简易的java爬虫项目
简易的java爬虫项目
本项目仅供java新手学习交流,由于本人也是一名java初学者,所以项目中也有很多不规范的地方,希望各位高手不吝赐教,在评论区指出我的不足,我会虚心学习;
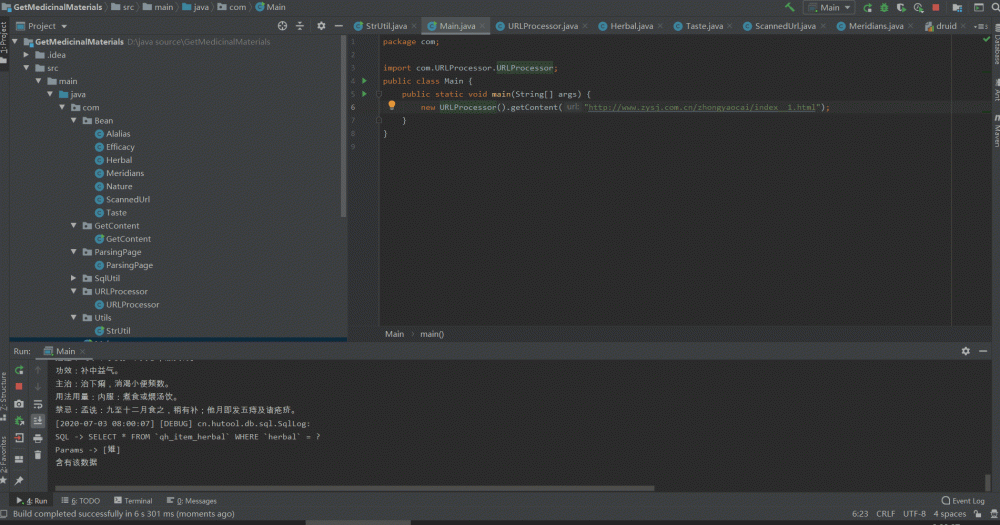
成果预览:
在开始讲述前想来展示一下项目的最终效果(下面是项目的运行效果和最终插入的数据):
需求简介:
我想要获取一个中医网站中的所有的中药材的信息并将他们存入到我的数据库中用来自己进行分析和学习。药材的信息包括:药材名,别名,功能主治,性状,味道,归经,来源,用法用量。
页面分析:
我们需要的数据都是以 “ http://www.zysj.com.cn/zhongyaocai/yaocai”开头的链接地址,如“ http://www.zysj.com.cn/zhongyaocai/yaocai_a/anchundan.html ”,“ http://www.zysj.com.cn/zhongyaocai/yaocai_a/anyou.html ”,“ http://www.zysj.com.cn/zhongyaocai/yaocai_l/longchuanhuajingye.html ”。我们需要的内容是该页面内的以下部分:

通过观察源代码发现,我们主要需要或得到如下内容的标签:

分析完毕后,我们就来进行代码操作做吧!
