架构-稳定性建设逻辑问题实战总结
总述
稳定性问题分为逻辑问题和架构问题。
逻辑问题三板斧:理念正确、流程规范、刨根问底。
逻辑问题
理念正确
曹操煮酒论英雄,对刘备发表了自己对英雄的看法:
胸怀大志,腹有良策,包藏宇宙之机,吞吐天地之气。
意思是说所谓英雄,要志气远大,计谋精良。胸怀能包含宇宙,志气能吞吐天地。对稳定性建设来说就是既要有道,又要有术,道为先。
稳定性理念举例
Everything fails!
如果一件事情有可能发生则在生产环境中一定会发生。
不要容忍破窗户。
过程对了结果一定不会差。
一个问题可能是许多事故的原因。
WHY
理念是目标和原则。错误的理念产生不了正确的行动,在稳定性方面是巨大的隐患。
试想如果一个人觉得一个系统是不可能出问题的,那他一定就不会制定故障处理的紧急预案,出现问题了也不能很好的控制影响范围。
如果觉得一个问题是小概率事件是不会发生的,就不会对问题进行修复和补救。而所谓小概率事件如果发生概率在万分之一。一般线上系统一天调用量就不只几万次,所以也就没有什么小概率事件了。
小的问题不修复,问题积少成多,不但修复变的困难,还会让人产生反正已经这样了的放弃心理,最终造成大问题。
流程规范
很多大公司的稳定性60%以上都是通过流程来保障的,有些流程经过自动化,开发人员习以为常,反而没有去深究其背后的技术原理。比如变更管理流程,一般大公司会有相应的系统,而这个系统实际上是将变更管理的所有要点做了自动化。
变更管理
变更管理大体上分为两部分:变更识别和变更流程。
变更识别:
要限制变更的影响,首先应该确保每一个生产变更都要有以下的数据记录
1>变更的准确日期和时间
2>将要发生变更的系统
3>实际的变更
4>变更期待的结果
5>变更人员的联系方式
变更流程:
1>提出2>批准3>计划4>实施5>验证6>报告
变更识别是适用于初创型小公司的一种轻量级流程,一般有一定规模的公司都会使用变更流程。而变更流程的大部分过程都可以通过持续集成实现。这个过程的目的是为了安全的变更而不是减缓变更。
在实际开发的时候通常会遇到一个矛盾:一方面要控制发版频率和时间,因为变更要耗费时间和精力,最重要的是每次上线都有风险。所以会有静默期、发版许可时间;另一方面要让变更尽量小,因为变更越大风险越高。
对于这个矛盾,我的看法是这两个是两个分开的问题。
发版时间只要控制在低峰期以及人员齐全的时间段,比如不要在周五,因为周六休息,问题不能及时发现。发版频率需要靠每次问题解决彻底、每次发布阶段清晰等设计开发层面解决,就是说每次发版尽量:与其扬汤止沸,不如釜底抽薪。这样一个问题或功能确保一次上线成功,不用打补丁,这样来减少频率。
变更尽量小,我的看法是最好一次发布只是一个变更,不要多个成员的不同内容一起上线。否则一旦出现问题不好定位。有的人看法是3个内容一起上线只有1次风险,而分三次上线会有3次风险。我认为哈,如果3次变更真的出现了3个问题是不是代码质量太差了,需要从其他方面先把质量提升上来。而分为3次,每次变更内容清晰,也便于更高的流程把控和上线验证,风险总体是要低的。
风险管理

