Java并发——线程池原理解析
可以说,线程池是Java并发场景中应用到的最多并发框架了。几乎所有需要异步或者并发执行的任务程序都可以使用线程池。在开发过程中,合理的使用线程池会带来以下3个好处:
- 降低资源的消耗。如果了解Java线程的前因后果,对于这一点应该很好理解。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
- 提高响应速度。当任务到达时,任务可以不同等到创建线程立即就能立即执行。
- 提高线程的可管理性。线程是稀缺资源,通过线程池框架可以进行统一的线程分配、监控、调优。
世界上没有完美无瑕的事情,任何事情都有正反两面。如果滥用线程池或者使用不当,也有可能带来安全隐患。因此,必须合理的使用线程池才能使得收益最大化。接下来,我们就来系统的了解线程池,以便能够达到“合理使用”的境界。
线程池的原理
当任务提交到线程池之后,线程池是如何处理这些任务的呢?它是这样处理的的:
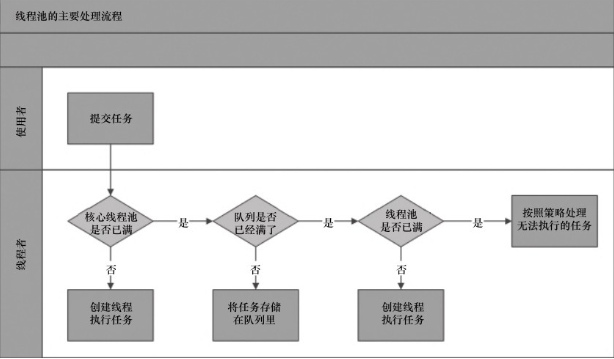
从以上图中,可以看见,当提交了一个新任务时,线程池的处理过程如下:
- 核心线程数corePoolSize是否已满?如果没有满,则创建线程(全局锁),并执行任务,否则进行下一步;
- 队列是否已满?如果没有满,则将任务入队,否则进行下一步;
- 线程池是否已满?如果没有满,则创建线程(全局锁),并执行任务,否则进行下一步;
- 到了这一步,说明线程池无法接收任务了,此时将执行拒绝策略。
以上2/3步骤是否可以调换顺序呢?实际上,线程池之所以采用以上的设计思路,是因为,1/3步骤都是要获取全局锁的。如果任务频繁提交执行,此时将加剧锁的竞争,而2步骤是不需要额外的全局锁的竞争。
带着以上的认知,我们来剖析一下源码:
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
// 首先获取ctl变量的值(ctl变量及其重要,在这里我们只需知道它可以同时代表线程数和线程池状态即可)
int c = ctl.get();
// 基于ctl计算出当前的线程数量,如果小于设定的核心线程数。
if (workerCountOf(c) < corePoolSize) {
// 则通过addWorker创建一个线程并执行当前任务,addWorker方法内部需要获取全局锁
if (addWorker(command, true))
return;
// 如果addWorker返回失败标志,则重新获取当前ctl的值。
c = ctl.get();
}
// 基于ctl获取当前线程池状态,如果是RUNNING状态并且任务添加到队列中
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
// 则重新检查线程池的状态,如果当前不是RUNNING状态了,则移除当前任务。
if (! isRunning(recheck) && remove(command))
如果成功,则执行拒绝策略
reject(command);
else if (workerCountOf(recheck) == 0) // 如果当前线程数为0
// 则通过addWorker方法初始化ctl
addWorker(null, false);
}
// 如果失败,则通过addWorker方法创建新的线程来执行任务,
// 如果addWorker方法返回false标志,说明此时创建新的线程来执行任务失败了。
// 此时说明线程池已满,或者线程池已经不是RUNNING状态了。
else if (!addWorker(command, false))
// 此时将执行拒绝策略
reject(command);
}
复制代码
通过以上源码解析,能够清晰的了解一个任务提交到线程池是如何处理的了。源码中有两个重要的地方还没有讲解。一是ctl变量的作用;二是addWorker方法的解析。这两个点可以说是线程池的精髓所在了。
ctl变量
ctl变量是一个AtomicInteger类型,它包含了两个概念:
- 线程池中的有效线程数,即当前的工作线程数;
- 线程池的状态
这就奇怪了, 为什么ctl可以同时表示数量和状态呢 ?其实,如果我们阅读源码比较多的话,会发现,Java中很多地方都有这种使用方式,其目的就是为了在保证性能时还尽可能的高效利用内存空间。因此常常会用一个变量表示多种业务状态。为了更加清晰的理解ctl变量,我们直接贴出源码的解释:
In order to pack them into one int, we limit workerCount to (2^29)-1 (about 500 million) threads rather than (2^31)-1 (2 billion) otherwise representable. If this is ever an issue in the future, the variable can be changed to be an AtomicLong, and the shift/mask constants below adjusted. But until the need arises, this code is a bit faster and simpler using an int.