项目包含技术:
- hutool工具包(用于将爬虫获取的数据插入数据库)
- druid
- HttpClient(用于获取页面内容)
- HtmlCleaner(用于在从获取的页面内容中提取有用的内容)
项目运行流程简述:
我提供一个目标网站的链接,然后爬虫自己进行分析,抓取并储存数据。
原理概述:
首先,在讲原理前需要展示一下项目的结构:
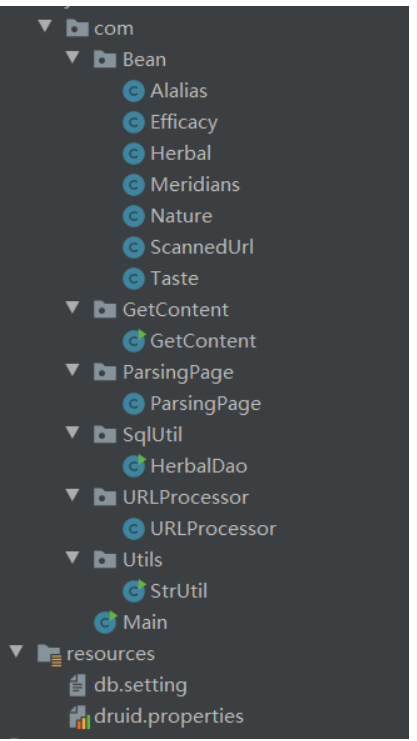
- Bean包的封装对象用于数据库插入
- URlProcessor包下的URlProcessor类用于获取存放目标数据的页面链接。
- ParsingPage包下的ParsingPage类用于获取页面内容。
- GetContent包下的GetContent类用于将从ParsingPage中获取页面内容中提取出我们想要的有效数据。
- SqlUtil包下的SqlUtil类用于将获取的有效数据存入数据库中
- StrUtil用于将得到的内容进行一些字符串处理
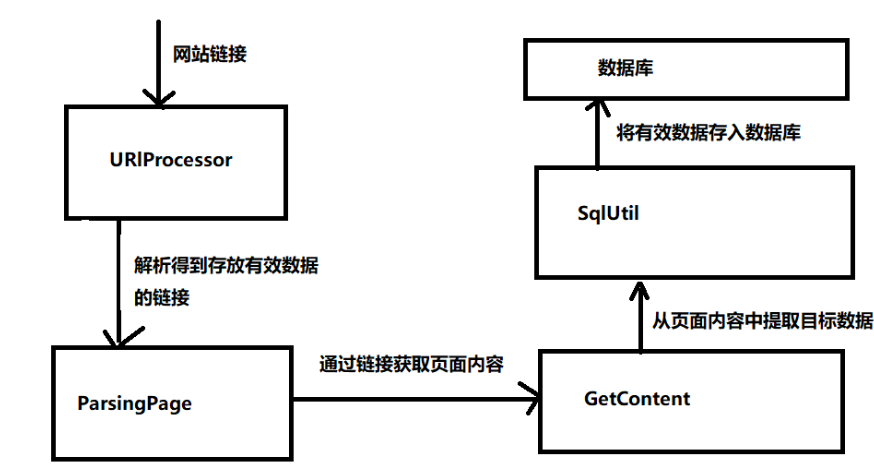
下面是该项目的工作流程图:
 具体实现;
具体实现;
Main类下的main方法用于启动该项目
package com;
import com.URLProcessor.URLProcessor;
public class Main {
public static void main(String[] args) {
//创建一个URLProcessor的对象并传给该对象的getContent方法一个正确的链接,即可开始爬取
new URLProcessor().getContent("http://www.zysj.com.cn/zhongyaocai/index__1.html");
}
}
URlProcessor类:该类下有getContent和parsingPage方法,(这两个方法的作用跟上面的Parsing Page和GetContent两个类的作用相同。只是本人技术有限,没能做到代码重构,欢迎各位小伙伴们指教。)该类通过了递归调用不断地解析页面获取有效的url,如果url有效,有效url传给ParsingPage类来进行进一步的操作。下面是
package com.URLProcessor;
import com.Bean.Herbal;
import com.GetContent.GetContent;
import com.ParsingPage.ParsingPage;
import com.SqlUtil.HerbalDao;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONArray;
import org.apache.http.HttpEntity;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClientBuilder;
import org.apache.http.util.EntityUtils;
import org.htmlcleaner.HtmlCleaner;
import org.htmlcleaner.TagNode;
import org.htmlcleaner.XPatherException;
import java.io.*;
import java.nio.charset.StandardCharsets;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.List;
/*
* url解析器,用于获取url
* */
public class URLProcessor {
//页面获取器,用于储存已扫描的链接,防止重复扫描同一个链接和避免死循环扫描
List<String> scannedUrl=new ArrayList<String>();
//用于获取页面内容
public String getContent(String url){
String result=null;
//获取客户端
CloseableHttpClient httpClient= HttpClientBuilder.create().build();
//创建get请求
HttpGet httpGet=new HttpGet(url);
//相响应模型
CloseableHttpResponse response=null;
try {
//由客户端执行get请求
try {
response=httpClient.execute(httpGet);
} catch (IOException e) {
e.printStackTrace();
}
//响应模型中获取相应实体
HttpEntity responseEntity=response.getEntity();
// System.out.println("响应状态为:"+response.getStatusLine());
if (responseEntity!=null){
// System.out.println("响应长度:"+responseEntity.getContentLength());
// System.out.println("相应内容:"+ EntityUtils.toString(responseEntity));
//得到页面内容
result= EntityUtils.toString(responseEntity);
}
} catch (IOException e){
e.printStackTrace();
}
//this.getUrl(result);
//将获取的页面内容传送给url提取器
this.getUrl(result);
return result;
}
//url提取器,用于从页面内容中获取页面链接,并进行进一步的方法调用
public void getUrl(String htmlContent){
HtmlCleaner cleaner = new HtmlCleaner();
TagNode node = cleaner.clean(htmlContent);
// Object[] ns = node.getElementsByAttValue("href","http://weibo.com/qihuangdao",true,true);
// for(Object on : ns) {
// TagNode n = (TagNode) on;
// System.out.println("/thref="+n.getAttributeByName("href")+", text="+n.getText());
// }
//获取页面中所有的超链接,并储存在数组里
Object[] ns = node.getElementsByName("a",true);
