CountDownLatch 和 CyclicBarrier 傻傻的分不清楚?
并发编程的三大核心是 分工 , 同步 和 互斥 。在日常开发中,经常会碰到需要在主线程中开启多个子线程去并行的执行任务,并且主线程需要等待所有子线程执行完毕再进行汇总的场景,这就涉及到分工与同步的内容了
在讲 有序性可见性,Happens-before来搞定 时,提到过 join() 规则,使用 join() 就可以简单的实现上述场景:
@Slf4j
public class JoinExample {
public static void main(String[] args) throws InterruptedException {
Thread thread1 = new Thread(() -> {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
log.info("Thread-1 执行完毕");
}
}, "Thread-1");
Thread thread2 = new Thread(() -> {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
log.info("Thread-2 执行完毕");
}
}, "Thread-2");
thread1.start();
thread2.start();
thread1.join();
thread2.join();
log.info("主线程执行完毕");
}
}
运行结果:
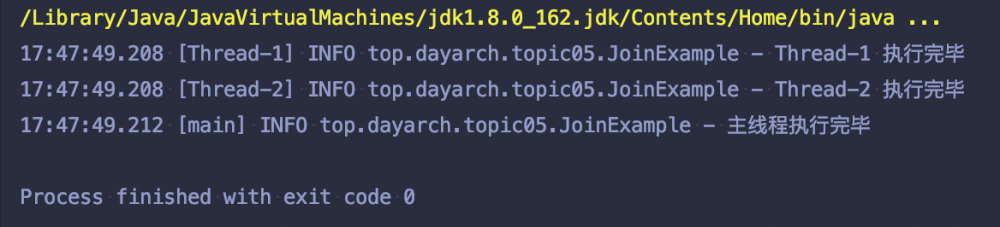
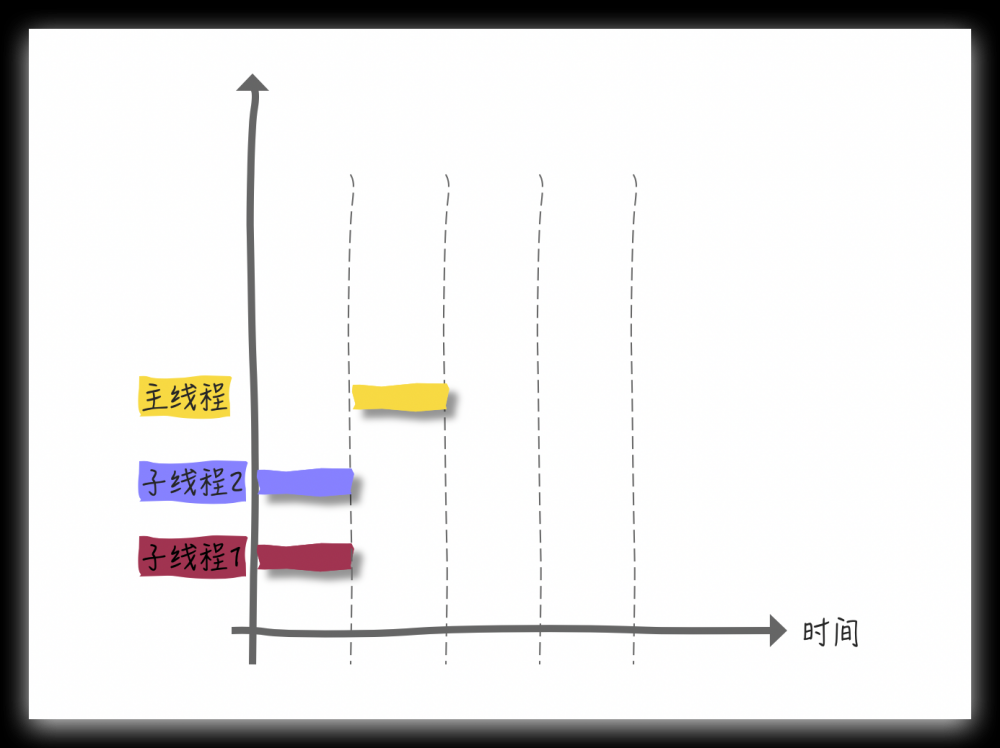
整个过程可以这么理解
我们来查看 join() 的实现源码:
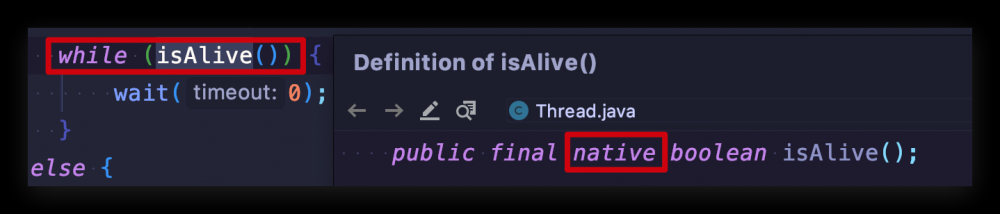
其实现原理是不停的检查 join 线程是否存活,如果 join 线程存活,则 wait(0) 永远的等下去,直至 join 线程终止后,线程的 this.notifyAll() 方法会被调用(该方法是在 JVM 中实现的,JDK 中并不会看到源码),退出循环恢复主线程执行。很显然这种循环检查的方式比较低效
除此之外,使用 join() 缺少很多灵活性,比如实际项目中很少让自己单独创建线程(原因在 我会手动创建线程,为什么要使用线程池? 中说过)而是使用 Executor, 这进一步减少了 join() 的使用场景,所以 join() 的使用在多数是停留在 demo 演示上
那如何实现文中开头提到的场景呢?
