扯淡 Java 集合

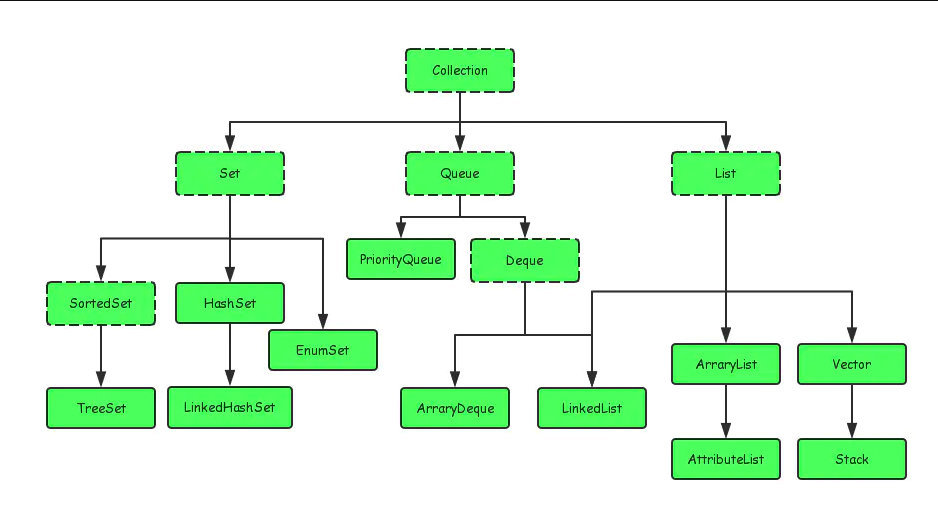
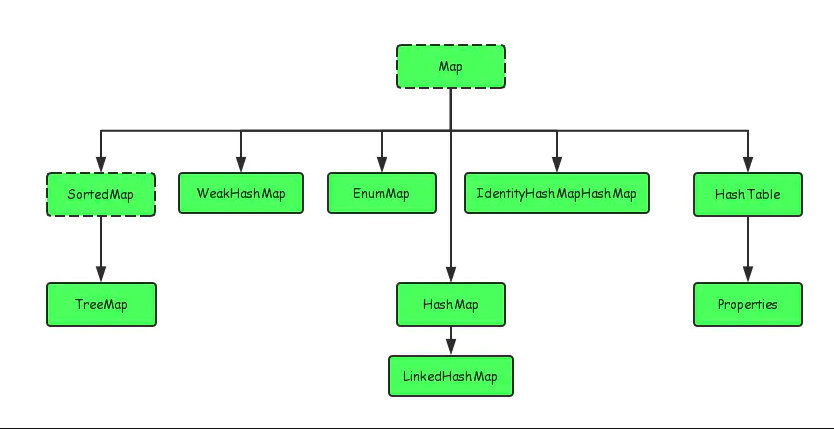
大致分类:List、Set、Queue、Map
Iterable
Collection 接口中继承 Iterable 接口。这个接口为 for each 循环设计、接口方法中有返回Iterator对象
public interface Iterable<T> {
Iterator<T> iterator();
default void forEach(Consumer<? super T> action) {
Objects.requireNonNull(action);
for (T t : this) {
action.accept(t);
}
}
default Spliterator<T> spliterator() {
return Spliterators.spliteratorUnknownSize(iterator(), 0);
}
}
我们看个例子来理解一下上面的话
LinkedList<Integer> linkedList = new LinkedList<>();
linkedList.add(1);
linkedList.add(2);
linkedList.add(3);
for (Integer integer : linkedList) {
System.out.println(integer);
}
反编译之后
LinkedList<Integer> linkedList = new LinkedList();
linkedList.add(1);
linkedList.add(2);
linkedList.add(3);
Iterator var4 = linkedList.iterator();
while(var4.hasNext()) {
Integer integer = (Integer)var4.next();
System.out.println(integer);
}
Iterator
在 Iterable 接口中出现了这么一个迭代器
public interface Iterator<E> {
boolean hasNext();
E next();
default void remove() {
throw new UnsupportedOperationException("remove");
}
default void forEachRemaining(Consumer<? super E> action) {
Objects.requireNonNull(action);
while (hasNext())
action.accept(next());
}
}
主要是为了统一遍历方式、使集合的数据结构和访问方式解耦
我们来看看最常见的 ArrayList 类中的内部类
private class Itr implements Iterator<E> {
int cursor; // 下一次要返回的下标
int lastRet = -1; // 这一次next 要返回的下标
