的几个常见用法。
HashMap hashMap = new HashMap();
hashMap.put(key, value);
hashMap.get(key);
主要从这个方面对HashMap的整个工作流程进行分析。
HashMap()
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
// 对数组的一个保护,不能超过int最大值范围
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
public HashMap(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
}
其实在无参构造方法,我们并没有看到所谓的数组的初始化,他只对我们的负载因子做了一个初始化,也就是我们一直常说的 0.75f ,但为什么是 0.75f 呢,只能说是一个经验值,也就是经验所致,因为 0.5f 时空间太浪费, 1f 时容易出现极端情况,当然也不是随便定的,设计师肯定是做了很多的测试的,但依旧是一个经验值,或者说是测试后的最优解。
回到我们之前的问题,既然我们学习的时候学到过HashMap是一个数组+链表。 那做第一个思考为什么初始化不见了? 先带着这样的问题继续啊往下走。
先看看自己动手初始化容量构造函数,最后都会调用下方的 tableSizeFor() 方法。
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
本质意思就是把数值变成2的指数倍,这样的好处是计算方便处理。但是出现同样的问题,没有初始化,这里也只看到了容量。问题继续保留。
put(key, value)
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true); // 1
}
// 由注释1直接调用的方法putVal()
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 第一次来判断的时候,显然的tab是一个空,因为在构造函数中,我们并没有看到他的初始化,那么必然要调用resize()方法。
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length; // 2,未能初始化而必然调用的方法
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize(); // 2
afterNodeInsertion(evict);
return null;
}
// 由注释2直接调用的方法
// 由多种方法调用到这里:
// 1. 尚未初始化
// 2. 保存的数据超出 容量 * 负载因子
// 3. 数据被删的不足以支持树形的时候
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
// 。。。。
// 此处对容量大小做了一系列的判定,为定义初始化容量为16
// 。。。。
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
// 进行了整个的table进行一个初始化
// 而这个table就是一个Node的数组
// Node也就是链表的一个个节点,读者自己点进去观察就能看到next节点
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
// 。。。。。
}
到这里我们就已经明白了,原来初始化的过程已经在这里进行了定义,这也就解决了我们的第一个问题了。 但是随之而来第二个问题,为什么要这样设计呢? 这里给出我思考的一个答案,如果只创建了,却没有进行使用呢?那至少就会占去16个数据类型大小的内存,而这样的创建方法,就是对内存的一种保护机制。
第三个问题,为什么要转变成树形(当然它是有好听的名字的,叫做红黑树)? 其实结构的转换为的不外乎几种原因效率问题、空间占用问题。如果使用链表查询,他的查询速度是 O(n) ,而红黑树的查询速度是 O(logn) 。但是红黑树带来的问题确实一个存储容量的问题,作为二叉树,他需要同时保存左右节点,而单链表只有一个节点,那么内存消耗的问题就出来了。树的构造问题能讲一篇博客,所以就不再这里讲先了。
get(key)
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
通过hash值来寻找我们对应的节点,那我们就需要先来看看这个hash是怎么计算的。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
答案也是一目了然的,获得hashCode()值,然后低16位进行与高16位的异或运算。其实就是为了算出另一种样貌的hash值。 但是我们为什么要这么做呢?稍后给出一个解答。
那我们获得了hash值以后,就需要来找找我们的节点了。
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)
// 对树形中的数据进行查找
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
// 对链表中的数据进行查找
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
然后获取到我们需要的数据,然后就返还给我们了,哇哦!!原来整体就够就是这么简单的。 (其实真正写起来不简单,分析起来简单一点罢了,嘿嘿。)
为什么hash要进行高低16的异或运算?
你是否有考虑过这样的问题,但是却可能频频发生在你的代码中呢?