CountDownLatch
CountDownLatch, 直译过来【数量向下门闩】,那肯定里面有计数器的存在了。我们将上述程序用 CountDownLatch 实现一下,先让大家有个直观印象
@Slf4j
public class CountDownLatchExample {
private static CountDownLatch countDownLatch = new CountDownLatch(2);
public static void main(String[] args) throws InterruptedException {
// 这里不推荐这样创建线程池,最好通过 ThreadPoolExecutor 手动创建线程池
ExecutorService executorService = Executors.newFixedThreadPool(2);
executorService.submit(() -> {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
log.info("Thread-1 执行完毕");
//计数器减1
countDownLatch.countDown();
}
});
executorService.submit(() -> {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
log.info("Thread-2 执行完毕");
//计数器减1
countDownLatch.countDown();
}
});
log.info("主线程等待子线程执行完毕");
log.info("计数器值为:" + countDownLatch.getCount());
countDownLatch.await();
log.info("计数器值为:" + countDownLatch.getCount());
log.info("主线程执行完毕");
executorService.shutdown();
}
}
运行结果如下:
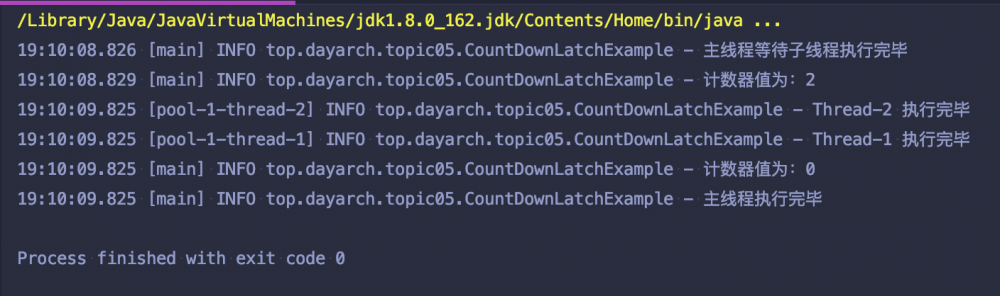
结合上述示例的运行结果,相信你也能猜出 CountDownLatch 的实现原理了:
countDownLatch.countDown()
不知道你是否注意, countDownLatch.countDown(); 这行代码可以写在子线程执行的任意位置,不像 join() 要完全等待子线程执行完,这也是 CountDownLatch 灵活性的一种体现
上述的例子还是过于简单, Oracle 官网 CountDownLatch 说明 有两个非常经典的使用场景,示例很简单,强烈建议查看相关示例代码,打开使用思路。我将两个示例代码以图片的形式展示在此处:
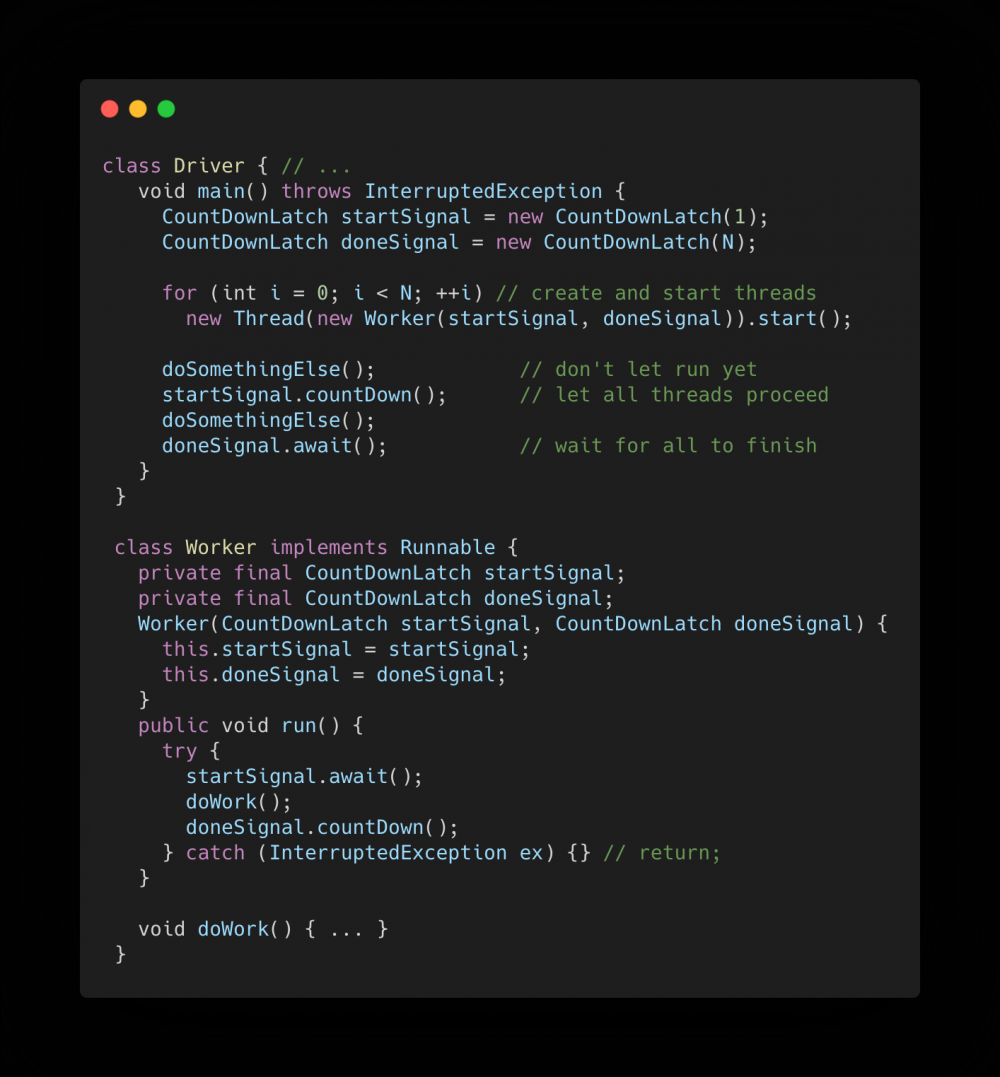
官网示例1
- 第一个是开始信号
startSignal,阻止任何工人Worker继续工作,直到司机Driver准备好让他们继续工作 - 第二个是完成信号
doneSignal,允许司机Driver等待,直到所有的工人Worker完成。
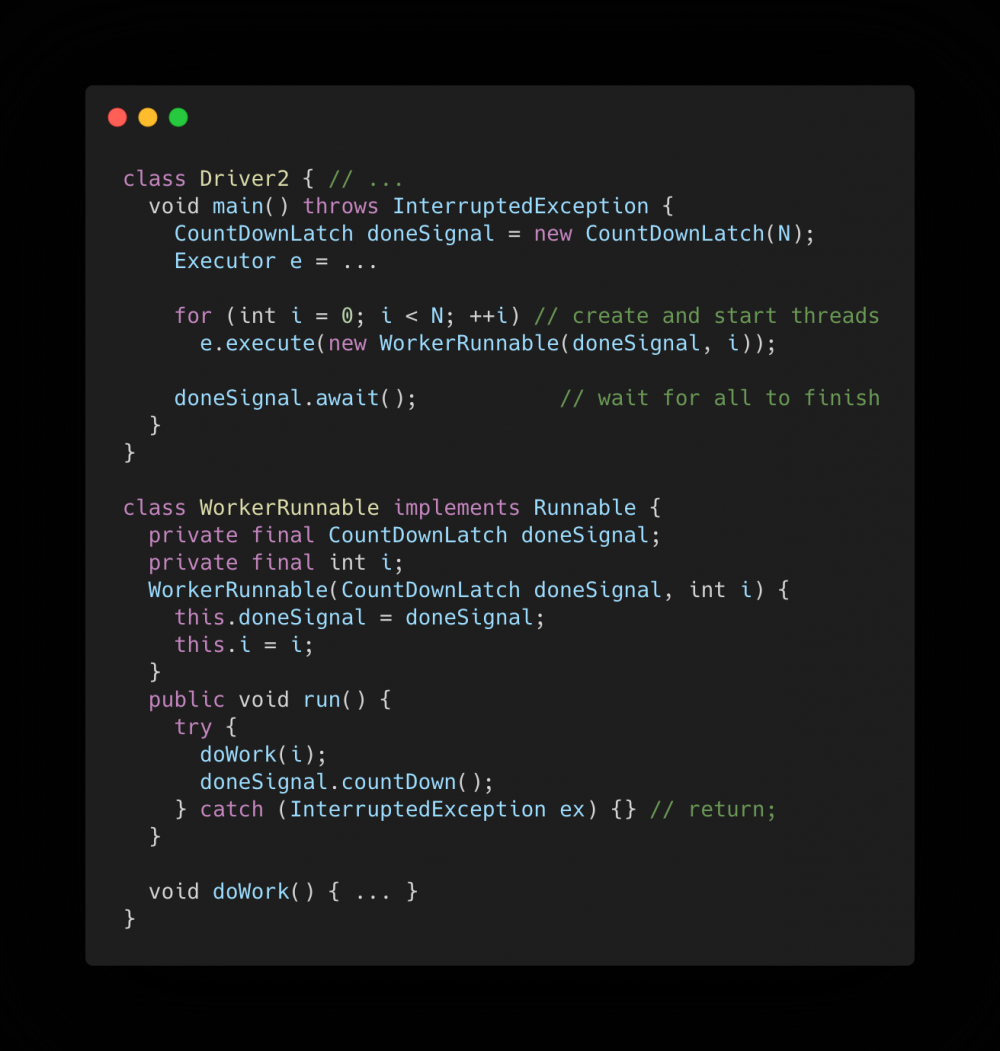
官网示例2
另一种典型的用法是将一个问题分成 N 个部分 (比如将一个大的 list 拆分成多分,每个 Worker 干一部分),Worker 执行完自己所处理的部分后,计数器减1,当所有子部分完成后,Driver 才继续向下执行
结合官网示例,相信你已经可以结合你自己的业务场景解,通过 CountDownLatch 解决一些串行瓶颈来提高运行效率了,会用还远远不够,咱得知道 CountDownLatch 的实现原理
源码分析
CountDownLatch 是 AQS 实现中的最后一个内容,有了前序文章的知识铺垫:
- Java AQS队列同步器以及ReentrantLock的应用
- Java AQS共享式获取同步状态及Semaphore的应用分析
当你看到 CountDownLatch 的源码内容,你会高兴的笑起来,内容真是太少了
展开类结构全部内容就这点东西
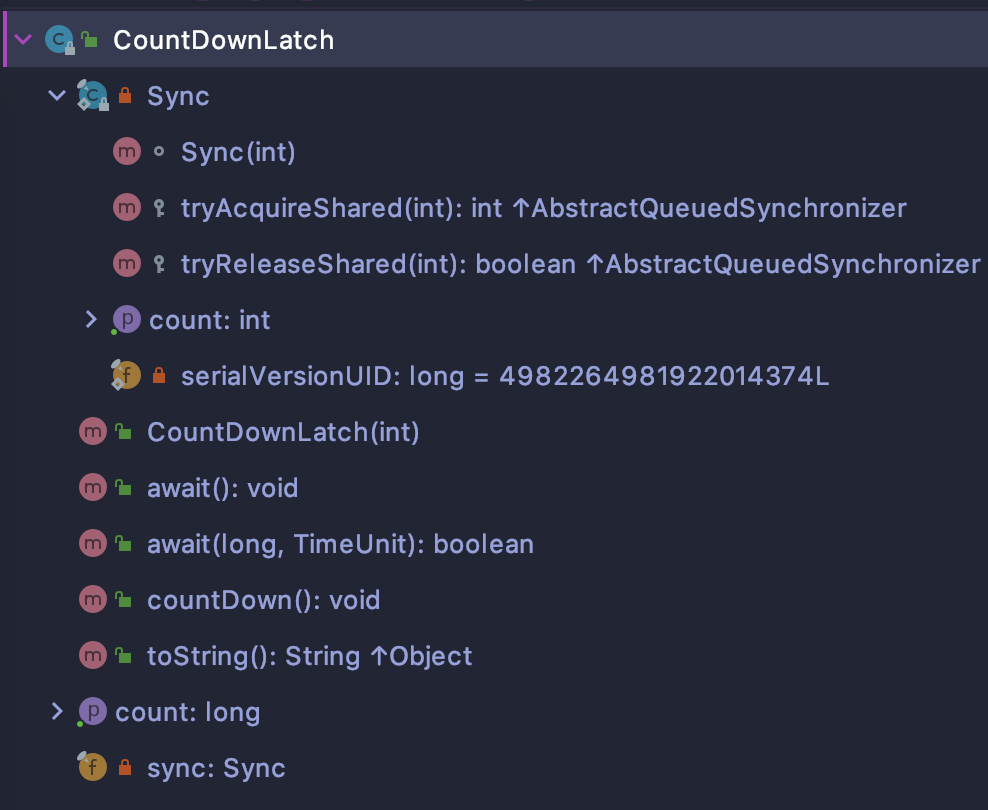
既然 CountDownLatch 是基于 AQS 实现的,那肯定也离不开对同步状态变量 state 的操作,我们在初始化的时候就将计数器的值赋值给了state
