Mybatis【进阶】
1.映射文件
在mapper.xml文件中配置很多的sql语句, 执行每个sql语句时,封装为MappedStatement对象,mapper.xml以statement为单位管理sql语句
Statement的实际位置就等于namespace+StatementId占位符
在Mybatis中,有2种占位符:
#{ } 解析传递进来的参数数据
${ } 对传递进来的参数原样拼接在SQL中主键返回
如果我们一般插入数据的话,如果我们想要知道刚刚插入的数据的主键是多少,我们可以通过以下的方式来获取:
- 通过LAST_INSERT_ID()获取刚插入记录的自增主键值,在insert语句执行后,执行select LAST_INSERT_ID()就可以获取自增主键

resultType
二、Mybatis关联映射
Mybatis的映射关系分为:一对一、一对多、多对多
三、Mybatis【缓存、代理、逆向工程】
(一)、Mybatis缓存
缓存的意义:
- 将用户经常 查询的数据放在缓存(内存)中 ,用户去查询数据就不用从磁盘上(关系型数据库数据文件)查询, 从缓存中查询,从而提高查询效率 ,解决了高并发系统的问题
mybatis提供一级缓存和二级缓存
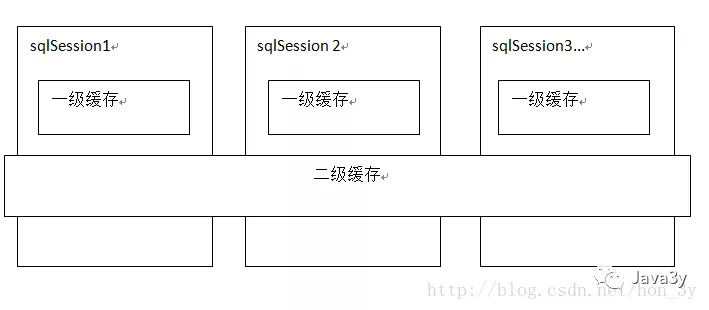
mybatis一级缓存是一个SqlSession级别,sqlsession只能访问自己的一级缓存的数据 二级缓存是跨sqlSession,是mapper级别的缓存,对于mapper级别的缓存不同的sqlsession是可以共享的 复制代码
Mybatis一级缓存原理:
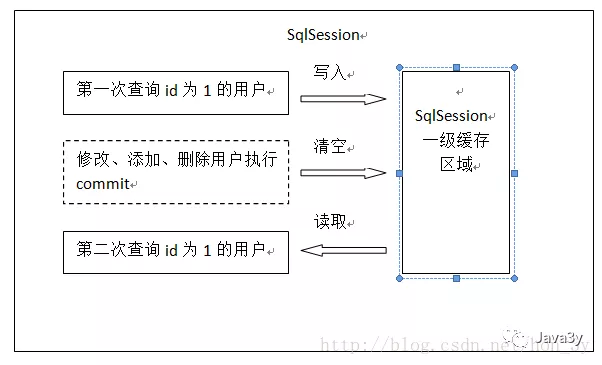
key:hashcode+sql+sql输入参数+输出参数(sql的唯一标识) value:用户信息 复制代码
同一个sqlsession再次发出相同的sql,就从缓存中读取数据库。如果两次中间出现commit操作(修改、添加、删除),本sqlsession中的一级缓存区域全部清空,下次再去缓存中查询不到所以要从数据库查询,从数据库查询到再写入缓存
Mybatis一级缓存值得注意的地方:
Mybatis默认就是支持一级缓存的,并不需要我们配置. mybatis和spring整合后进行mapper代理开发,不支持一级缓存,mybatis和spring整合,spring按照mapper的模板去生成mapper代理对象,模板中在最后统一关闭sqlsession 复制代码
Mybatis二级缓存:
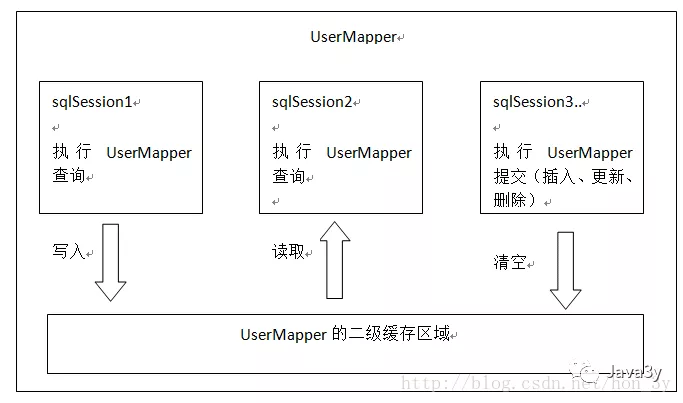
Mybatis二级缓存配置:
需要我们在Mybatis的配置文件中配置二级缓存

查询结果映射的pojo序列化
mybatis二级缓存需要将 查询结果映射的pojo (Plain Ordinary Java Object,简单的Java对象,实际就是普通JavaBeans实现) java.io.serializable接口,如果不实现则抛出异常
二级缓存可以将内存的数据写到磁盘,存在对象的序列化和反序列化,所以 要实现java.io.serializable接口禁用二级缓存
对于 变化频率较高的sql,需要禁用二级缓存 :
在statement中设置useCache=false可以禁用当前select语句的二级缓存 ,即每次查询都会发出sql去查询,默认情况是true,即该sql使用二级缓存
刷新缓存
缓存是在查询语句中配置,执行增删改操作默认会刷新缓存 ,但我们也可以配置不刷新(不建议)flushCache="false"
,默认是true

(二)、Mapper代理方式
Mapper代理方式的意思就是: 程序员只需要写dao接口,dao接口实现对象由mybatis自动生成代理对象
Mapper代理需要实现的规范:
- mapper.xml中namespace指定为mapper接口的全限定名
----此步骤目的:通过mapper.xml和mapper.java进行关联 - mapper.xml中statement的id就是mapper.java中方法名
- mapper.xml中statement的parameterType和mapper.java中方法输入参数类型一致
- mapper.xml中statement的resultType和mapper.java中方法返回值类型一致
再次说明: statement就是我们在mapper.xml文件中命名空间+sql指定的id
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.mapper.StudentMapper"> <!-- 指定接口 -->
<!--
insert 表示插入数据
id="接口中方法名称"
parameterType="方法的参数类型,实体类路径全称"
#{实体类属性名称}
此描述方式,适用于实体类属性名与表的字段名完全相同的情况
-->
<insert id="save" parameterType="com.po.Student">
insert into student(sname,sex,address,birthday,classid)
values(#{sname},#{sex},#{address},#{birthday},#{classid})
</insert>
<update id="update" parameterType="com.po.Student">
update student set sname=#{sname},sex=#{sex},address=#{address},
birthday=#{birthday},classid=#{classid} where sid=#{sid}
</update>
<!--
#{参数名称}
-->
<delete id="delById" parameterType="Integer">
delete from student where sid=#{stuid}
</delete>
<!--
resultType=“方法的返回类型”
-->
<select id="findById" parameterType="Integer" resultType="com.po.Student">
select * from student where sid=#{sid}
</select>
<!--
此处应为List集合的元素类型com.po.Student
-->
<select id="findAll" resultType="com.po.Student">
select * from student where 1=1
</select>
</mapper>
复制代码
Mapper代理返回值问题
如果是返回的单个对象,返回值类型是pojo类型,生成的代理对象内部通过selectOne获取记录 如果返回值类型是集合对象,生成的代理对象内部通过selectList获取记录
(三)、Mybatis逆向工程
详见Itrip项目(1)中 IDEA中使用MyBatis Generator逆向工程生成代码
在pom.xml添加插件
编写配置文件generatorConfig.xml和generator.properties
Command line中添加如下代码: mybatis-generator:generate -e
四、Mybatis面试题
1.#{ }和${ }的区别是什么?
在Mybatis中,有两种占位符:
#{}解析传递进来的参数数据
${}对传递进来的参数原样拼接在SQL中
#{}是预编译处理,${}是字符串替换。
使用#{}可以有效的防止SQL注入,提高系统安全性
复制代码
2.当实体类中的属性名和表中的字段名不一样 ,怎么办 ?
