架构设计(12) --分布式链路跟踪:Zipkin实践
我们最近升级改造我们链路跟踪系统Log2,然后我们花了将近一周时间调研不少开源的链路跟踪系统,在此调研过程中,做了一些笔记和总结,若有误请指教。
一、Zipkin是什么
《架构设计(12) 分布式链路跟踪》提到, Google的Dapper论文,介绍了如何进行服务追踪分析。其 基本思路 是在服务调用的请求和响应中加入ID,标明上下游请求的关系。利用这些信息,可以可视化地分析服务调用链路和服务间的依赖关系。
Zipkin 是基于 Dapper 论文实现,由Twitter公司开发并开源一个分布式的跟踪系统。 Zipkin 支持多种语言包括JavaScript,Python,Java, Scala, Ruby, C#, Go等。其中Java由多种不同的库来支持。
官网: https://github.com/openzipkin/zipkin/
二、Zipkin基本概念
1、trace:请求跟踪树
Zipkin使用Trace结构表示一次请求的跟踪,从请求到达跟踪系统的边界开始,到被跟踪系统返回响应为止的过程。一次请求可能由后台的若干服务负责处理,每个服务的处理是一个Span,Span之间有依赖关系,Trace就是树结构的Span集合;.包含一系列的span,它们组成了一个树型结构.
2、span:服务跟踪记录
每个 trace中会调用若干个服务,为了记录调用了哪些服务,以及每次调用的消耗时间等信息,在每次调用服务时,埋入一个调用记录,称为一个“span”。
span是基本的工作单元,包含了一些描述信息:id,parentId,name,timestamp,duration,annotations等
最开始的初始Span称为根span,此span中span id和 trace id值相同。
3、annotations标注:标注时间点发生的Event
标注用于及时记录事件;有一组核心注释用于定义RPC请求的开始和结束;
- cs:Client Send,客户端发起请求;
- sr:Server Receive,服务器接受请求,开始处理;
- ss:Server Send,服务器完成处理,给客户端应答;
- cr:Client Receive,客户端接受应答从服务器;
4、binaryAnnotations额外信息
旨在提供有关RPC的额外信息,可以存放用户自定义信息,比如:sessionID、userID、userIP、异常等。
trace信息例子
一个完成trace信息如下:
traceId:标记一次请求的跟踪,相关的Spans都有相同的traceId;
id:span id;
name:span的名称,一般是接口方法的名称;
parentId:可选的id,当前Span的父Span id,通过parentId来保证Span之间的依赖关系,如果没有parentId,表示当前Span为根Span;
timestamp:Span创建时的时间戳,使用的单位是微秒(而不是毫秒),所有时间戳都有错误,包括主机之间的时钟偏差以及时间服务重新设置时钟的可能性,出于这个原因,Span应尽可能记录其duration;
duration:持续时间使用的单位是微秒(而不是毫秒);
{
"traceId": "423f62ed10f826bd",
"id": "09d324b8d0563b0c",
"name": "http:/hello",
"parentId": "423f62ed10f826bd",
"timestamp": 1593490361270000,
"duration": 19000,
"annotations": [
{
"timestamp": 1593490361270000,
"value": "cs",
"endpoint": {
"serviceName": "zipkin-client",
"port": 8080
}
},
{
"timestamp": 1593490361278000,
"value": "sr",
"endpoint": {
"serviceName": "zipkin-service",
"port": 9081
}
},
{
"timestamp": 1593490361289000,
"value": "cr",
"endpoint": {
"serviceName": "zipkin-client",
"port": 8080
}
},
{
"timestamp": 1593490361290000,
"value": "ss",
"endpoint": {
"serviceName": "zipkin-service",
"port": 9081
}
}
],
"binaryAnnotations": [
{
"key": "http.host",
"value": "localhost",
"endpoint": {
"serviceName": "zipkin-client",
"port": 8080
}
},
{
"key": "http.method",
"value": "GET",
"endpoint": {