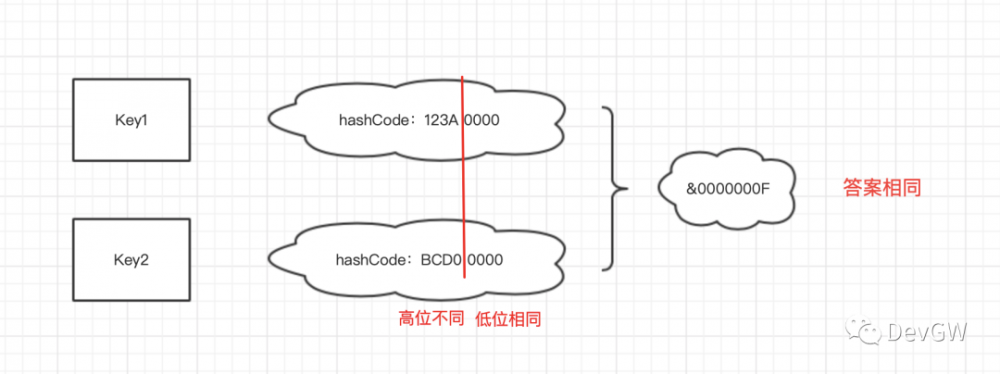
前提:key1和key2两个值不同,但hashCode的高位不同,低位相同。
你能知道,一般在我们的项目中,一个hashmap并不会开的过分夸张的大,可能我们只用了32个(我项目里最大好像也就到这儿了)。而我给出的范围是16位数,32才只到达了5位,远远达不到要求,那么这样情况的出现频率也会异常的夸张。
所以Java工程师们也给出了自己的解决方案也就是高低位的异或运算,他有一个好听的名字 —— 扰动函数 。
运算其实本质上来说你可以这样认为,就是让其他位上的二进制数们也能够加入到这场运算的盛宴中。经过这样的运算,可能Key1最后的运算对象就从123A000变成了123A123A,而Key2就从BCD00000变到了BCD0BCD0,这样他们与最后的0000000F的异或运算就与原本的结果就迥然不同了。
再来看看经过了扰动函数加工过后的冲突状况。

这是摘自专栏文章《An introduction to optimising a hashing strategy》里的的一个实验:他随机选取了352个字符串,在他们散列值完全没有冲突的前提下,对它们做低位掩码,取数组下标。
那么这个时候我们的一个HashMap长度为512,掩码取低9位时,冲突次数能从103次降低到92次,将近10%的效率提升。
当然会有读者问,为什么不多进行几次干扰?
确实多次干扰能够带来更好的效果,但是会出现一个问题,效率。计算机的一切出发点就是效率问题,一次的干扰能够带来足够好的收益时,是能够作为折中方案被录用的。
HashMap和Hashtable有什么不同
既然我们已经知道了整个的HashMap的构成,那主要要了解的对象就应该是Hashtable了。那我们先来看看Hashtable的构造函数好了。
// 无参构造函数初始化,处理容量为11,负载因子为0,75
public Hashtable() {
this(11, 0.75f);
}
// 链表的创建在默认最后嗲用的构造函数中就已经创建
// 那这里我们就发现了第一个不同的地方。
public Hashtable(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal Load: "+loadFactor);
if (initialCapacity==0)
initialCapacity = 1;
this.loadFactor = loadFactor;
table = new Entry<?,?>[initialCapacity];
threshold = (int)Math.min(initialCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
}
文内写了第一个不同点, 但是还有一个不同点,你是否发现了? 就是容量的问题,在HashMap中的容量计算全部都是往2的指数倍进行靠近的,但是Hashtable并没有做出这样的选择,但是在负载因子上又出奇的一致。
再看看Hashtable的put(key, value)方法。
public synchronized V put(K key, V value) {
// 判空机制的存在,和HashMap并无判空,也就容许null作为key存在
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry<K,V> entry = (Entry<K,V>)tab[index];
for(; entry != null ; entry = entry.next) {
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
addEntry(hash, key, value, index);
return null;
}
我们常说Hashtable是一个线程安全的类,而这里也给了我们答案,他在方法上加了synchronized,也就是锁的机制,来完成我们的同步。 但是思前想后,我都存在一个疑惑,你们是否看到了他的resize()函数呢? ,没错,并不存在resize()函数。
那我们继续往下看看好了,因为在这个函数中还存在一个addEntry()方法,看看里面是不是有扩容机制呢。
private void addEntry(int hash, K key, V value, int index) {
modCount++;
Entry<?,?> tab[] = table;
if (count >= threshold) {
// Rehash the table if the threshold is exceeded
rehash();
tab = table;
hash = key.hashCode();
index = (hash & 0x7FFFFFFF) % tab.length;
}
// Creates the new entry.