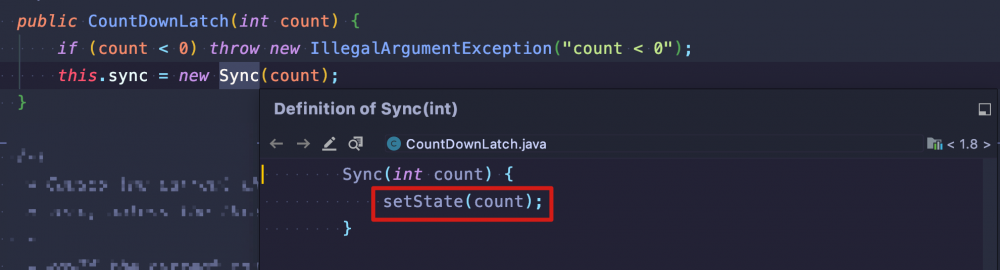
另外,它可以多个线程同时获取,那一定是基于共享式获取同步变量的用法了,所以它需要通过重写下面两个方法控制同步状态变量 state :
- tryAcquireShared()
- tryReleaseShared()
CountDownLatch 暴露给使用者的只有 await() 和 countDown() 两个方法,前者是阻塞自己,因为只有获取同步状态才会才会出现阻塞的情况,那自然是在 await() 的方法内部会用到 tryAcquireShared() ;有获取就要有释放,那后者 countDown() 方法内部自然是要用到 tryReleaseShared() 方法了
PS:如果你对上面这个很自然的推断理解有困难,强烈建议你看一下前序文章的铺垫,以防止知识断层带来的困扰
await()
先来看 await() 方法, 从方法签名上看,该方法会抛出 InterruptedException, 所以它是可以响应中断的,这个我们在Java多线程中断机制 中明确说明过
public void await() throws InterruptedException {
sync.acquireSharedInterruptibly(1);
}
其内部调用了同步器提供的模版方法 acquireSharedInterruptibly
public final void acquireSharedInterruptibly(int arg)
throws InterruptedException {
// 如果监测到中断标识为true,会重置标识,然后抛出 InterruptedException
if (Thread.interrupted())
throw new InterruptedException();
// 调用重写的 tryAcquireShared 方法,该方法结果如果大于零则直接返回,程序继续向下执行,如果小于零,则会阻塞自己
if (tryAcquireShared(arg) < 0)
// state不等于0,则尝试阻塞自己
doAcquireSharedInterruptibly(arg);
}
重写的 tryAcquireShared 方法非常简单, 就是判断同步状态变量 state 的值是否为 0, 如果为零 (子线程已经全部执行完毕)则返回1, 否则返回 -1
protected int tryAcquireShared(int acquires) {
return (getState() == 0) ? 1 : -1;
}
如果子线程没有全部执行完毕,则会通过 doAcquireSharedInterruptibly 方法阻塞自己,这个方法在 Java AQS共享式获取同步状态及Semaphore的应用分析 中已经仔细分析过了,这里就不再赘述了
private void doAcquireSharedInterruptibly(int arg)
throws InterruptedException {
final Node node = addWaiter(Node.SHARED);
boolean failed = true;
try {
for (;;) {
final Node p = node.predecessor();
if (p == head) {
// 再次尝试获取同步装阿嚏,如果大于0,说明子线程全部执行完毕,直接返回
int r = tryAcquireShared(arg);
if (r >= 0) {
setHeadAndPropagate(node, r);
p.next = null; // help GC
failed = false;
return;
}
}
// 阻塞自己
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
throw new InterruptedException();
}
} finally {
if (failed)
cancelAcquire(node);
}
}
await() 方法的实现就是这么简单,接下来看看 countDown() 的实现原理
countDown()
public void countDown() {
sync.releaseShared(1);
}