"serviceName": "zipkin-client",
"port": 8080
}
}
]
}
三、Zipkin架构和原理
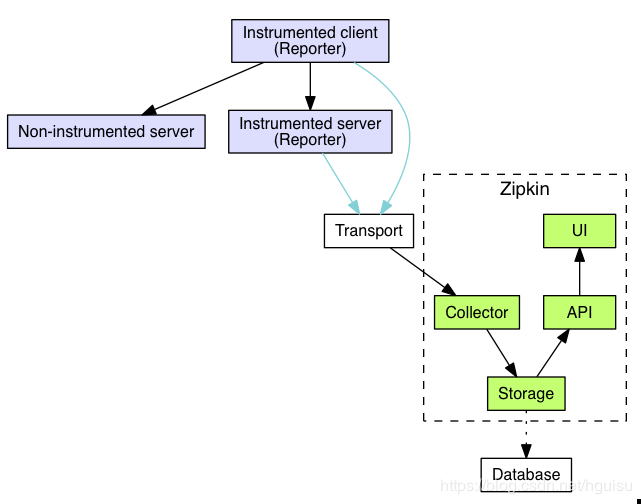
1、Zipkin 架构
跟踪器(Tracer):位于你的应用程序中,并记录发生的操作的时间和元数据,提供了相应的类库,对用户的使用来说是透明的,收集的跟踪数据称为Span;
报告器 (Reporter):将跟踪数据发送到Zipkin server的应用程序组件称为Reporter. 比如通过MQ发送,即MQ为reporter,或者跟踪数据先落地,通过logstash发送,logstash为reporter。
Transport传输:Reporter通过几种传输方式之一将追踪数据发送到Zipkin收集器(collector),有三个主要的传输方式:HTTP, Kafka和Scribe;
Zipkin server:collector收到数据后将跟踪数据进行存储(storage),由API查询存储以向UI提供数据。
Zipkin server有4个组件组成:collector,storage,search,web UI
collector:一旦跟踪数据到达Zipkin collector守护进程,它将被验证,存储和索引,以供Zipkin收集器查找;
storage:Zipkin最初数据存储在Cassandra上,因为Cassandra是可扩展的,具有灵活的模式,并在Twitter中大量使用;但是这个组件可插入,除了Cassandra之外,还支持ElasticSearch和MySQL; 存储,zipkin默认的存储方式为in-memory,即不会进行持久化操作。如果想进行收集数据的持久化,可以存储数据在Cassandra,因为Cassandra是可扩展的,有一个灵活的模式,并且在Twitter中被大量使用,我们使这个组件可插入。除了Cassandra,我们原生支持ElasticSearch和MySQL。其他后端可能作为第三方扩展提供。
search:一旦数据被存储和索引,我们需要一种方法来提取它。查询守护进程提供了一个简单的JSON API来查找和检索跟踪,主要给Web UI使用;
web UI:创建了一个GUI,为查看痕迹提供了一个很好的界面;Web UI提供了一种基于服务,时间和注释查看跟踪的方法。
架构图如下:
2、Zipkin工作流程:
一个应用的代码发起HTTP get请求,经过Trace框架拦截,然后
1)、把当前调用链的Trace信息添加到HTTP Header里面
2)、记录当前调用的时间戳
3)、发送HTTP请求,把trace相关的header信息携带上
4)、调用结束之后,记录当前调用耗时
5)、然后把上面流程产生的 信息汇集成一个span,把这个span信息上传到zipkin的Collector模块
该信息来源:https://www.jianshu.com/p/d75226c8f943
┌─────────────┐ ┌───────────────────────┐ ┌─────────────┐ ┌──────────────────┐
│ User Code │ │ Trace Instrumentation │ │ Http Client │ │ Zipkin Collector │
└─────────────┘ └───────────────────────┘ └─────────────┘ └──────────────────┘
│ │ │ │
┌─────────┐
│ ──┤GET /foo ├─▶ │ ────┐ │ │
└─────────┘ │ record tags
│ │ ◀───┘ │ │
────┐
│ │ │ add trace headers │ │
◀───┘
│ │ ────┐ │ │
│ record timestamp
│ │ ◀───┘ │ │
┌─────────────────┐
│ │ ──┤GET /foo ├─▶ │ │
│X-B3-TraceId: aa │ ────┐
│ │ │X-B3-SpanId: 6b │ │ │ │
└─────────────────┘ │ invoke
│ │ │ │ request │
│
│ │ │ │ │
┌────────┐ ◀───┘
│ │ ◀─────┤200 OK ├─────── │ │
────┐ └────────┘
│ │ │ record duration │ │
┌────────┐ ◀───┘
│ ◀──┤200 OK ├── │ │ │
└────────┘ ┌────────────────────────────────┐
│ │ ──┤ asynchronously report span ├────▶ │
│ │
│{ │
│ "traceId": "aa", │
│ "id": "6b", │
│ "name": "get", │
│ "timestamp": 1483945573944000,│
│ "duration": 386000, │
│ "annotations": [ │
│--snip-- │