@SuppressWarnings("unchecked")
Entry<K,V> e = (Entry<K,V>) tab[index];
tab[index] = new Entry<>(hash, key, value, e);
count++;
}
原来他改头换面了,在addEntry()方法中,我们发现他的重构函数是一个叫做rehash()的函数。而扩容机制和HashMap相同都是放大两倍的操作来进行完成的。但是从效率上来讲,因为一直数组+链表的形式存在,就算是没有线程安全的机制,效率上来说总体还是比HashMap差劲的。
ConcurrentHashMap就线程安全的性能优化
说到ConcurrentHashMap,其实他和HashMap一样都是存在JDK1.8前后的版本差异的。
网上可以查到很多关于version 1.8之前的机制,也就是分段锁,可以看做成多个Hashtable的组合。而version 1.8之后的机制,就是锁槽了。迟点做一个详细的解析。
既然是性能优化,那么就应该有性能优化的点。
(1)和HashMap的实现方式一样, 数组+链表+红黑树 ,查找性能上优于Hashtable。 前提: 使用的容量大于8。
(2) 分段锁机制 / 锁槽机制: 不再是整个数组加锁,而是对单条或者几条链表和红黑树进行加锁,也就同时能够就收多个不同的hash操作了。
因为我本地使用的JDK1.8,所以我们就先研究一下JDK1.8的做法好了。
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
//。。。。。
}
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 引入了CAS机制