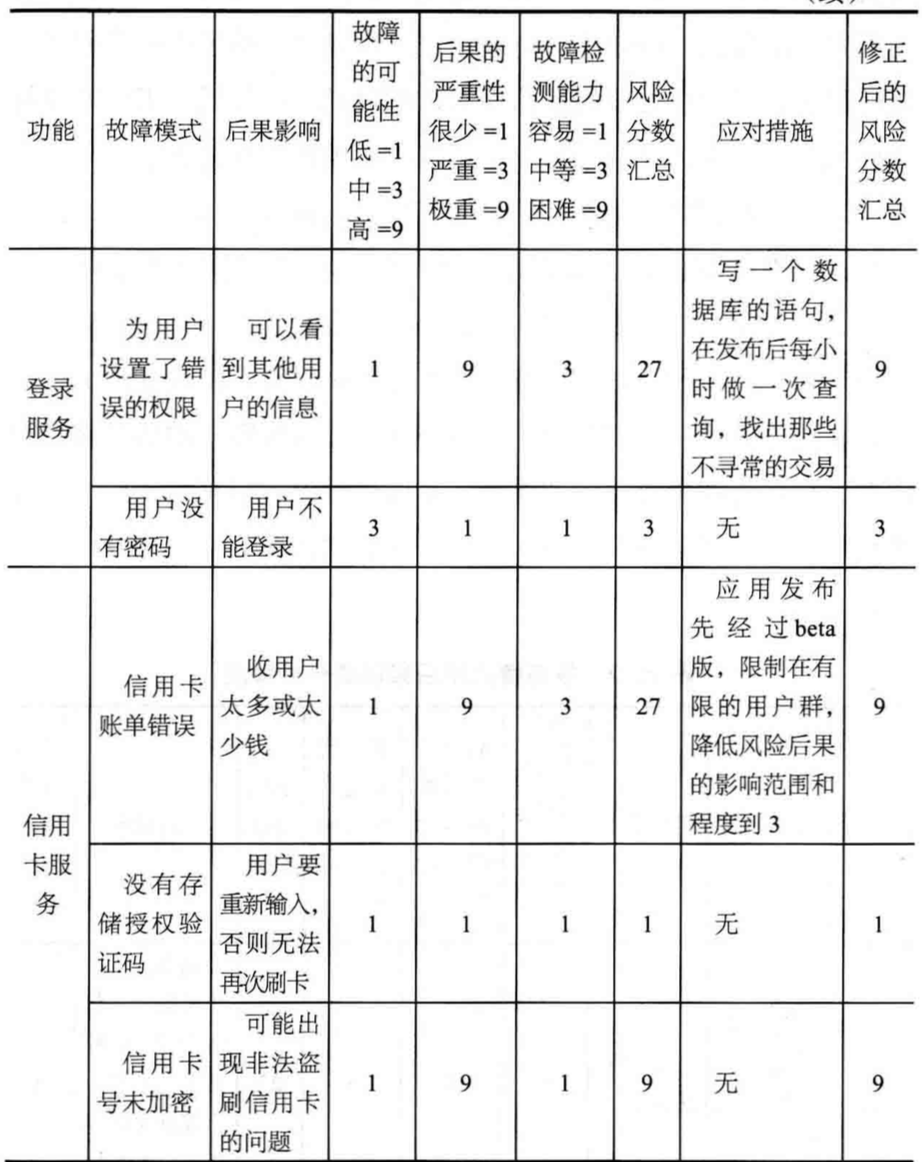
评估特定行动风险有种方法叫故障模式及影响分析法(Failure mode and effects analysis, FMEA)。
每个故障的现象可以根据下述三个因素来打分:故障的可能性、严重性和可检测性。可以选择使用1、3和9作为打分的范围,这是一种保守的打分方法,同时可以把高风险因素和中低风险因素区分开来。故障的可能性基本上是这个特定故障真实发生的概率。故障的严重性是指如果故障发生,对客户和业务产生的总体影响。这种影响可以用金钱损失、声誉损失或任何与业务有关的其他因素来测量。故障的可检测能力指如果故障发生你是否能够注意到。
对单项失效模式和效果打分后,将这些分数相乘得到总的风险评分,即可能性得分*严重性得分*检测能力得分。这个分数显示了一个特定组件在整体行为中的整体风险。
FMEA过程的下一步是确定可以执行或落实到位的缓解步骤,已降级特定因素的风险。例如,如果一个功能组件的可检测能力有非常高的风险分数,这意味着如果事件发生,那将很难发出通知。因此该团队可能会决定提前准备一些查询,在产品或服务发布后,每小时检查一次数据库,检测是否有故障发生的迹象,如丢失数据或数据错误。此环节措施对该组件的风险因素有降级的作用,同时应该说明风险可以降级到什么程度。
流程规范术实例
1>设计阶段
统一设计模板、其中我编写了稳定性三十六计的checklist,可以作为稳定性设计的参考规范,详见: 《 稳定性「三十六计」实战和背后的逻辑》
2>开发阶段
2.1>可行性验证阶段写好测试用例,测试驱动开发
2.2>与第三方交互,交互前后都要打日志。交互后的日志要把第三方返回的结果打印出来。一旦第三方出现问题。我们拿着第三方返回的结果来跟第三方沟通。避免责怪他人讹的出现。
3>上线规范
提测分支至少2名同学进行code review。Reviewer一般为之前负责过此模块开发的同学和架构师。
刨根问底
还是那句话:与其扬汤止沸,不如釜底抽薪。实施刨根问底最常用的手段是复盘。说复盘先从问题的发生说起。
一旦出现了问题或者故障,第一反应是什么?找原因?错!第一件要做的事情是「恢复现场」,先解决问题,控制和降低影响。比如生产环境突然load飙升、线程池被打满了。这时候应该马上启动紧急预案,重启服务或者机器,然后紧急扩容。如果问题发生前有过变更,则立即回滚。在发生问题的时候最好有个指挥者负责分派任务和协调人员。
现场恢复后再着手调查原因,可以多个人从不同层面来分析问题。比如这次问题主要是一个变更引起的。那么变更的开发人员是问题分析的主力,一般也是问题的责任人和复盘的发起者。但是其他人可以同时通过代码review 、监控等数据分析角度帮助一起定位。
原因基本定位之后,如果大家都还没离开。一个比较好的方式是以非常轻松的聊天的方式,让了解问题的人都自然的聚在一起,开一个头脑风暴的茶话会,将问题事前、事中、事后可以优化的都提出来,作为事件正式复盘前的素材。
复盘的流程
1>事件概述 2>事件影响 3>时间线 4>5why根本原因分析 5>经验教训 6>TODO
总结
稳定性问题中逻辑问题和架构问题的产生原因和侧重点都不同。架构问题如果不快速治理,很容易造成级联故障、雪崩等问题,从而引发稳定性危机。而架构大体满足需求时,逻辑问题是日常工作中更经常面对的问题。
减少逻辑问题一要靠人二要靠流程。所谓靠人,就是人的能力和素质越强,问题越少。 其中素质就包含理念价值观和刨根问题的精神和能力。对于流程,很多大公司都有很好的工具或系统来进行流程规范。但是作为开发人员,一定要避免「离开了平台,自己什么都不是」。流程规范的系统实现都很简单,关键点是实现了什么,平时的时候建议多加思索,将平台能力转化为自身能力。
最后,这句话很重要:「 与其扬汤止沸,不如釜底抽薪。 」
相关阅读
《 架构思考-业务快速增长时的容量问题 》
《 稳定性五件套-限流的原理和实现 》
《稳定性五件套-熔断的原理和实现》
正文到此结束
热门推荐









相关文章

近期评论
-
不会英语啊。
-
前100名用户会展示特殊的纪念徽章
-
-
https://pplx.ai/floraliu4199466 这个链接打不开是什么原因?
-
-
-
-
来看看,最近更新了一波,顺着友联过来的,几年过去了,网站越搞越好,厉害
-
哥太牛了
-
是呀,看您的IP显示在美国,还以为您移民了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