└────────────────────────────────┘
四、JAVA相关采集插件。
1、brave则是zipkin官方出品的Java语言的链路数据采集插件:官方提供的brave插件列表非常多,基本上涵盖了日常用到的链路:http、rpc、db等。
2、spring cloud提供了spring-cloud-sleuth-zipkin来方便集成zipkin实现zipkin client追踪器,该jar包可以通过spring-cloud-starter-zipkin依赖来引入。 Spring Cloud Sleuth是 采集应用Span、Trace等信息,通过HTTP Request,向Zipkin Server发送采集信息等全部自动完成。
五、zipkin结合spring-cloud-sleuth使用
我们新建三个项目。一个zipkinServer。另外两个是普通的业务应用,分别叫service和client。
zipkinServer功能SHI 收集调用数据,并展示;
service对外暴露接口;
client : 调用service接口;
1、zipkin server应用
Zipkin的使用比较简单,官网有说明几种方式:
1、容器 :Docker Zipkin 项目能够建立 docker 镜像,提供脚本和 docker-compose.yml 来启动预构建的图像。最快的开始是直接运行最新镜像:
docker run -d -p 9411:9411 openzipkin/zipkin
2、下载jar :最快的方法是下载一个zipkinserver.xx.jar并运行, 详情参看
3、使用源码代码运行
1)、新建Spring Boot项目,工程取名为zipkin-server,在其pom引入依赖:
spring boot 版本:
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.4.3.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
spirng cloud 版本:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Camden.SR4</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
我们使用spirng cloud 版本:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<!-- spring boot -->
<!--<parent>-->
<!--<groupId>org.springframework.boot</groupId>-->
<!--<artifactId>spring-boot-starter-parent</artifactId>-->
<!--<version>1.4.3.RELEASE</version>-->
<!--</parent>-->
<groupId>com.demo.zipkin</groupId>
<artifactId>demo-zipkin-server</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<name>demo-zipkin-server</name>
<description>zipkin-server project for Spring Boot</description>
<properties>
<!--设置字符编码及java版本 -->
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<java.version>1.8</java.version>
<log4j2.version>2.7</log4j2.version>
</properties>
<!--依赖管理,用于管理spring-cloud的依赖 -->
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Camden.SR4</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<!--增加zipkin的依赖 -->
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-server</artifactId>
</dependency>
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-autoconfigure-ui</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
2)、在其程序入口类, 加上注解@EnableZipkinServer,开启ZipkinServer的功能:
package com.demo.zipkin.web;
/**
* Created by huangguisu on 2019/10/28.