同样是调用同步器提供的模版方法 releaseShared
public final boolean releaseShared(int arg) {
// 调用自己重写的同步器方法
if (tryReleaseShared(arg)) {
// 唤醒调用 await() 被阻塞的线程
doReleaseShared();
return true;
}
return false;
}
重写的 tryReleaseShared 同样很简单
protected boolean tryReleaseShared(int releases) {
// Decrement count; signal when transition to zero
for (;;) {
int c = getState();
// 如果当前状态值为0,则直接返回 (1)
if (c == 0)
return false;
// 使用 CAS 让计数器的值减1 (2)
int nextc = c-1;
if (compareAndSetState(c, nextc))
return nextc == 0;
}
}
代码 (1) 判断当前同步状态值,如果为0 则直接返回 false;否则执行代码 (2),使用 CAS 将计数器减1,如果 CAS 失败,则循环重试,最终返回 nextc == 0 的结果值,如果该值返回 true,说明最后一个线程已调用 countDown() 方法,然后就要唤醒调用 await() 方法被阻塞的线程,同样由于分析过 AQS 的模版方法 doReleaseShared 整个释放同步状态以及唤醒的过程,所以这里同样不再赘述了
仔细看CountDownLatch重写的 tryReleaseShared 方法,有一点需要和大家说明:
代码 (1) if (c == 0) 看似没什么用处,其实用处大大滴,如果没有这个判断,当计数器值已经为零了,其他线程再调用 countDown 方法会将计数器值变为负值
现在就差 await(long timeout, TimeUnit unit) 方法没介绍了
await(long timeout, TimeUnit unit)
public boolean await(long timeout, TimeUnit unit)
throws InterruptedException {
return sync.tryAcquireSharedNanos(1, unit.toNanos(timeout));
}
该方法签名同样抛出 InterruptedException,意思可响应中断。它其实就是 await() 更完善的一个版本,简单来说就是
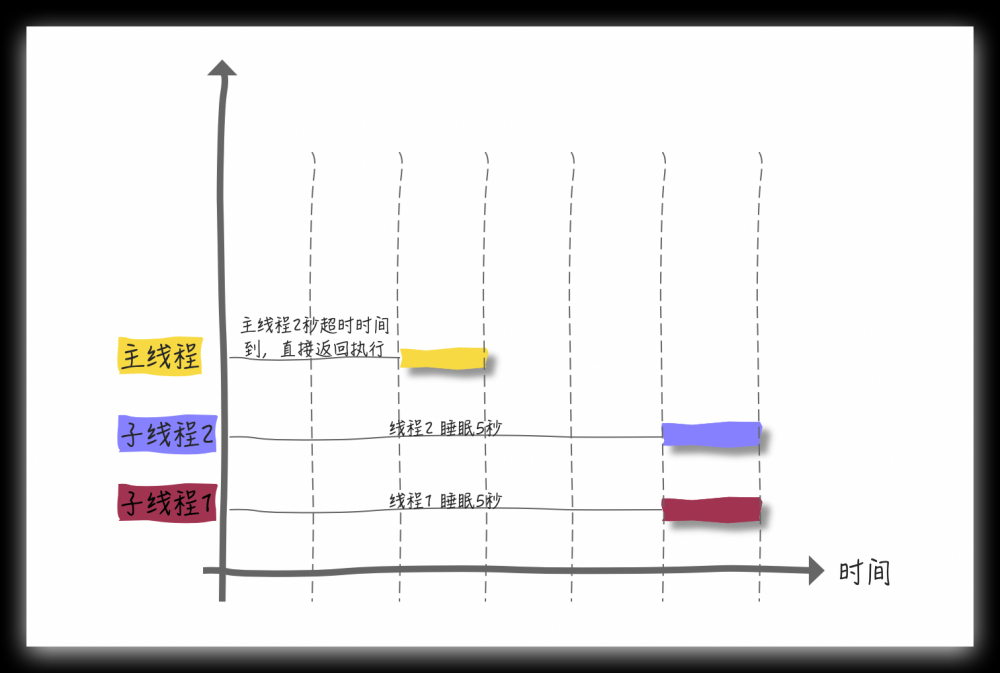
主线程设定等待超时时间,如果该时间内子线程没有执行完毕,主线程也会 直接返回
我们将上面的例子稍稍修改一下你就会明白(主线程超时时间设置为 2 秒,而子线程要 sleep 5 秒)
@Slf4j
public class CountDownLatchTimeoutExample {
private static CountDownLatch countDownLatch = new CountDownLatch(2);
public static void main(String[] args) throws InterruptedException {
// 这里不推荐这样创建线程池,最好通过 ThreadPoolExecutor 手动创建线程池
ExecutorService executorService = Executors.newFixedThreadPool(2);
executorService.submit(() -> {
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
log.info("Thread-1 执行完毕");
//计数器减1
countDownLatch.countDown();
}
});
executorService.submit(() -> {
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
log.info("Thread-2 执行完毕");
//计数器减1
countDownLatch.countDown();
}
});
log.info("主线程等待子线程执行完毕");