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
//。。。。。
else {
V oldVal = null;
synchronized (f) {
// 。。。。。
}
//。。。。。
}
}
addCount(1L, binCount);
return null;
}
需要关注的是加锁对象synchronized (f)。对变量f代表就一个hash对应的一条链表,而加锁正好加的是这条链表,或者这颗红黑树上,另外索引为空时通过CAS的方式来创建一个新的节点。这也就是JDK 1.8引入的新机制CAS+锁。
那我们再看看JDK 1.7的做法是什么样的,就直接用一张图来直观感受吧
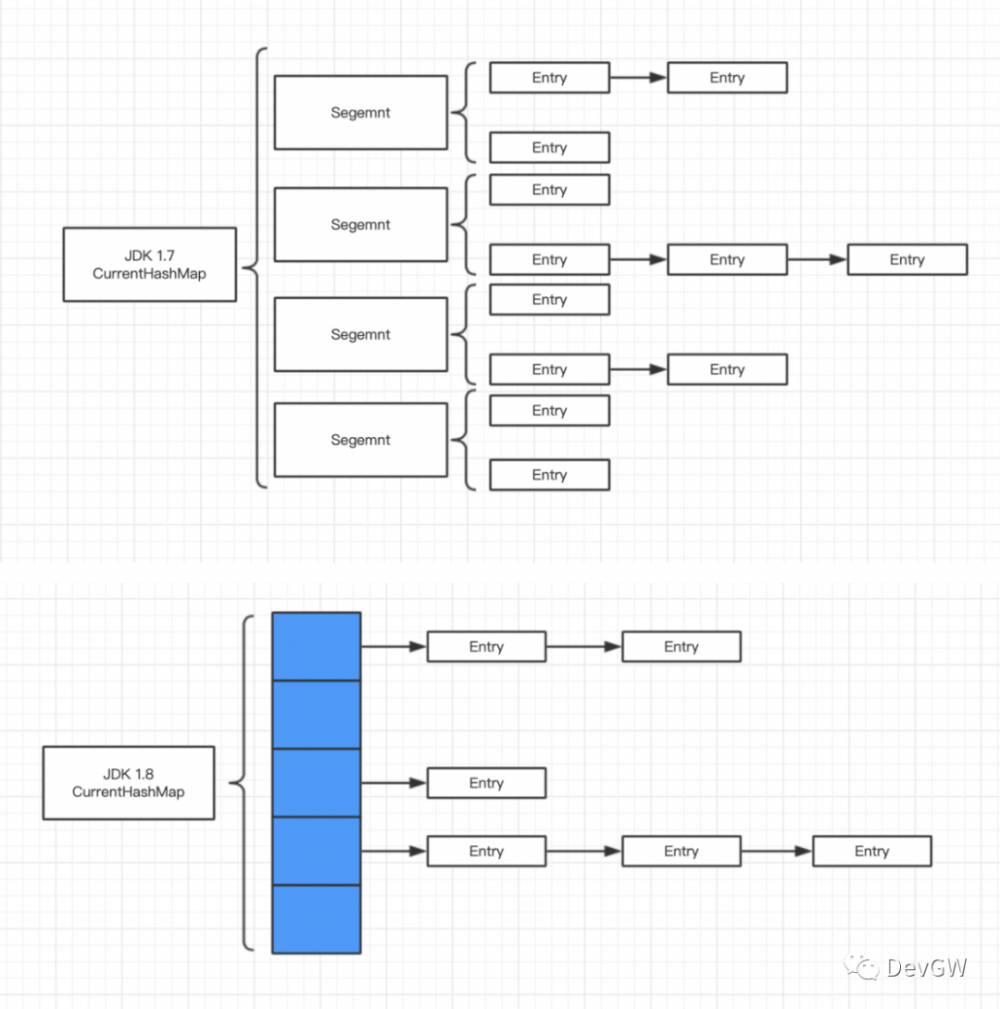
version 1.7的时候根据Segment来给每一链配锁,但是带来的问题就是hash搜索时间变长。不过相较于Hashtable而言,性能上还是更加出色的。因为分段锁的机制也就不影响两两段之间并不会存在锁的问题,也就提高了性能。
而相较于version 1.8来说,性能确是不足的,首先是引入了红黑树的原因,第二Segment的维护其他相较于现在是一个比较麻烦的过程。而后者调整为单个Node进行一个调整,需要进行调整的范围减小了,带来了两个好处,一是好管理,二是可同时操作的数量增加。
HashMap中的循环链
这是一个引申的内容,同样的分为version 1.7和1.8。当然产生的原因无非就是高并发的情况下,单线程处理的情况下怎么可能发生这种情况??
先讲讲version 1.7的循环链问题,和产生和这个问题的原因。
先让我们知道一下version 1.7的问题点在哪儿。