int expectedModCount = modCount; // 修改次数
public boolean hasNext() {
return cursor != size;
}
@SuppressWarnings("unchecked")
public E next() {
checkForComodification();
int i = cursor;
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[lastRet = i];
}
public void remove() {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
ArrayList.this.remove(lastRet);
cursor = lastRet;
lastRet = -1;
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
@Override
@SuppressWarnings("unchecked")
public void forEachRemaining(Consumer<? super E> consumer) {
Objects.requireNonNull(consumer);
final int size = ArrayList.this.size;
int i = cursor;
if (i >= size) {
return;
}
final Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length) {
throw new ConcurrentModificationException();
}
while (i != size && modCount == expectedModCount) {
consumer.accept((E) elementData[i++]);
}
// update once at end of iteration to reduce heap write traffic
cursor = i;
lastRet = i - 1;
checkForComodification();
}
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
我们都知道在 ArrayList 中 forEach 中的时候 remove 会导致 ConcurrentModificationException
ArrayList<Integer> arrayList = new ArrayList<>();
arrayList.add(1);
arrayList.add(1);
arrayList.add(1);
for (Integer integer : arrayList) {
arrayList.remove(integer);
}
Exception in thread "main" java.util.ConcurrentModificationException
而我们使用 Iterator 进行 remove 的时候就不会有这个问题、