//通过遍历数组,得到到有效的链接
for(Object on : ns) {
TagNode n = (TagNode) on;
// System.out.println("href="+n.getAttributeByName("href")+", text="+n.getText());
String href=n.getAttributeByName("href");
//初步过滤,规定的正确的超链接格式必须为。html结尾,且前半部分为/zhongyaocai/符合条件,进一步执行
if (!href.startsWith("http")&&href.endsWith(".html")&&href.startsWith("/zhongyaocai/")) {
//通过拼合得到完整的链接
href = "http://www.zysj.com.cn" + n.getAttributeByName("href");
//判断该超链接是否操作过,如果没,继续。
if (!scannedUrl.contains(href)) {
//将该超链接存入到已扫描的链接List里面。
scannedUrl.add(href);
//再次过滤,链接的前半部分必须为"http://www.zysj.com.cn/zhongyaocai/yaocai_"
if (href.startsWith("http://www.zysj.com.cn/zhongyaocai/yaocai_"))
{
//System.out.println("有效链接:" + href);
//是正确链接则分析并提取该页面的需要数据
Herbal herbal=new GetContent().getContent(href);
try {
//将数据插入插入数据库
new HerbalDao().mainAdd(herbal);
} catch (SQLException e) {
e.printStackTrace();
}
}
//分析该页面的链接页面,重复上述操作
this.getContent(href);
}
}
}
}
}
GetContent类:该类中的getContent方法通过页面链接获取页面内容,并且从页面内容中获取正确的数据,并赋值给一个Herbal对象中,并且返回该对象。
package com.GetContent;
import com.Bean.Herbal;
import com.ParsingPage.ParsingPage;
import com.SqlUtil.HerbalDao;
import com.Utils.StrUtil;
import org.htmlcleaner.HtmlCleaner;
import org.htmlcleaner.TagNode;
import org.htmlcleaner.XPatherException;
import java.util.List;
import java.util.Map;
public class GetContent {
public Herbal getContent(String url){
//创建用于返回结果的对象
Herbal herbalTemp=new Herbal();
//调用ParsingPage类的getContent方法获取页面内容,并存放在页面中。
String content=new ParsingPage().getContent(url);
//======下面是提取具体数据的方法======
//为了规范数据格式可能会用到我自己编写的StrUtil类进行格式化。
HtmlCleaner cleaner=new HtmlCleaner();
TagNode node=cleaner.clean(content);
Object[] ns =node.getElementsByAttValue("class", "drug py", true, true);
System.out.println("================================================================================================================");
//拼音
String py=null;
if (ns.length>0){
py=((TagNode)ns[0]).getText().toString().replaceAll(""","").replaceAll("拼音","").replaceAll("①","");
py=StrUtil.getAsciiToStr(py);
herbalTemp.setPY(py);
System.out.println("拼音:"+py);
}
//拼音首字母
String py_code= StrUtil.getBigStr(py);
herbalTemp.setPy_code(py_code);
System.out.println("拼音首字母:"+py_code);
//英文名
ns = node.getElementsByAttValue("class", "drug ywm", true, true);
String ename=null;
if (ns.length>0){
ename=((TagNode)ns[0]).getText().toString().replaceAll(""","").replaceAll("英文名","").replaceAll("①","");
herbalTemp.setEname(ename);
System.out.println("英文名:"+ename);
}
//名称
ns = node.getElementsByName("h1",true);
String herbal=null;
if (ns.length>0){
herbal=((TagNode)ns[0]).getText().toString();
herbalTemp.setHerbal(herbal);
System.out.println("名称:"+herbal);
}
//别名
String alias=null;
ns = node.getElementsByAttValue("class", "drug bm", true, true);
if (ns.length>0){
alias=((TagNode)ns[0]).getText().toString().replaceAll(""","").replaceAll("别名","").replaceAll("①","");
herbalTemp.setAlias(alias);
System.out.println("别名:"+alias);
}
//来源
String source=null;