void transfer(Entry[] newTable)
{
Entry[] src = table;
int newCapacity = newTable.length;
// 很轻松是一个复制的工程
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}
整体来说就一个头插法的模式。
单线程情况下
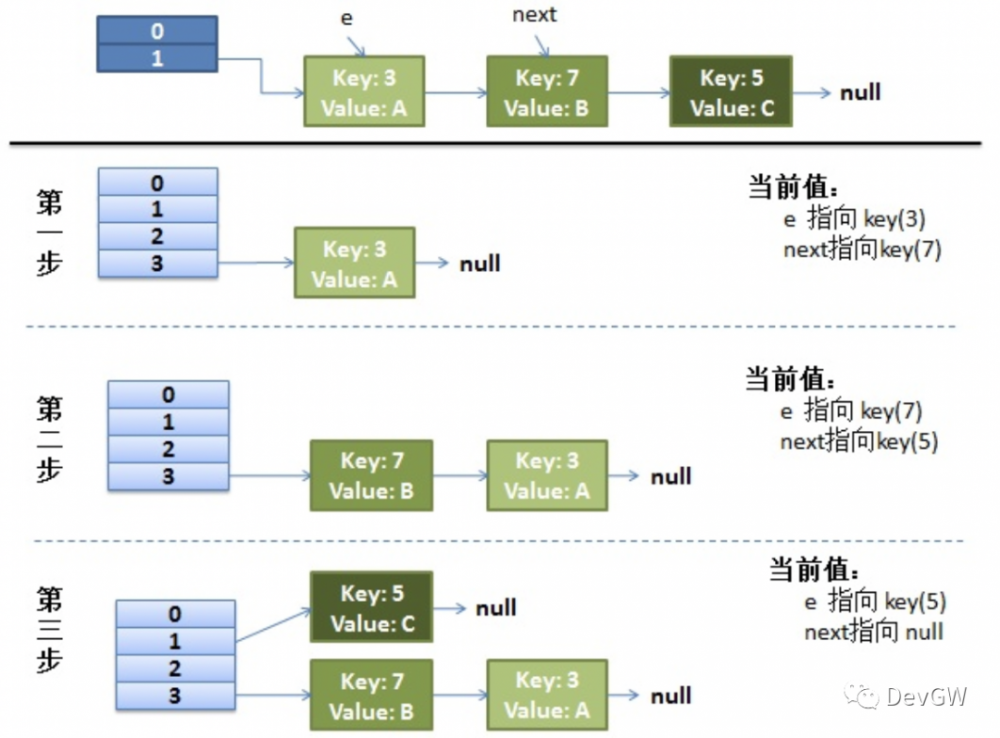
我们说了是头插法,你能够看到最明显的地方就是7和3的位置互换。
高并发情况下
样例基于的是JDK 1.7的头插法
步骤一:
线程1获取到e = 3,且next = 7的时候被挂起,而线程2已经执行完毕,就会得到下图的结果。
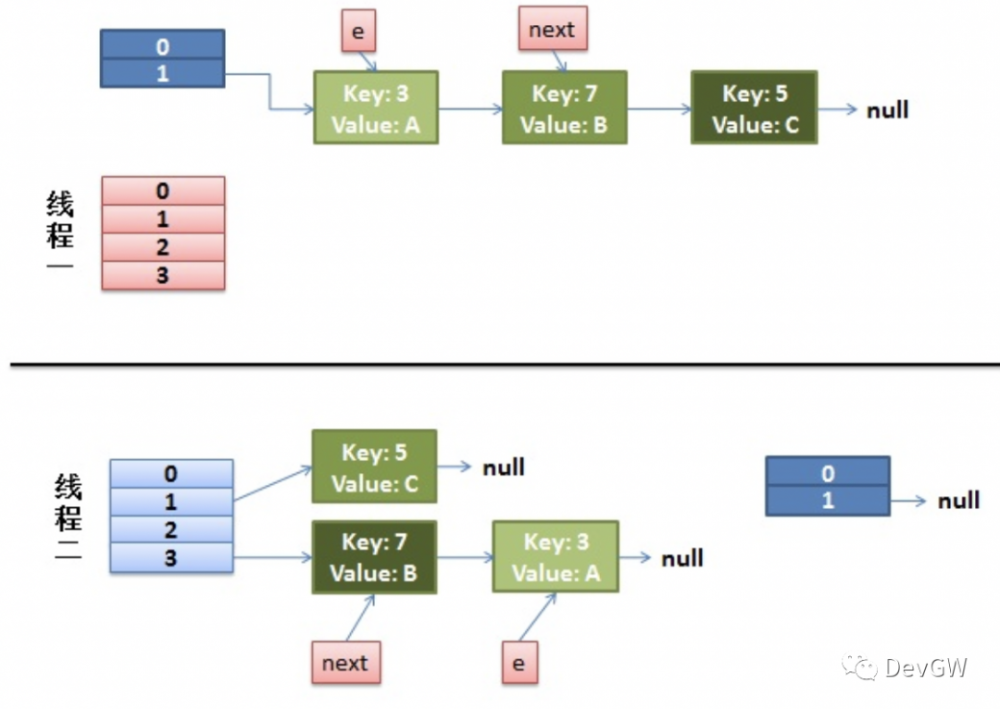
步骤二:
那现在就是由线程1完成新的一份操作了,但是实际上整体数据已经修改,他手里的数据是一份脏数据,他保持了之前的数据,而之前数据的7,已经成为了现在的头。
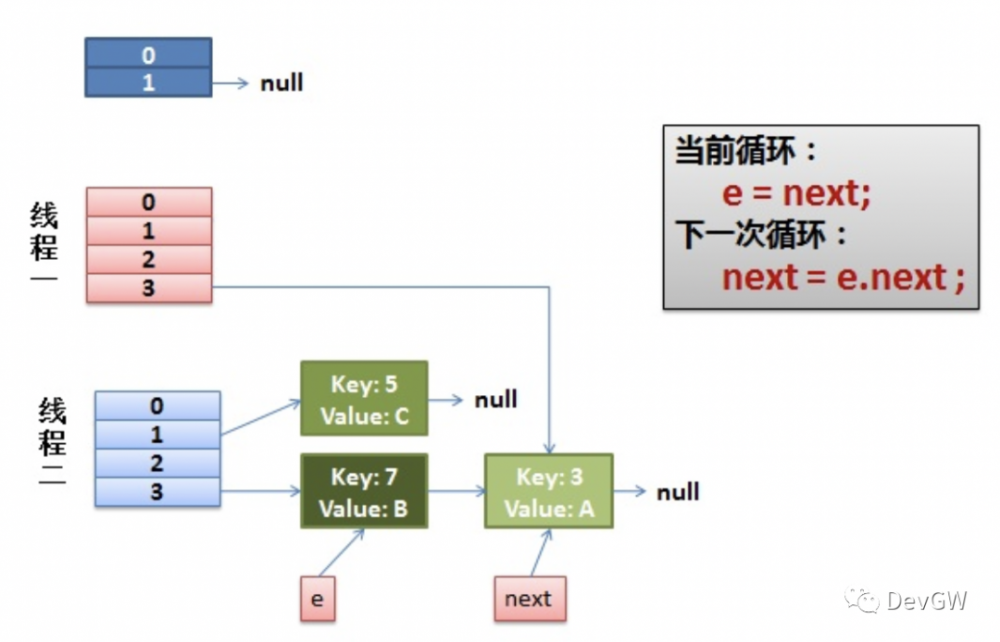
步骤三:
步骤二后,3完成了插入,再将7拿到手了,但是发现7的next指针还是指向了3,那完了,就变成了3 -> 7 -> 3 -> 7 .......的死循环状态了。

其实1.8做过了改进,但是同样的会照成循环链的问题。
其实挺多博客都就version 1.8会说已经结束了这个问题,但是为什么再提,那还不是因为被发现这个问题依旧存在嘛。但是这次不是头插法了,是出现在树形和链表的数据结构转化上。
JDK1.8用于复现循环链问题的Demo