public void remove() {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
ArrayList.this.remove(lastRet);
cursor = lastRet;
lastRet = -1;
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
List
ArrayList
- 动态数组
- 线程不安全
- 元素允许为 null
- 实现了 List、RandomAccess、Cloneable、Serializable
- 连续的内存空间
- 增加和删除都会导致 modCount 的值改变
- 默认扩容为一半
Vector
- 线程安全
- 扩容是上一次的一倍
- 存在 modCount
- 每个操作数组的方法都加上了 synchronized
CopyOnWriteArrayList
- 写时复制、加锁
- 耗内存
- 实时性不高
- 不存在 ConcurrentModificationException
- 数据量最好不要太大
- 使用 ReentrantLock 进行加锁
Collections.synchronizedList
- synchronized 代码块
- 对象锁可以参数传进去、或者当前对象
- 需要传 List 对象进去
SynchronizedList(List<E> list) {
super(list);
this.list = list;
}
SynchronizedList(List<E> list, Object mutex) {
super(list, mutex);
this.list = list;
}
LinkedList
- ArrayList 增删效率低、改查效率高、而 LinkedList刚刚相反
- 链表实现
- for 循环的时候、根据 index 是靠近前半段还是后半段来决定是顺序还是逆序
- 增删的时候会改变 modCount
Map
常见的四个实现类
- HashMap
- HashTable
- LinkedHashMap
- TreeMap
HashMap
HashMap 是数组+链表+红黑树(JDK1.8增加了红黑树部分)实现的,如下如所示。
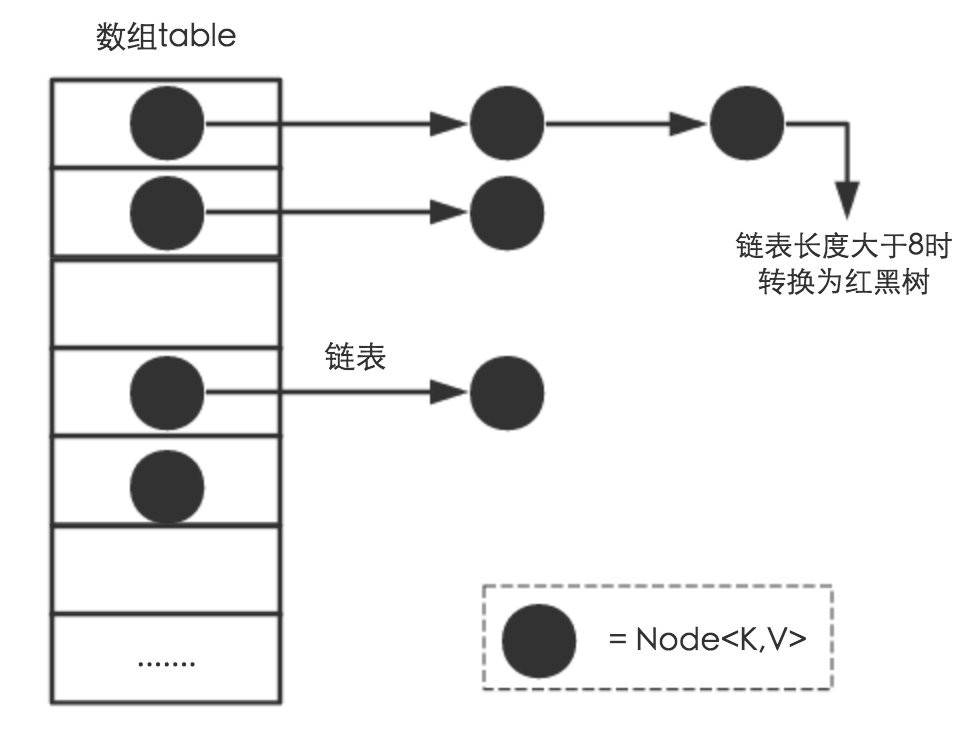
transient Node<K,V>[] table; // 实际存储的 key-value 的数量 transient int size; // 阈值、当存放在 table 中的 key-value 大于这个值的时候需要进行扩容 int threshold; // 负载因子 因为 threshold = loadFactor * table.length final float loadFactor;
table 的长度默认是 16 、loadFactor 的默认值是 0.75
继续看看 Node 的数据结构
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
}
确定哈希桶数组索引的位置
方法一:
static final int hash(Object key) { //jdk1.8 & jdk1.7
int h;
// h = key.hashCode() 为第一步 取hashCode值
// h ^ (h >>> 16) 为第二步 高位参与运算
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
方法二:
static int indexFor(int h, int length) { //jdk1.7的源码,jdk1.8 直接使用里面的方法体、没有定义这个方法
return h & (length-1); //第三步 取模运算
}
JDK 1.8 的
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 这里
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
.....................
....................
}
这里的Hash算法本质上就是三步: 取key的hashCode值 、 高位运算 、 取模运算
取模运算就是 h & (length - 1 ) 、其实它是等价于 h%length 、因为 length 总是 2 的 n 次方。因为 &比%具有更高的效率
(h = key.hashCode()) ^ (h >>> 16) 将 key 的 hashCode 与 它的高 16 位进行 异或的操作
其实为啥这么操作呢、是因为当 table 的数组的大小比较小的时候、key 的 hashCode 的高位信息就会直接被丢弃掉、这个时候就会增加了低位的冲突、所以将高位的信息通过异或保留下来
那其实为啥要异或呢?双目运算不是还有 & || 吗
来自知乎的解答
方法一其实叫做一个扰动函数、hashCode的高位和低位做异或、就是为了混合原始哈希码的高位和低位、以此加大低位的随机性、而且混合后的低位掺杂了高位的部分特征、这样高位的信息也被变相地保留下来 、经过扰动之后、有效减少了哈希冲突
至于这里为什么使用异或运行、因为在双目运算 & || ^ 中 异或是混洗效果最好的、结果占双目运算两个数的50% 、混洗性是比较好的
https://www.zhihu.com/questio...
https://codeday.me/bug/201709...
关于 JDK 1.7 扩容导致循环链表问题
下面是 JDK 1.7 的扩容代码
void resize(int newCapacity) { //传入新的容量
2 Entry[] oldTable = table; //引用扩容前的Entry数组
3 int oldCapacity = oldTable.length;
4 if (oldCapacity == MAXIMUM_CAPACITY) { //扩容前的数组大小如果已经达到最大(2^30)了
5 threshold = Integer.MAX_VALUE; //修改阈值为int的最大值(2^31-1),这样以后就不会扩容了
6 return;
7 }
8
9 Entry[] newTable = new Entry[newCapacity]; //初始化一个新的Entry数组