ns = node.getElementsByAttValue("class", "drug ly", true, true);
if (ns.length>0){
source=((TagNode)ns[0]).getText().toString().replaceAll(""","").replaceAll("来源","").replaceAll("①","");
herbalTemp.setSource(source);
System.out.println("来源:"+source);
}
//性状
String trait=null;
ns = node.getElementsByAttValue("class", "drug xz", true, true);
if (ns.length>0){
trait=((TagNode)ns[0]).getText().toString().replaceAll(""","").replaceAll("性状","").replaceAll("①","");
herbalTemp.setTrait(trait);
System.out.println("性状:"+trait);
}
//性味
String xw=null;
ns = node.getElementsByAttValue("class", "drug xw", true, true);
if (ns.length>0){
xw=((TagNode)ns[0]).getText().toString().replaceAll(""","").replaceAll("性味","").replaceAll("①","");
}
Map<String,String> s=StrUtil.getNatureAndTaste(xw);
//性味
String nature=s.get("nature");
//药味
String taste=s.get("taste");
herbalTemp.setNature(nature);
herbalTemp.setTaste(taste);
System.out.println("药味:"+taste+"/n"+"药性:"+nature);
//归经
String meridians=null;
ns = node.getElementsByAttValue("class", "drug gj", true, true);
if (ns.length>0){
meridians=((TagNode)ns[0]).getText().toString().replaceAll(""","").replaceAll("归经","").replaceAll("①","");
herbalTemp.setMeridians(meridians);
System.out.println("归经:"+meridians);
}
//功能主治
String function=null;
ns = node.getElementsByAttValue("class", "drug gnzz", true, true);
if (ns.length>0){
function=((TagNode)ns[0]).getText().toString().replaceAll(""","").replaceAll("功能主治","").replaceAll("①","");
}
//功效 用于前面
String efficacy=null;
//主治 用于。。。。。
String indications=null;
List<String> stringList=StrUtil.getEfficacyAndIndication(function);
if (stringList.size()==1){
//功效 用于前面
efficacy=stringList.get(0);
herbalTemp.setEfficacy(efficacy);
}else if (stringList.size()==2){
//功效 用于前面
efficacy=stringList.get(0);
//主治 用于。。。。。
indications=stringList.get(1);
herbalTemp.setEfficacy(efficacy);
herbalTemp.setIndications(indications);
}
System.out.println("功效:"+efficacy+"/n"+"主治:"+indications);
//用法用量 usagedosage
String usagedosage=null;
ns = node.getElementsByAttValue("class", "drug yfyl", true, true);
if (ns.length>0){
usagedosage=((TagNode)ns[0]).getText().toString().replaceAll(""","").replaceAll("用法用量","").replaceAll("①","");
herbalTemp.setUsagedosage(usagedosage);
System.out.println("用法用量:"+usagedosage);
}
//炮制方法 process
String process=null;
ns = node.getElementsByAttValue("class", "drug pz", true, true);
if (ns.length>0){
process=((TagNode)ns[0]).getText().toString().replaceAll(""","").replaceAll("炮制","").replaceAll("①","");
herbalTemp.setProcess(process);
System.out.println("炮制方法:"+process);
}
//鉴别方法 identify
ns = node.getElementsByAttValue("class", "drug jb", true, true);
String identify=null;
if (ns.length>0){
identify=((TagNode)ns[0]).getText().toString().replaceAll(""","").replaceAll("鉴别","").replaceAll("①","");
herbalTemp.setIdentify(identify);
System.out.println("鉴别方法:"+identify);
}
//贮藏
ns = node.getElementsByAttValue("class", "drug zc", true, true);
String store=null;