*/
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.ImportResource;
import zipkin.server.EnableZipkinServer;
@SpringBootApplication
@EnableZipkinServer
@ImportResource(locations = {"classpath:applicationContext.xml"})
public class ZipkinServerApplication {
public static void main(String[] args) throws Exception {
SpringApplication.run(ZipkinServerApplication.class, args);
}
}
3)、在配置文件application.yml指定,配置Zipkin服务端口、名称等:
server.port=9411
spring.application.name=demo-zipkin-server
如果启动报错:
Exception in thread "main" java.lang.AbstractMethodError: org.springframework.boot.context.config.ConfigFileApplicationListener.supportsSourceType(Ljava/lang/Class;)Z
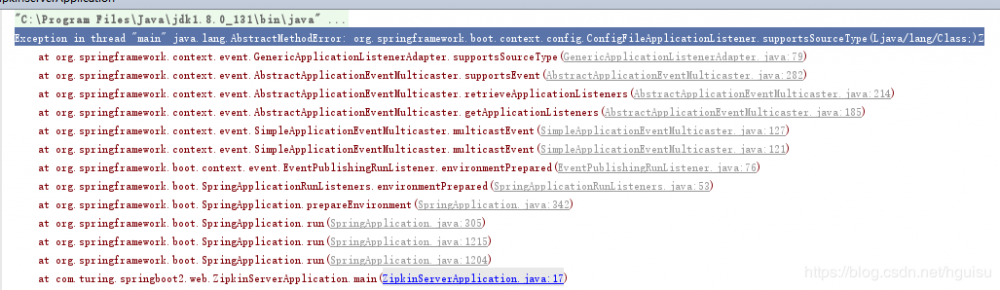
工程里面的pom.xml文件竟然添加了 spring-boot-starter-parent 依赖,已经做了如下配置:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-parent</artifactId>
<version>Brixton.SR3</version> <!--官网为Angel.SR4版本,但是我使用的时候总是报错 -->
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
如果再添加上述依赖的话就会造成版本冲突,产生错误。
4)访问 http://localhost:9411/ :
2、zipkin clint和service
1)、增加依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
2)、client的application.properties设置zipkin server
server.port=8080 server.address=0.0.0.0 spring.application.name=zipkin-client spring.zipkin.base-url=http://localhost:9411 spring.sleuth.sampler.percentage=1
3)client启动代码:
package com.demo.zipkin.web;
/**
* Created by huangguisu on 2019/10/28.
*/
import org.springframework.boot.SpringApplication;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.web.client.RestTemplate;
import org.springframework.context.annotation.Bean;
@RestController
@SpringBootApplication
public class ClientApplication {
// @Autowired
// RestTemplate restTemplate;
@Bean
RestTemplate restTemplate(){
return new RestTemplate();
}
@GetMapping("/hello")
public String hello(){
return this.restTemplate().getForEntity("http://localhost:9081/hello",String.class).getBody();
}
public static void main(String[] args) {