10 transfer(newTable); //!!将数据转移到新的Entry数组里
11 table = newTable; //HashMap的table属性引用新的Entry数组
12 threshold = (int)(newCapacity * loadFactor);//修改阈值
13 }
void transfer(Entry[] newTable) {
2 Entry[] src = table; //src引用了旧的Entry数组
3 int newCapacity = newTable.length;
4 for (int j = 0; j < src.length; j++) { //遍历旧的Entry数组
5 Entry<K,V> e = src[j]; //取得旧Entry数组的每个元素
6 if (e != null) {
7 src[j] = null;//释放旧Entry数组的对象引用(for循环后,旧的Entry数组不再引用任何对象)
8 do {
9 Entry<K,V> next = e.next;
10 int i = indexFor(e.hash, newCapacity); //!!重新计算每个元素在数组中的位置
11 e.next = newTable[i]; //标记[1]
12 newTable[i] = e; //将元素放在数组上
13 e = next; //访问下一个Entry链上的元素
14 } while (e != null);
15 }
16 }
17 }
我们先看看美团博客上面的例子
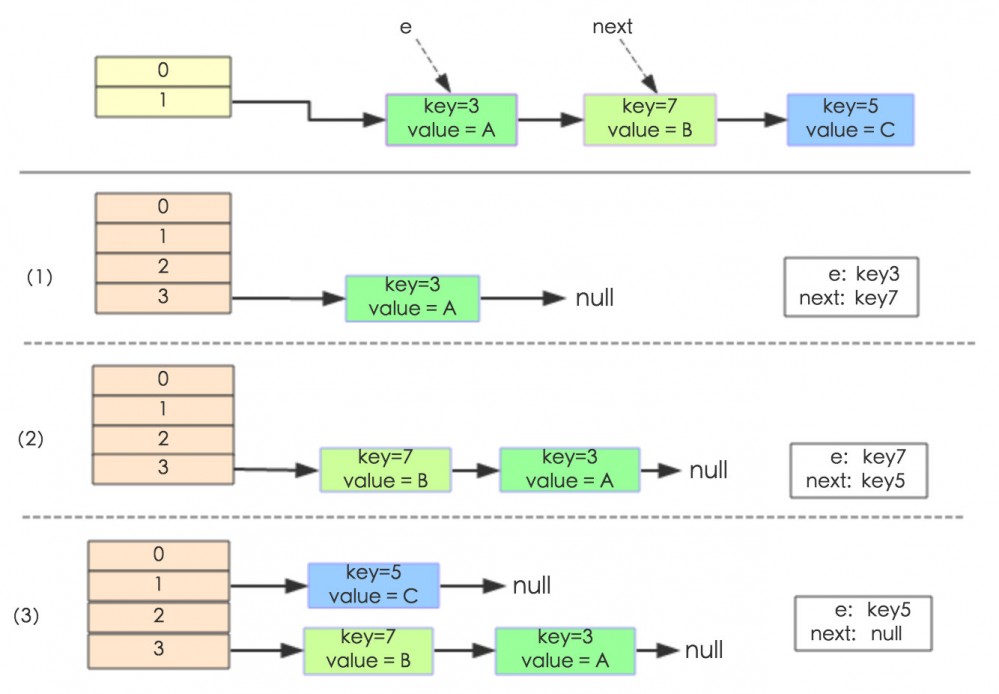
单线程环境下是正常完成扩容的、但是有没有发现、倒置了、key7 在 key3 前面了。这个很关键
我们再来看看多线程下、导致循环链表的问题
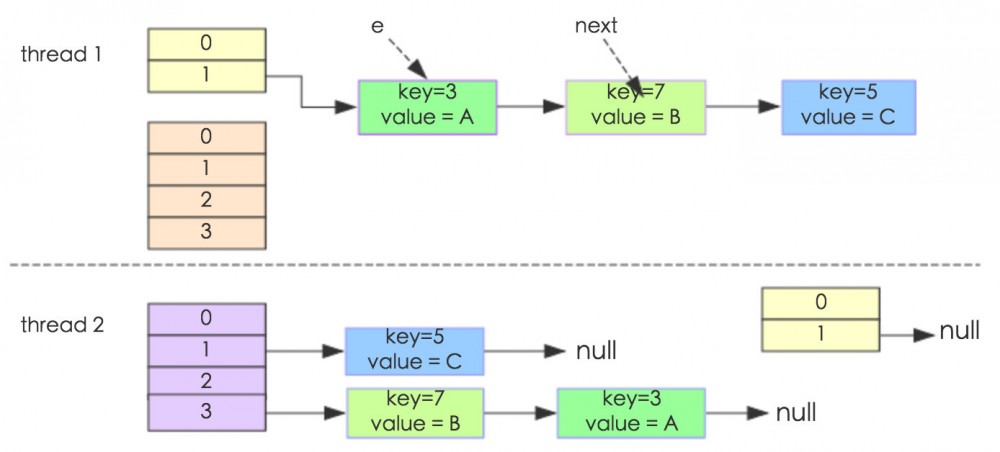
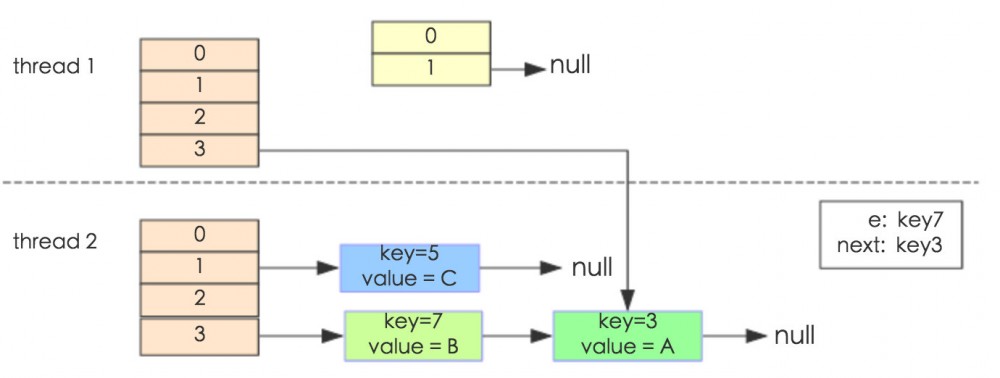
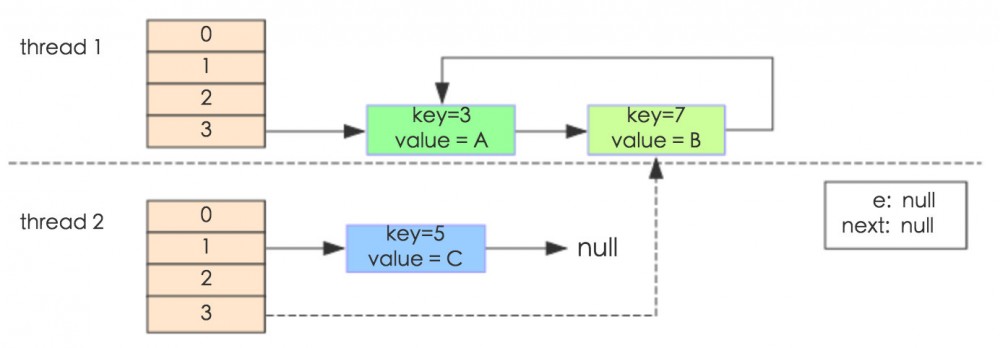
其实出现循环链表这种情况、就是因为扩容的时候、链表倒置了
而 JDK1.8 中、使用两个变量解决链表倒置而发生了循环链表的问题

Node<K,V> loHead = null, loTail = null; Node<K,V> hiHead = null, hiTail = null;
通过 head 和 tail 两个变量、将扩容时链表倒置的问题解决了、循环链表的问题就解决了
但是无论如何、在并发的情况下、都会发生丢失数据的问题、就比如说上面的例子就丢失了 key5
HashTable
遗留类、很多功能和 HashMap 类似、但是它是线程安全的、但是任意时刻只能有一个线程写 HashTable、并发性不如 ConcurrentHashMap,因为 ConcurrentHashMap 使用分段锁。不建议使用
LinkedHashMap
LinkedHashMap继承自HashMap、在HashMap基础上、通过维护一条双向链表、解决了HashMap不能随时保持遍历顺序和插入顺序一致的问题