第1种: 通过在查询的sql语句中定义字段名的别名,让字段名的别名和实体类的属性名一致

我认为第二种方式会好一点
3.如何获取自动生成的(主)键值?
如果我们一般插入数据的话,如果我们想要知道刚刚插入的数据的主键是多少,我们可以通过以下的方式来获取
通过LAST_INSERT_ID( )获取刚插入记录的自增主键值 ,在insert语句执行后,执行select LAST_INSERT_ID( )就可以获取自增主键
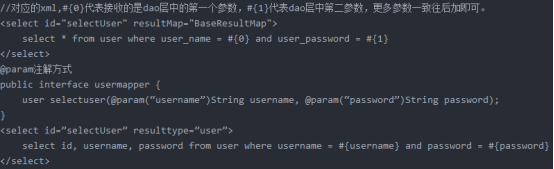
4.在mapper中如何传递多个参数?
第一种: 使用占位符的思想在映射文件中使用#{0},#{1}代表传递进来的第几个参数
使用@param注解来命名参数
5.Mybatis动态sql是做什么的?都有哪些动态sql?能简述一下动态sql的执行原理不?
• Mybatis动态sql可以让我们 在xml映射文件内,以标签的形式编写动态sql,完成逻辑判断和动态拼接sql的功能• Mybatis提供了 9种 动态sql标签:trim|where|set|foreach|if|choose|when|otherwise|bind
• 其执行原理为,使用OGNL从sql参数对象中计算表达式的值, 根据表达式的值动态拼接sql,以此来完成动态sql的功能
6.Mybatis的Xml映射文件中,不同的Xml映射文件,id是否可以重复?
如果配置了namespace那么当然是可以重复的,因为我们的Statement实际上就是namespace+id如果没有配置namespace的话,那么相同的id就会导致覆盖了
7.为什么说Mybatis是半自动ORM映射工具?它与全自动的区别在哪里?
Mybatis在查询关联对象或关联集合对象时,需要 手动编写sql来完成,所以,称之为半自动ORM映射工具而Hibernate属于全自动ORM映射工具,使用Hibernate查询关联对象或者关联集合对象时,可以根据对象关系模型直接获取,所以它是全自动的
8.通常一个Xml映射文件,都会写一个Dao接口与之对应,请问,这个Dao接口的工作原理是什么?Dao接口里的方法,参数不同时,方法能重载吗?
Dao接口,就是人们常说的Mapper接口 ,接口的全限名,就是映射文件中的namespace的值,接口的方法名,就是映射文件中MappedStatement的id值,接口方法内的参数,就是传递给sql的参数Mapper接口是没有实现类的 ,当调用接口方法时,接口全限名+方法名拼接字符串作为key值,可唯一定位一个MappedStatement
举例: com.mybatis3.mappers.StudentDao.findStudentById
可以唯一找到namespace为com.mybatis3.mappers.StudentDao下面id = findStudentById的MappedStatement,在Mybatis中,每一个< select>、< insert>、< delete>标签,都会被解析为一个MappedStatement对象
Dao接口里的方法,是不能重载的,因为是全限名+方法名的保存和寻找策略。
Dao接口的工作原理是JDK动态代理,Mybatis运行时会使用JDK动态代理为Dao接口生成代理proxy对象,代理对象proxy会拦截接口方法,转而执行MappedStatement所代表的sql,然后将sql执行结果返回
9.接口绑定有几种实现方式,分别是怎么实现的?