if (ns.length>0){
store=((TagNode)ns[0]).getText().toString().replaceAll(""","").replaceAll("贮藏","").replaceAll("①","");
herbalTemp.setStore(store);
System.out.println("贮藏:"+store);
}
//mattersneedattention 注意事项
ns = node.getElementsByAttValue("class", "drug jj", true, true);
String mattersneedattention=null;
if (ns.length>0){
mattersneedattention=((TagNode)ns[0]).getText().toString().replaceAll(""","").replaceAll("禁忌","").replaceAll("①","");
herbalTemp.setMattersneedattention(mattersneedattention);
System.out.println("注意事项:"+mattersneedattention);
}
//contraindications 禁忌
ns = node.getElementsByAttValue("class", "drug zy", true, true);
String contraindications=null;
if (ns.length>0){
contraindications=((TagNode)ns[0]).getText().toString().replaceAll(""","").replaceAll("注意","").replaceAll("①","");
herbalTemp.setContraindications(contraindications);
System.out.println("禁忌:"+contraindications);
}
//remark 备注
ns = node.getElementsByAttValue("class", "drug bz", true, true);
String remark=null;
if (ns.length>0){
remark=((TagNode)ns[0]).getText().toString().replaceAll(""","").replaceAll("备注","").replaceAll("①","");
herbalTemp.setRemark(remark);
System.out.println("备注:"+remark);
}
return herbalTemp;
}
// public static void main(String[] args) {
// new GetContent().getContent("http://www.zysj.com.cn/zhongyaocai/yaocai_b/banlangen.html");
// }
}
ParsingPage类,通过链接获取页面的整体内容
package com.ParsingPage;
import com.URLProcessor.URLProcessor;
import org.apache.http.HttpEntity;
import org.apache.http.HttpVersion;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClientBuilder;
import org.apache.http.util.EntityUtils;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class ParsingPage {
public String getContent(String url){
String result=null;
//获取客户端
CloseableHttpClient httpClient= HttpClientBuilder.create().build();
//创建get请求
HttpGet httpGet=new HttpGet(url);
httpGet.setProtocolVersion(HttpVersion.HTTP_1_0);
//相响应模型
CloseableHttpResponse response=null;
try {
//由客户端执行get请求
try {
response=httpClient.execute(httpGet);
} catch (IOException e) {
e.printStackTrace();
}
//响应模型中获取相应实体
HttpEntity responseEntity=response.getEntity();
if (responseEntity!=null){
result= EntityUtils.toString(responseEntity);
}
} catch (IOException e){
e.printStackTrace();
}
return result;
}
}
StrUtil类
package com.Utils;
import net.sourceforge.pinyin4j.PinyinHelper;
import net.sourceforge.pinyin4j.format.HanyuPinyinCaseType;
import net.sourceforge.pinyin4j.format.HanyuPinyinOutputFormat;
import net.sourceforge.pinyin4j.format.HanyuPinyinToneType;
import net.sourceforge.pinyin4j.format.exception.BadHanyuPinyinOutputFormatCombination;
import java.io.IOException;
import java.util.*;
public class StrUtil {
public static String getBigStr(String string){
StringBuilder result= new StringBuilder();
if(string!=null){
char[] chars=string.toCharArray();
for (char aChar : chars) {
if (aChar >= 'A' && aChar <= 'Z') {
result.append(aChar);
}
}
}
return result.toString();
}