https://github.com/gsonkeno/java-interview/blob/master/src/main/java/com/gsonkeno/interview/HashMap1.java
其实知道即可,因为谁高并发状况还要用HashMap, 这不是明知山有虎,偏向虎山行的蠢笨做法嘛。
总结
其实总体来说就是性能上是 HashMap > ConcurrentHashMap > Hashtable ,考虑上线程安全以后 ConcurrentHashMap > Hashtable 。也就是基于这些原因才会出现后来我们在使用ConcurrentHashMap出现来替代Hashtable的情况。
红黑树也是我们对于性能优化的一种策略,但是从构建角度来看的话,红黑树的构建方式确实还是比较麻烦的,需要一定的逻辑基础。
推荐阅读:
Glide都在用的LruCache,你学会了吗?
Android小知识-如何加载外部dex文件中的类
【音视频连载-011】第二季 FFmpeg 一层一层获取文件信息

喜欢就点个 「在看」 吧 ▽
正文到此结束
- 本文标签: http 测试 map 高并发 空间 equals 锁 git 图片 管理 回答 HTML src java 安全 id 注释 索引 value node cache IDE 性能优化 App 并发 同步 线程 Master 时间 ConcurrentHashMap key 文章 tab 数据 本质 CTO synchronized 总结 MQ 代码 HashTable 解析 博客 源码 UI 工程师 CEO 构造方法 final https IO GitHub HashMap Android
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