接口绑定有两种实现方式:
一种是通过注解绑定,就是在接口的方法上面加上@Select@Update等注解里面包含Sql语句来绑定 另外一种就是通过xml里面写SQL来绑定,在这种情况下,要指定xml映射文件里面的namespace必须为接口的全路径名 复制代码
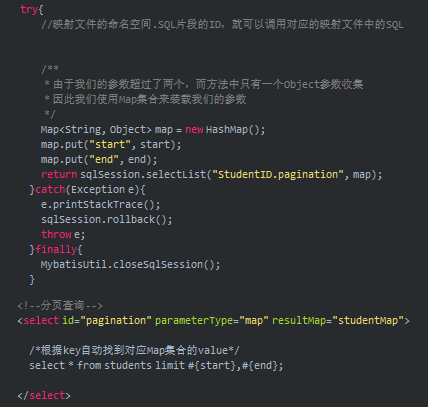
10.Mybatis是如何进行分页的?分页插件的原理是什么?
Mybatis使用 RowBounds对象 进行分页;也可以使用 分页插件 来完成物理分页
分页插件的基本原理
是使用Mybatis提供的插件接口,实现自定义插件,在插件的拦截方法内拦截待执行的sql,然后重写sql,根据dialect方言,添加对应的物理分页语句和物理分页参数 举例:
select * from student
拦截sql后重写为: select t.* from (select * from student)t limit 0,10
11.Mybatis是否支持延迟加载?如果支持,它的实现原理是什么?
Mybatis仅支持association关联对象和collection关联集合对象的延迟加载 ,association指的就是一对一,collection指的就是一对多查询。在Mybatis配置文件中,可以配置是否启用延迟加载 lazyLoadingEnabled=true|false
延迟加载的原理是, 使用CGLIB创建目标对象的代理对象 ,当调用目标方法时,进入拦截器方法
延迟加载 也称为懒加载,是指在进行表的关联查询时,利用延迟加载,先加载主信息。需要关联信息时再去按需加载关联信息。这样会大大提高数据库性能,因为查询单表要比关联查询多张表速度要快
12.Mybatis都有哪些Executor执行器?它们之间的区别是什么?
Mybatis有3种基本的Executor执行器, SimpleExecutor 、 ReuseExecutor 、 BatchExecutor
SimpleExecutor:每执行一次update或select,就开启一个Statement对象,用完立刻关闭Statement对象 ReuseExecutor:执行update或select,以sql作为key查找Statement对象,存在就使用,不存在就创建, 用完后,不关闭Statement对象,而是放置于Map内,供下一次使用。简言之,就是重复使用Statement对象。 BatchExecutor:执行update(没有select,JDBC批处理不支持select),将所有sql都添加到批处理中(addBatch()), 等待统一执行(executeBatch()),它缓存了多个Statement对象,每个Statement对象都是addBatch()完毕后, 等待逐一执行executeBatch()批处理。与JDBC批处理相同 复制代码
13.MyBatis与Hibernate的区别?
• 相同点:
--Hibernate与MyBatis都可以是通过 SessionFactoryBuider 由XML配置文件生成 SessionFactory ,然后由SessionFactory 生成Session,最后由 Session 来开启执行事务和SQL语句
--Hibernate和MyBatis都支持 JDBC和JTA(Java Transaction API)事务处理• 不同点:
Mybatis和Hibernate不同, Mybatis不完全是一个ORM框架 , 因为MyBatis需要程序员自己编写Sql语句 ,对sql修改和优化非常容易实现, Mybatis适合开发需求变更频繁的系统 ,比如:互联网项目
Hibernate入门门槛高, Hibernate不用写sql语句,是一个ORM框架 。hibernate适合需求固定,对象数据模型稳定,中小型项目,比如:企业OA系统(Office Automation System,OA系统概括性来讲就是人力资源管理系统)正文到此结束
- 本文标签: 高并发 pom 参数 并发 map src 需求 ORM 一级缓存 spring value Statement find mybatis缓存 IDE ACE sqlsession 程序员 id db 分页 zab sql lib 代码 bean 二级缓存 key JDBC 一对多 数据 Office SQL执行 App 工作原理 编译 mybatis 缓存 安全 企业 API Action executor XML session https 关联查询 UI 删除 动态SQL CTO Collection update 插件 cglib 互联网 开发 管理 FAQ cache Select 模型 ip 返回值类型 配置 http mapper 空间 IO java list Proxy 数据库 主键值 NSA 数据模型 自动生成 解析
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐








相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