log.info("计数器值为:" + countDownLatch.getCount());
countDownLatch.await(2, TimeUnit.SECONDS);
log.info("计数器值为:" + countDownLatch.getCount());
log.info("主线程执行完毕");
executorService.shutdown();
}
}
运行结果如下:

形象化的展示上述示例的运行过程
小结
CountDownLatch 的实现原理就是这么简单,了解了整个实现过程后,你也许发现了使用 CountDownLatch 的一个问题:
计数器减 1 操作是 一次性 的,也就是说当计数器减到 0, 再有线程调用 await() 方法,该线程会直接通过, 不会再起到等待其他线程执行结果起到同步的作用了
为了解决这个问题,贴心的 Doug Lea 大师早已给我们准备好相应策略 CyclicBarrier

本来想将 CyclicBarrier 的内容放到下一个章节,但是 CountDownLatch 的内容着实有些少,不够解渴,另外有对比才有伤害,所以内容没结束,咱得继续看 CyclicBarrier )

CyclicBarrier
上面简单说了一下 CyclicBarrier 被创造出来的理由,这里先看一下它的字面解释:

概念总是有些抽象,我们将上面的例子用 CyclicBarrier 再做个改动,先让大家有个直观的使用概念
@Slf4j
public class CyclicBarrierExample {
// 创建 CyclicBarrier 实例,计数器的值设置为2
private static CyclicBarrier cyclicBarrier = new CyclicBarrier(2);
public static void main(String[] args) {
ExecutorService executorService = Executors.newFixedThreadPool(2);
int breakCount = 0;
// 将线程提交到线程池
executorService.submit(() -> {
try {
log.info(Thread.currentThread() + "第一回合");
Thread.sleep(1000);
cyclicBarrier.await();
log.info(Thread.currentThread() + "第二回合");
Thread.sleep(2000);
cyclicBarrier.await();
log.info(Thread.currentThread() + "第三回合");
} catch (InterruptedException | BrokenBarrierException e) {
e.printStackTrace();
}
});
executorService.submit(() -> {
try {
log.info(Thread.currentThread() + "第一回合");
Thread.sleep(2000);
cyclicBarrier.await();
log.info(Thread.currentThread() + "第二回合");
Thread.sleep(1000);
cyclicBarrier.await();
log.info(Thread.currentThread() + "第三回合");
} catch (InterruptedException | BrokenBarrierException e) {
e.printStackTrace();
}
});
executorService.shutdown();
}
}
运行结果:
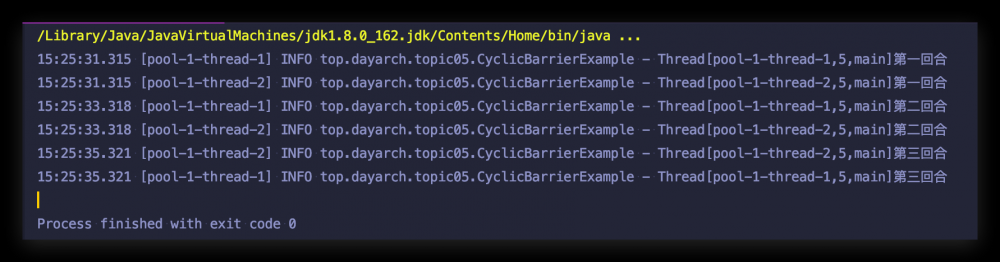
结合程序代码与运行结果,我们可以看出,子线程执行完第一回合后(执行回合所需时间不同),都会调用 await() 方法,等所有线程都到达屏障点后,会突破屏障继而执行第二回合,同样的道理最终到达第三回合
形象化的展示上述示例的运行过程

看到这里,你应该明白 CyclicBarrier 的基本用法,但随之你内心也应该有了一些疑问:
- 怎么判断所有线程都到达屏障点的?
- 突破某一屏障后,又是怎么重置 CyclicBarrier 计数器,等待线程再一次突破屏障呢?