public static List<String> getEfficacyAndIndication(String string){
List<String> result=new ArrayList<String>();
if (string!=null){
if (string.contains("《")){
int end=string.indexOf(":")+1;
string=string.substring(end);
}
int index=-1;
if(string.contains("用于")){
index=string.indexOf("用于");
}else if (string.contains("主治")){
index=string.indexOf("主治");
}else if (string.contains("主")){
index=string.indexOf("主");
}else if (string.contains("治")){
index=string.indexOf("治");
}
if (index!=-1){
result.add(string.substring(0,index));
result.add(string.substring(index));
}else {
result.add(string);
}
}
return result;
}
public static Map<String,String> getNatureAndTaste(String string){
Map<String,String> stringList=new HashMap<>();
if (string!=null){
string=string.replaceAll("。","");
String natureStr="寒热温凉平";
String taste="辛甘酸苦咸";
char[] chars=string.toCharArray();
String nTemp="";
String tTemp="";
for (char c:chars){
for (char n:natureStr.toCharArray()){
if (c==n){
nTemp+= n + "、";
}
}
for (char t:taste.toCharArray()){
if (t==c){
tTemp+=t+"、";
}
}
}
if (nTemp.length()!=0){
nTemp=nTemp.substring(0,nTemp.length()-1);
}
if (tTemp.length()!=0){
tTemp=tTemp.substring(0,tTemp.length()-1);
}
stringList.put("nature", nTemp);
stringList.put("taste", tTemp);
}
return stringList;
}
public static String getAsciiToStr(String string){
String result="";
if (string!=null){
List<Integer> list=getNumber(string);
int i=0;
for (char c:getStr(string).toCharArray()){
if (c!=';'){
result+=c;
}else {
result+=(char)(list.get(i)).intValue();
i++;
}
}
}
return result;
}
public static List<Integer> getNumber(String string){
List<Integer> numberList=new ArrayList<Integer>();
if (string!=null){
StringBuilder temp= new StringBuilder();
for (int i=0;i<string.length();i++){
if (string.charAt(i)<'0'||string.charAt(i)>'9'){
if (!temp.toString().equals("")){
numberList.add(Integer.parseInt(temp.toString()));
}
temp = new StringBuilder();
}else{
temp.append(string.charAt(i));
}
}
int sum=0;
for (Integer integer:numberList){
sum=sum+integer;
}
}
return numberList;
}
public static String getStr(String string){
String result="";
if (string!=null){
char[] chars=string.toCharArray();
for (char c:chars){
if (c<'0'||c>'9'){
result+=c;
}
}
result=result.replaceAll("&#","").replaceAll(" ","");
}
return result;
}
//大蓝根、大青根
public static List<String> getAlias(String string){
List<String> list=new ArrayList<>();
if (string!=null){
int index=-1;
if (string.contains("(") ){
index=string.indexOf("(");
string=string.substring(0,index);
}else if (string.contains("(")){
index=string.indexOf("(");
string=string.substring(0,index);
}else if(string.contains("《")){
index=string.indexOf("《");
string=string.substring(0,index);
}
String[] result=string.split("、");
//==============
if (getSpecial(string)!=null){
for (String s:getSpecial(string)){
if (getSpecial(s)!=null){
List<String> temp=getAlias(s);
for (String s2:temp){
list.add(s2);
}
}else {
list.add(s);
}
}
}else {
list.add(string);
}