以上大概意思就是:为了让有效线程数和线程池的状态能够用一个int变量表示,将线程数限制在了2^29-1(约为5亿),这样的话就可以用低29位来表示有效线程数,高3位来表示线程的状态。为了更好的理解,我们直接上源码:
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
private static final int COUNT_BITS = Integer.SIZE - 3;
private static final int CAPACITY = (1 << COUNT_BITS) - 1;
// runState is stored in the high-order bits
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;
private static int runStateOf(int c) { return c & ~CAPACITY; }
private static int workerCountOf(int c) { return c & CAPACITY; }
private static int ctlOf(int rs, int wc) { return rs | wc; }
复制代码
基于源码,可以得出它们的实际值:
COUNT_BITS = Integer.SIZE - 3;即:COUNT_BITS = 32 -3 = 29;
CAPACITY = (1 << 29) - 1;即:CAPACITY = 2^29 - 1 约等于5亿;
RUNNING = -1 << 29; --> 高3位为:111
SHUTDOWN = 0 << 29; --> 高3位为:000
STOP = 1 << 29; --> 高3位为:001
TIDYING = 2 << 29; --> 高3位为:010
TERMINATED= 3 << 29; --> 高3位为:011
有了以上的计算,我们再来看:
runStateO()方法是获取当前线程池状态的方法,它的计算公式为: ctl & ~ CAPACITY.
~ CAPACITY获取到的值实际上就是高3位为1,低29位为0. 因此 ctl & ~ CAPACITY 得到的实际上就是ctl高3位的值 。
同理,workerCountOf()方法获取到的实际上就是ctl低29位的值。表示为当前有效的线程数。
通过以上解析,应该就可以理解ctl变量的含义了!
addWorker()方法
在线程池中,线程并不是Thread,而是基于Thread包装成了一个Worker。Worker是ThreadPoolExecutor的一个内部类。通因此,addWorker()方法实际上就是基于当前线程池的状态来决定是否构建Worker并执行。Worker执行万当前任务后,并不会直接退出,而是循环获取队列中的任务来执行,从源码中我们能证明这个结论:
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
// 如果task不为空,则执行task。
// rugo task为空,则从队列中继续获取task。
while (task != null || (task = getTask()) != null) {
w.lock();
// 判断线程池的状态和当前task的中断标志,是否满足继续执行的条件。
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
// 钩子函数:执行task之前的钩子函数