带着这些问题我们来看一看源码
源码分析
同样先打开 CyclicBarrier 的类结构,展开类全部内容,其实也没多少内容
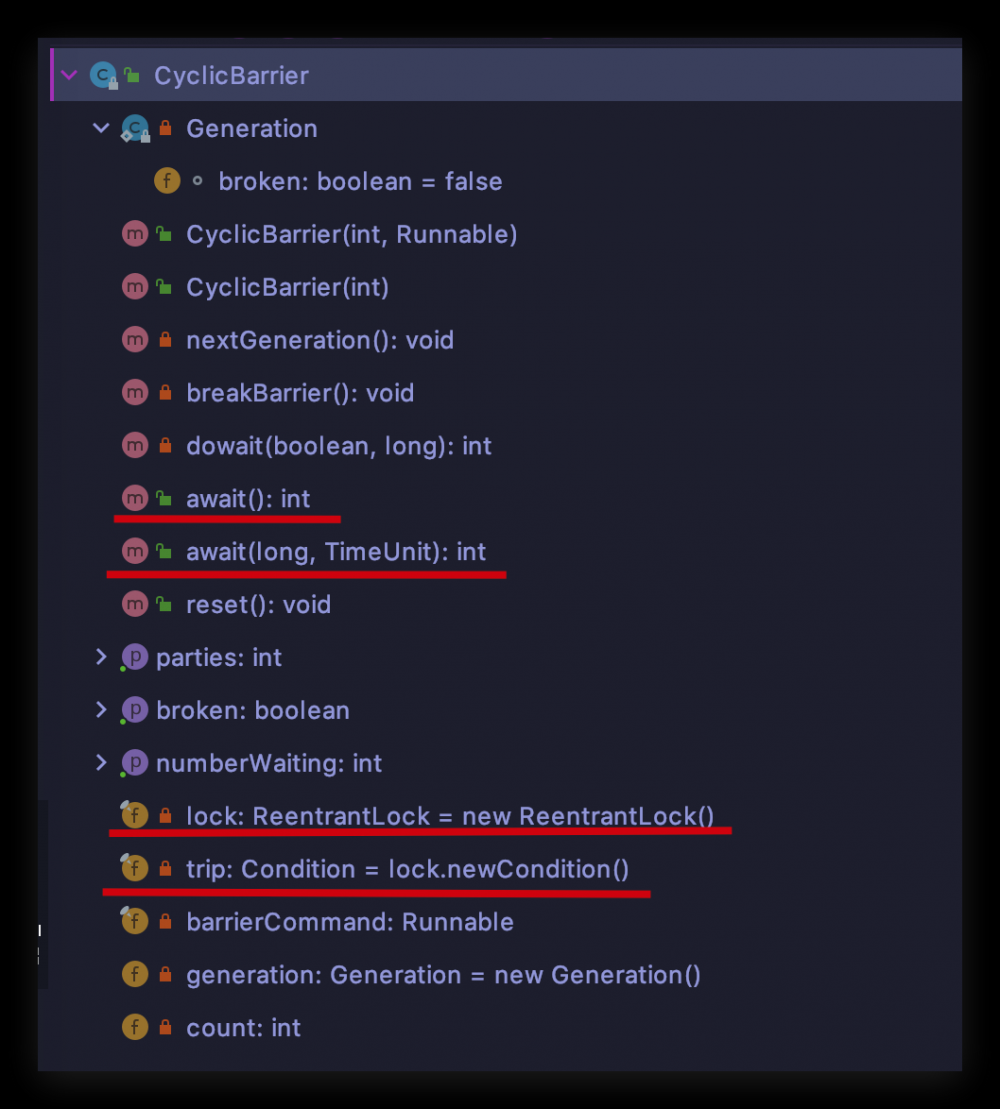
从类结构中看到有:
- await() 方法,猜测应该和 CountDownLatch 是类似的,都是获取同步状态,阻塞自己
- ReentrantLock,CyclicBarrier 内部竟然也用到了我们之前讲过的 ReentrantLock,猜测这个锁一定保护 CyclicBarrier 的某个变量,那肯定也是基于 AQS 相关知识了
- Condition,存在条件,猜测会有等待/通知机制的运用
我们继续带着这些猜测,结合上面的实例代码一点点来验证
// 创建 CyclicBarrier 实例,计数器的值设置为2 private static CyclicBarrier cyclicBarrier = new CyclicBarrier(2);
查看构造函数 (这里的英文注释舍不得删掉,因为说的太清楚了,我来结合注释来说明一下):
private final int parties;
private int count;
public CyclicBarrier(int parties) {
this(parties, null);
}
/**
* Creates a new {@code CyclicBarrier} that will trip when the
* given number of parties (threads) are waiting upon it, and which
* will execute the given barrier action when the barrier is tripped,
* performed by the last thread entering the barrier.
*
* @param parties the number of threads that must invoke {@link #await}
* before the barrier is tripped
* @param barrierAction the command to execute when the barrier is
* tripped, or {@code null} if there is no action
* @throws IllegalArgumentException if {@code parties} is less than 1
*/
public CyclicBarrier(int parties, Runnable barrierAction) {
if (parties <= 0) throw new IllegalArgumentException();
this.parties = parties;
this.count = parties;
this.barrierCommand = barrierAction;
}
根据注释说明,parties 代表冲破屏障之前要触发的线程总数,count 本身又是计数器,那问题来了
直接就用 count 不就可以了嘛?为啥同样用于初始化计数器,要维护两个变量呢?
从 parties 和 count 的变量声明中,你也能看出一些门道,前者有 final 修饰,初始化后就不可以改变了,因为 CyclicBarrier 的设计目的是可以循环利用的,所以始终用 parties 来记录线程总数,当 count 计数器变为 0 后,如果没有 parties 的值赋给它,怎么进行重新复用再次计数呢,所以这里维护两个变量很有必要
接下来就看看 await() 到底是怎么实现的
// 从方法签名上可以看出,该方法同样可以被中断,另外还有一个 BrokenBarrierException 异常,我们一会看
public int await() throws InterruptedException, BrokenBarrierException {
try {
// 调用内部 dowait 方法, 第一个参数为 false,表示不设置超时时间,第二个参数也就没了意义
return dowait(false, 0L);
} catch (TimeoutException toe) {
throw new Error(toe); // cannot happen
}
}
接下来看看 dowait(false, 0L) 做了哪些事情 (这个方法内容有点多,别担心,逻辑并不复杂,请看关键代码注释)
private int dowait(boolean timed, long nanos)
throws InterruptedException, BrokenBarrierException,
TimeoutException {
final ReentrantLock lock = this.lock;
// 还记得之前说过的 Lock 标准范式吗? JDK 内部都是这么使用的,你一定也要遵循范式
lock.lock();
try {
final Generation g = generation;
// broken 是静态内部类 Generation唯一的一个成员变量,用于记录当前屏障是否被打破,如果打破,则抛出 BrokenBarrierException 异常
// 这里感觉挺困惑的,我们要【冲破】屏障,这里【打破】屏障却抛出异常,注意我这里的用词
if (g.broken)