SpringApplication.run(ClientApplication.class, args);
}
}
4)service的application.properties设置zipkin server
server.port=9081 server.address=0.0.0.0 spring.application.name=zipkin-client spring.zipkin.base-url=http://localhost:9411 spring.sleuth.sampler.percentage=1
5)service启动代码:
package com.demo.zipkin.web;
/**
* Created by huangguisu on 2019/10/28.
*/
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.ImportResource;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.bind.annotation.GetMapping;
@SpringBootApplication
@RestController
@ImportResource(locations = {"classpath:applicationContext.xml"})
public class SerivceApplication {
@GetMapping("/hello")
public String hello(){
return "Hello World";
}
public static void main(String[] args) throws Exception {
SpringApplication.run(SerivceApplication.class, args);
}
}
然后我们启动client和service后,访问: http://localhost:8080/hello

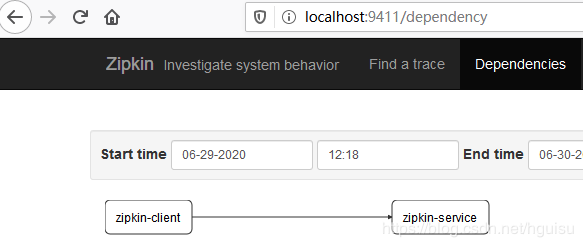
3、查看依赖:
可以看到如下依赖关系:
spring-cloud-sleuth收集信息是有一定的比率的,默认的采样率是0.1.可能在刚刚启动时候,看不到数据。
配置此值的方式在配置文件中增加spring.sleuth.sampler.percentage参数配置(如果不配置默认0.1),如果我们调大此值为1,可以看到信息收集就更及时。
如果spring.sleuth.sampler.percentage是1,由于采样频率过高,如果一次请求的链路有5个,那就需要5次http请求zipkin server,这种方式追踪服务调用链路会给我们业务程序性能带来一定的影响。
#sleuth采样率,默认为0.1,值越大收集越及时,但性能影响也越大
spring.sleuth.sampler.percentage=1
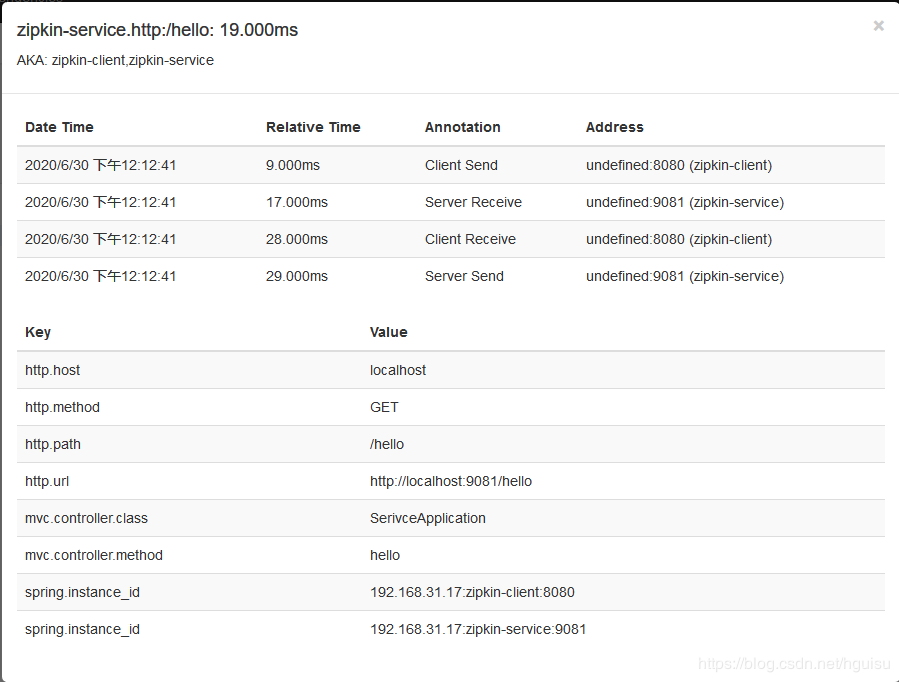
span细节指标展示:
使用默认zipkin方式的问题:
问题1:zipkin客户端向zipkin-server程序发送数据使用的是http的方式通信,每次发送的时候涉及到连接和发送过程。
问题2:当我们的zipkin-server程序关闭或者重启过程中,因为客户端收集信息的发送采用http的方式会被丢失。
针对以上两个问题,可以改进的办法是:
1、通信采用socket或者其他效率更高的通信方式。
2、客户端数据的发送尽量减少业务线程的时间消耗,采用异步等方式发送收集信息。
3、客户端与zipkin-server之间增加缓存类的中间件,例如redis、MQ等,在zipkin-server程序挂掉或重启过程中,客户端依旧可以正常的发送自己收集的信息。
相信采用以上三种方式会很大的提高我们的效率和可靠性。其实spring-cloud已经为我们提供采用MQ或redis等其他的采用socket方式通信,利用消息中间件或数据库缓存的实现方式。
4、spring-cloud-sleuth配置说明
这些配置跟版本有关,仅作参考:
spring.zipkin.base-url: http://192.168.84.146:9411/ #指定zipkin的服务器
#默认的service name是读取spring.application.name的值.