}
return list;
}
public static List<String> getMeridian(String string){
List<String> result=new ArrayList<>();
if (string!=null){
if (string.contains("《")){
int end=string.indexOf(":")+1;
string=string.substring(end);
}
string=string.replaceAll("入","").replaceAll("。","")
.replaceAll("二","").replaceAll("三","")
.replaceAll("四","").replaceAll("五","")
.replaceAll("经","");
if (getSpecial(string)!=null){
for (String s:getSpecial(string)){
if (getSpecial(s)!=null){
List<String> temp=getMeridian(s);
for (String s2:temp){
result.add(s2+"经");
}
}else {
result.add(s+"经");
}
}
}else {
result.add(string+"经");
}
}
return result;
}
public static String[] getSpecial(String string){
if (string.contains("、")){
return string.split("、");
}else if (string.contains(",")){
return string.split(",");
}else if (string.contains(",")){
return string.split(",");
}else if (string.contains(";")){
return string.split(";");
}else {
return null;
}
}
public static void main(String[] args) {
String str="筋活血,凉血,止血。主治贫血或失血过多,风湿痛,跌打损伤,胃痛,疖疮痈肿,皮炎,湿疹。";
List<String>a=getEfficacyAndIndication(str);
for (String s:a){
System.out.println(s); }
// System.out.println(ChineseToFirstLetter("夻口巴"));
// List<String> strings=StrUtil.getEfficacyAndIndication("");
// for (String s :strings){
// System.out.println(s);
// }
// System.out.println(ChineseToFirstLetter("你是一个猪"));
// Map<String,String> s=StrUtil.getNatureAndTaste("苦,寒。");
// System.out.println("药味:"+s.get("taste")+"药性:"+s.get("natureStr"));
//
// String s="B i Sh o";
// System.out.println(getAsciiToStr(s));
}
public static String ChineseToFirstLetter(String c) {
String string = "";
try {
char b;
int a = c.length();
for (int k = 0; k < a; k++) {
b = c.charAt(k);
String d = String.valueOf(b);
String str = converterToFirstSpell(d);
String s = str.toUpperCase();
String g = s;
char h;
int j = g.length();
for (int y = 0; y <= 0; y++) {
h = g.charAt(0);
string += h;
}
}
}catch (Exception e){
e.printStackTrace();
}
return string;
}
public static String converterToFirstSpell(String chines) {
String pinyinName = "";
try{
char[] nameChar = chines.toCharArray();
HanyuPinyinOutputFormat defaultFormat = new HanyuPinyinOutputFormat();
defaultFormat.setCaseType(HanyuPinyinCaseType.LOWERCASE);
defaultFormat.setToneType(HanyuPinyinToneType.WITHOUT_TONE);
for (int i = 0; i < nameChar.length; i++) {
String s = String.valueOf(nameChar[i]);
if (s.matches("[//u4e00-//u9fa5]")) {
try {
String[] mPinyinArray = PinyinHelper.toHanyuPinyinStringArray(nameChar[i], defaultFormat);
pinyinName += mPinyinArray[0];
} catch (BadHanyuPinyinOutputFormatCombination e) {
e.printStackTrace();
}
} else {
pinyinName += nameChar[i];
}
}
}catch (NullPointerException e){
e.printStackTrace();
}
return pinyinName;
}
}
正文到此结束
热门推荐










相关文章

近期评论
-
不会英语啊。
-
前100名用户会展示特殊的纪念徽章
-
-
https://pplx.ai/floraliu4199466 这个链接打不开是什么原因?
-
-
-
-
来看看,最近更新了一波,顺着友联过来的,几年过去了,网站越搞越好,厉害
-
哥太牛了
-
是呀,看您的IP显示在美国,还以为您移民了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