throw new BrokenBarrierException();
// 如果线程被中断,则会通过 breakBarrier 方法将 broken 设置为true,也就是说,如果有线程收到中断通知,直接就打破屏障,停止 CyclicBarrier, 并唤醒所有线程
if (Thread.interrupted()) {
breakBarrier();
throw new InterruptedException();
}
// ************************************
// 因为 breakBarrier 方法在这里会被调用多次,为了便于大家理解,我直接将 breakBarrier 代码插入到这里
private void breakBarrier() {
// 将打破屏障标识 设置为 true
generation.broken = true;
// 重置计数器
count = parties;
// 唤醒所有等待的线程
trip.signalAll();
}
// ************************************
// 每当一个线程调用 await 方法,计数器 count 就会减1
int index = --count;
// 当 count 值减到 0 时,说明这是最后一个调用 await() 的子线程,则会突破屏障
if (index == 0) { // tripped
boolean ranAction = false;
try {
// 获取构造函数中的 barrierCommand,如果有值,则运行该方法
final Runnable command = barrierCommand;
if (command != null)
command.run();
ranAction = true;
// 激活其他因调用 await 方法而被阻塞的线程,并重置 CyclicBarrier
nextGeneration();
// ************************************
// 为了便于大家理解,我直接将 nextGeneration 实现插入到这里
private void nextGeneration() {
// signal completion of last generation
trip.signalAll();
// set up next generation
count = parties;
generation = new Generation();
}
// ************************************
return 0;
} finally {
if (!ranAction)
breakBarrier();
}
}
// index 不等于0, 说明当前不是最后一个线程调用 await 方法
// loop until tripped, broken, interrupted, or timed out
for (;;) {
try {
// 没有设置超时时间
if (!timed)
// 进入条件等待
trip.await();
else if (nanos > 0L)
// 否则,判断超时时间,这个我们在 AQS 中有说明过,包括为什么最后超时阈值 spinForTimeoutThreshold 不再比较的原因,大家会看就好
nanos = trip.awaitNanos(nanos);
} catch (InterruptedException ie) {
// 条件等待被中断,则判断是否有其他线程已经使屏障破坏。若没有则进行屏障破坏处理,并抛出异常;否则再次中断当前线程
if (g == generation && ! g.broken) {
breakBarrier();
throw ie;
} else {
Thread.currentThread().interrupt();
}
}
if (g.broken)
throw new BrokenBarrierException();
// 如果新一轮回环结束,会通过 nextGeneration 方法新建 generation 对象
if (g != generation)
return index;
if (timed && nanos <= 0L) {
breakBarrier();
throw new TimeoutException();
}
}
} finally {
lock.unlock();
}
}
doWait 就是 CyclicBarrier 的核心逻辑, 可以看出,该方法入口使用了 ReentrantLock,这也就是为什么 Generation broken 变量没有被声明为 volatile 类型保持可见性,因为对其的更改都是在锁的内部,同样在锁的内部对计数器 count 做更新,也保证了原子性
doWait 方法中,是通过 nextGeneration 方法来重新初始化/重置 CyclicBarrier 状态的,该类中还有一个 reset() 方法,也是重置 CyclicBarrier 状态的
public void reset() {
final ReentrantLock lock = this.lock;
lock.lock();
try {
breakBarrier(); // break the current generation
nextGeneration(); // start a new generation
} finally {