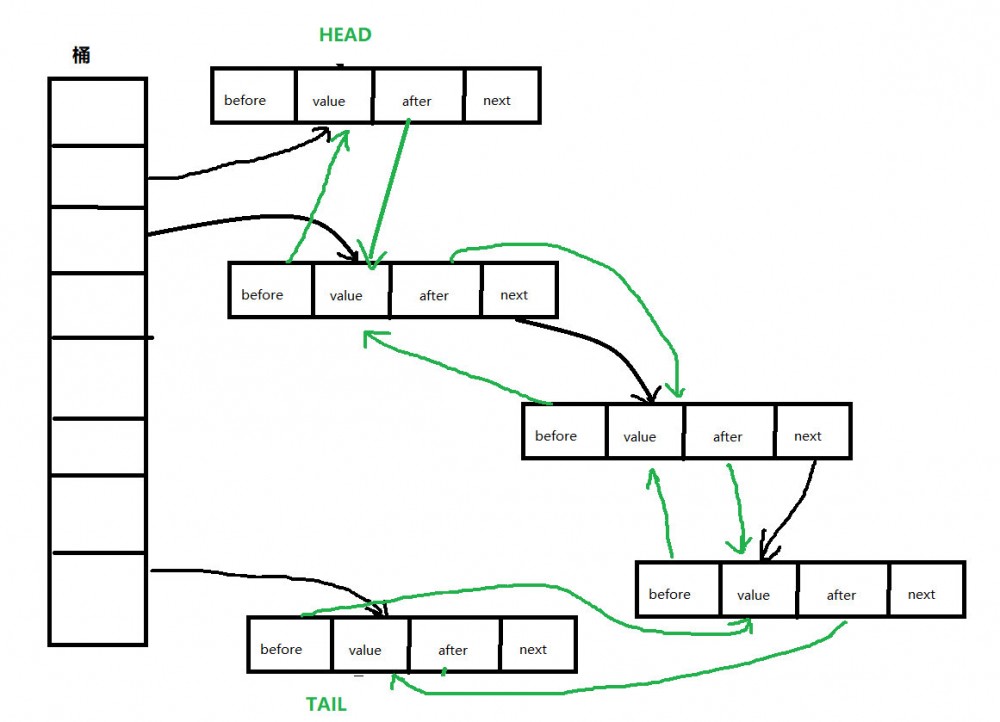
重写了 HashMap 的 newNode 方法
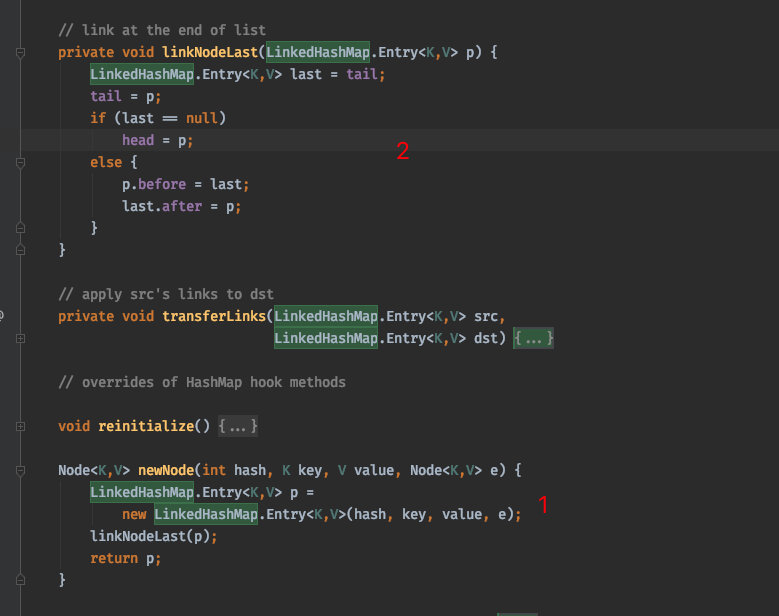
并且重写了 afterNodeInsertion 方法、这个方法本来在 HashMap 中是空方法
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
而方法 removeEldestEntry 在 LinkedHashMap 中返回 false 、我们可以通过重写此方法来实现一个 LRU 队列的
/** * The iteration ordering method for this linked hash map: <tt>true</tt> * for access-order, <tt>false</tt> for insertion-order. * * @serial */ final boolean accessOrder;
默认为 false 遍历的时候控制顺序
TreeMap
static final class Entry<K,V> implements Map.Entry<K,V> {
K key;
V value;
Entry<K,V> left;
Entry<K,V> right;
Entry<K,V> parent;
boolean color = BLACK;
TreeMap底层基于红黑树实现
Set

没啥好说的
Queue
PriorityQueue
默认小顶堆、可以看看关于堆排序的实现 八种常见的排序算法
public boolean offer(E e) {
if (e == null)
throw new NullPointerException();
modCount++;
int i = size;
if (i >= queue.length)
grow(i + 1);
size = i + 1;
if (i == 0)
queue[0] = e;
else
siftUp(i, e);
return true;
}
public boolean add(E e) {
return offer(e);
}
强烈推荐文章参考的美团的这篇文章、关于 HashMap 的
https://tech.meituan.com/2016...
正文到此结束
- 本文标签: 博客 update 本质 安全 遍历 并发 final Action node IDE 索引 value 删除 java bug cat CTO zab 锁 queue tab 数据 ConcurrentHashMap key http id 线程 空间 synchronized 参数 文章 源码 UI HashTable Collections src Collection 代码 ArrayList 美团 ACE 编译 map HashMap DOM rand consumer IO https 多线程 LinkedList list
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