spring.zipkin.service.name=service1
#支持通过服务发现定位主机名
spring.zipkin.locator.discovery.enabled: true
#支持压缩的能力。默认是false。开启压缩,这样在发送给zipkin server之前会先把数据进行压缩
spring.zipkin.compression.enabled=true
#spring2.0以上 0.1-1.0 1=100%即集服务的全部追踪数据
spring.zipkin.sleuth.sampler.probability: 1.0
#spring2.0以下 0.1-1.0 1=100%即采集服务的全部追踪数据
spring.zipkin.sleuth.percentage: 1
spring.zipkin.sleuth.stream.enabled: true
#Spring Cloud Sleuth本身就整合了Spring Integration。它发布/订阅事件都是会创建span。可以设置spring.sleuth.integration.enabled=false来禁用这个机制
spring.zipkin.sleuth.stream.integration.enabled: false
#如果不需要跟踪某些@Scheduled,可以在spring.sleuth.scheduled.skipPattern设置一些正则表达式来过滤一些class。
spring.zipkin.sleuth.scheduled.skip-pattern: "^(org.*HystrixStreamTask|com.*ServiceAuthUtil*|com.*DBAuthClientService)$"
#web开启sleuth功能
spring.zipkin.sleuth.web.client.enabled: true
#uri在这个里面配置了,那么就不会上报到zipkin, 每个uri中间 |分割
spring.zipkin.sleuth.web.client.skip-pattern: "/hystrix.stream"
六、dubbo使用brave
1、添加brave依赖
<!-- dubbo插件 -->
<dependency>
<groupid>io.zipkin.brave</groupid>
<artifactid>brave-instrumentation-dubbo-rpc</artifactid>
</dependency>
2、设置brave dubbo filter
brave dubbo filter添加到dubbo的filter链中:
- 方法1:在application.properties文件中添加两行配置:
dubbo.consumer.filter=tracing dubbo.provider.filter=tracing
- 方法2:在dubbo xml配置文件中添加配置
<dubbo:consumer filter="tracing" /> <dubbo:provider filter="tracing" />
7、brave相关依赖包
使用到的brave依赖
<!-- 核心依赖 -->
<dependency>
<groupid>io.zipkin.brave</groupid>
<artifactid>brave</artifactid>
</dependency>
<!-- reporter -->
<dependency>
<groupid>io.zipkin.reporter2</groupid>
<artifactid>zipkin-sender-okhttp3</artifactid>
</dependency>
<dependency>
<groupid>io.zipkin.reporter2</groupid>
<artifactid>zipkin-sender-kafka</artifactid>
</dependency>
<!-- 日志依赖 -->
<!-- Integrates so you can use log patterns like %X{traceId}/%X{spanId} -->
<dependency>
<groupid>io.zipkin.brave</groupid>
<artifactid>brave-context-slf4j</artifactid>
</dependency>
<!-- spring mvc项目支持 -->
<dependency>
<groupid>io.zipkin.brave</groupid>
<artifactid>brave-spring-beans</artifactid>
</dependency>
<!-- mvc插件 -->
<!-- Adds the MVC class and method names to server spans -->
<dependency>
<groupid>io.zipkin.brave</groupid>
<artifactid>brave-instrumentation-spring-webmvc</artifactid>
</dependency>
<!-- httpclient插件 -->
<!-- Instruments the underlying HttpClient requests that call the backend -->
<dependency>
<groupid>io.zipkin.brave</groupid>
<artifactid>brave-instrumentation-httpclient</artifactid>
</dependency>
<!-- dubbo插件 -->
<dependency>
<groupid>io.zipkin.brave</groupid>
<artifactid>brave-instrumentation-dubbo-rpc</artifactid>
</dependency>
<!-- mysql插件 -->
<dependency>
<groupid>io.zipkin.brave</groupid>
<artifactid>brave-instrumentation-mysql8</artifactid>
</dependency>
正文到此结束
- 本文标签: consumer Sleuth 配置 2019 GitHub ACE zip XML plugin pom 开发 Elasticsearch 线程 IDE src 索引 CTO scala classpath 插件 id js provider Spring cloud map tag SDN http java Docker bean maven dependencies springboot 数据库 redis client session 注释 Transport 服务器 list 服务端 https dubbo 架构设计 sql log4j2 Google 主机 spring json Service db 参数 zipkin description build docker-compose 数据 时间 下载 web value MQ git 开源 dubbo:provider cat stream API ask mysql Cassandra Twitter 端口 快的 分布式 tar schema Spring Cloud Sleuth UI 代码 python apache key IO ip 总结 Hystrix 进程 管理 entity 正则表达式 缓存 App JavaScript 源码 REST Spring Boot
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
收到
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
-
-
-
https://pplx.ai/floraliu4199466 这个链接打不开是什么原因?
-
-
-
-
来看看,最近更新了一波,顺着友联过来的,几年过去了,网站越搞越好,厉害
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