lock.unlock();
}
}
但 reset() 方法并没有在 CyclicBarrier 内部被调用,显然是给 CyclicBarrier 使用者来调用的,那问题来了
什么时候调用 reset() 方法呢
正常情况下,CyclicBarrier 是会被自动重置状态的,从 reset 的方法实现中可以看出调用了 breakBarrier
方法,也就是说,调用 reset 会使当前处在等待中的线程最终抛出 BrokenBarrierException 并立即被唤醒,所以说 reset() 只会在你想打破屏障时才会使用

上述示例,我们构建 CyclicBarrier 对象时,并没有传递 barrierCommand 对象, 我们修改示例传入一个 barrierCommand 对象,看看会有什么结果:
// 创建 CyclicBarrier 实例,计数器的值设置为2
private static CyclicBarrier cyclicBarrier = new CyclicBarrier(2, () -> {
log.info("全部运行结束");
});
运行结果:
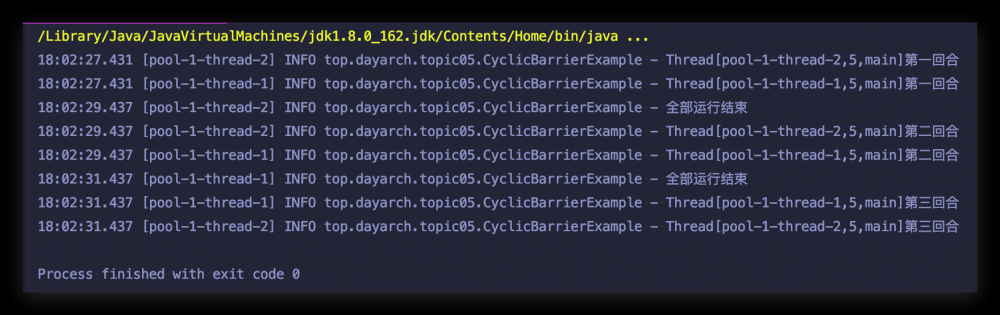
从运行结果中来看,每次冲破屏障后都会执行 CyclicBarrier 初始化 barrierCommand 的方法, 这与我们对 doWait() 方法的分析完全吻合,从上面的运行结果中可以看出,最后一个线程是运行 barrierCommand run() 方法的线程,我们再来形象化的展示一下整个过程
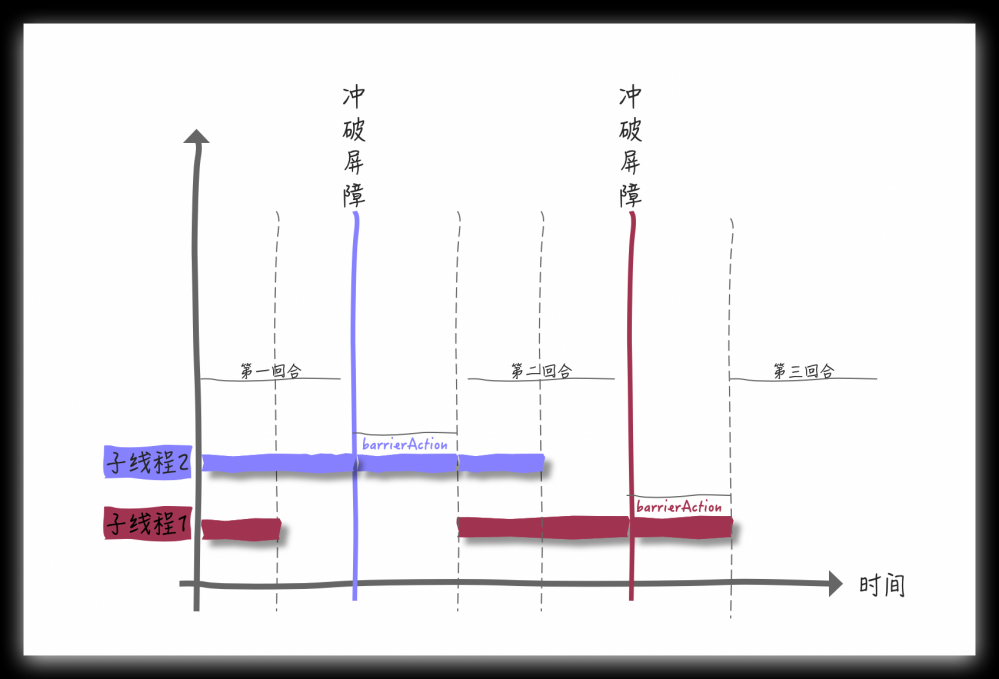
从上图可以看出,barrierAction 与每次突破屏障是串行化的执行过程,假如 barrierAction 是很耗时的汇总操作,那这就是可以优化的点了,我们继续修改代码
// 创建单线程线程池
private static Executor executor = Executors.newSingleThreadExecutor();
// 创建 CyclicBarrier 实例,计数器的值设置为2
private static CyclicBarrier cyclicBarrier = new CyclicBarrier(2, () -> {
executor.execute(() -> gather());
});
private static void gather() {
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
log.info("全部运行结束");
}
我们这里将 CyclicBarrier 的回调函数 barrierAction使用单线程的线程池,这样最后一个冲破屏障的线程就不用等待 barrierAction 的执行,直接分配个线程池里的线程异步执行,进一步提升效率
运行结果如下:
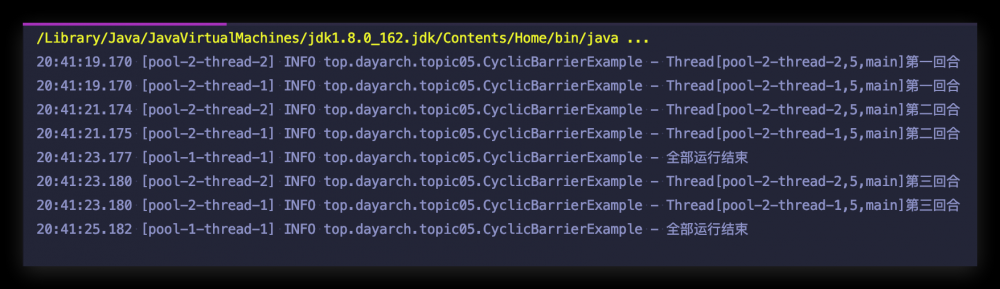
我们再形象化的看一下整个过程:
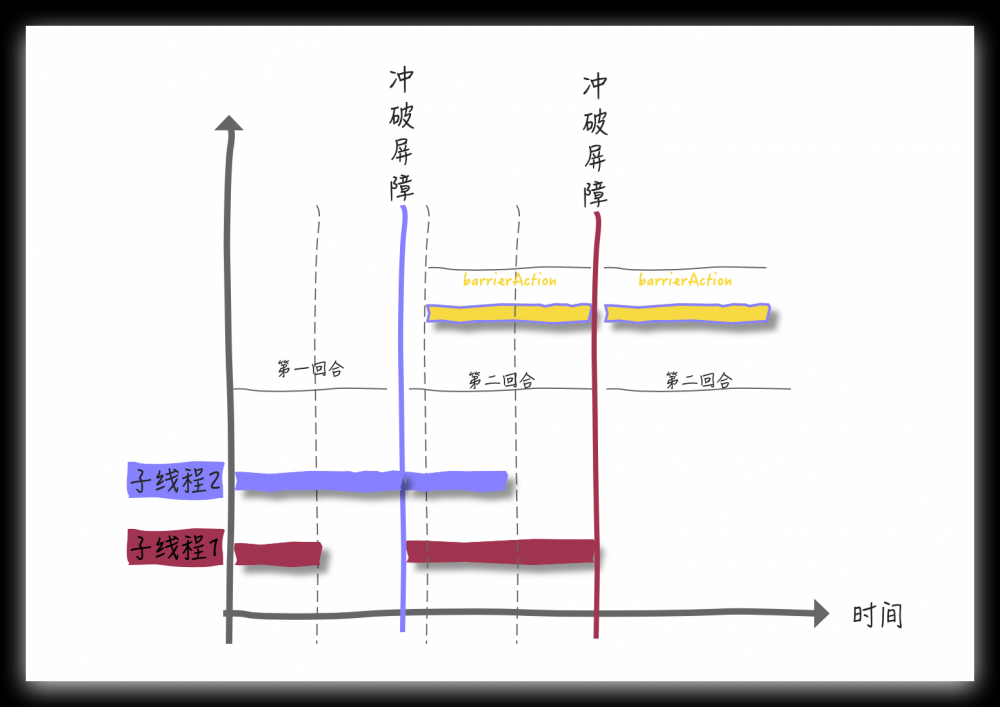
这里使用了单一线程池,增加了并行操作,提高了程序运行效率,那问题来了:
如果 barrierAction 非常非常耗时,冲破屏障的任务就可能堆积在单一线程池的等待队列中,就存在 OOM 的风险,那怎么办呢?
这是就要需要一定的限流策略或者使用线程池的拒绝的略等
那把单一线程池换成非单一的固定线程池不就可以了嘛?比如 fixed(5)
乍一看确实能缓解单线程池可能引起的任务堆积问题,上面代码我们看到的 gather() 方法,假如该方法内部没有使用锁或者说存在竟态条件,那 CyclicBarrier 的回调函数 barrierAction 使用多线程必定引起结果的不准确
所以在实际使用中还要结合具体的业务场景不断优化代码,使之更加健壮
总结
本文讲解了 CountDownLatch 和 CyclicBarrier 的经典使用场景以及实现原理,以及在使用过程中可能会遇到的问题,比如将大的 list 拆分作业就可以用到前者,读取多个 Excel 的sheet 页,最后进行结果汇总就可以用到后者 (文中完整示例代码已上传)
最后,再形象化的比喻一下
- CountDownLatch 主要用来解决一个线程等待多个线程的场景,可以类比旅游团团长要等待所有游客到齐才能去下一个景点
- 而 CyclicBarrier 是一组线程之间的相互等待,可以类比几个驴友之间的不离不弃,共同到达某个地方,再继续出发,这样反复
灵魂追问
- 怎样拿到 CyclicBarrier 的汇总结果呢?
- 线程池中的 Future 特性你有使用过吗?
接下来,咱们就聊聊那些可以使用的 Future 特性
正文到此结束
- 本文标签: final 线程池 CountDownLatch 时间 参数 源码 example cat executor Semaphore HTML 锁 突破 文章 JVM 代码 list java ThreadPoolExecutor 线程 ORM CyclicBarrier App volatile https ACE id 多线程 Excel 同步 Oracle Service 并发 灵魂 并发编程 ip http UI IO 实例 总结 tar Action 限流 注释 开发 node src map 图片 代码注释
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