beforeExecute(wt, task);
Throwable thrown = null;
try {
// 执行任务
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
// 钩子函数:执行task之后调用的钩子函数
afterExecute(task, thrown);
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}
复制代码
钩子函数
从源码中,我们可以得知,ThreadPoolExecutor框架预留了几个钩子函数.worker在执行任务的过程中,会触发钩子函数,如果我们需要执行一些特殊的业务(比如统计任务的执行时长),则可以继承ThreadPoolExecutor实现钩子函数来达到特定业务的目的。
| 钩子函数 | 说明 |
|---|---|
| beforeExecute() | 任务执行前触发 |
| afterExecute() | 任务执行后触发 |
| terminated() | 当线程池状态变成TIDYING时,会触发此方法 |
线程池的状态
线程池一共有5种状态。
| 状态 | 解释 |
|---|---|
| RUNNING | 运行状态。当线程池创建成功后,线程池的状态就是RUNNING状态了。此状态下可以接收新的任务和执行队列中的任务 |
| SHUTDOWN | 此状态下,线程池不再接收新的任务了,但是会将执行中的任务和队列中的任务执行完成。 |
| STOP | 此状态下,线程池不再接收新的任务;不再执行队列中的任务;会中断正在执行中的任务。 |
| TIDYING | 此状态下,线程池中的workCount=0,线程池将调用调用terminated()方法。 |
| TERMINATED | 当terminated()方法执行完成之后,线程池状态将变成TERMINATED,至此,线程池的生命周期完成。 |
线程池状态的流转:
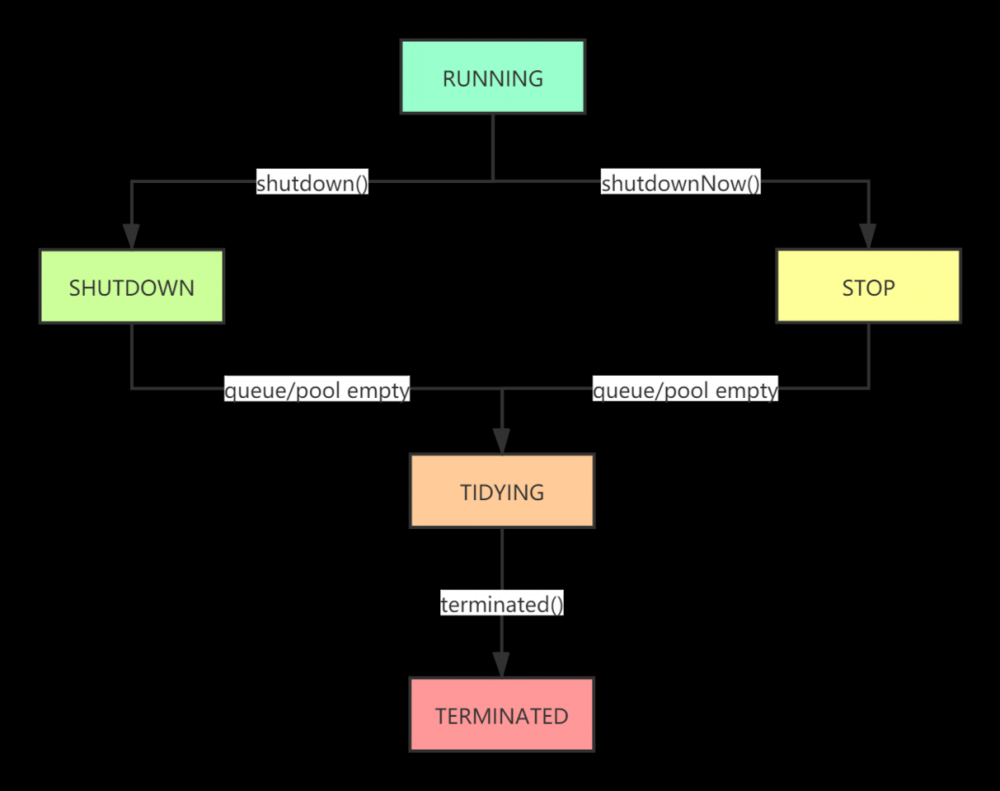
TIP:线程池状态的流转和线程状态的流转是完全不一样的概念。
线程池的使用
基于以上介绍,我们对线程池的原理已经了然于胸。接下来,通过一个例子来看看实战中线程池的使用方式和技巧。
快捷创建线程池
创建线程池的方式有很多种。比如:
// 1.创建固定大小的线程池 Executors.newFixedThreadPool(); // 2.创建一个基于SynchronousQueue队列的线程池.(此队列的特性在前文是有解析) Executors.newCachedThreadPool(); // 3.创建一个具有延时功能的线程池(实际上就是基于DelayQueue实现,此队列在前文中解析) Executors.newScheduledThreadPool(); // 4.创建一个只有一个线程的线程池 Executors.newSingleThreadExecutor(); 复制代码
以上是快捷创建线程池的的4种方式,其实如果我们再深入理解一波的话,可以发现其实他们底层都是基于ThreadPoolExecutor提供的构造方法构建的线程池。这4种方式创建出来的线程池都具备一定的特性在里面,如果对于队列理解透彻的话,可以发现,它们的本质其实就是选择的队列不同。从而可以基于队列提供的特点实现特殊的功能。
在实战中,除非应用场景比较简单,任务量不是很大的情况下,我们可以采用这种快捷创建线程池的方式。但如果我们在大中型工程中,则最好基于ThreadPoolExecutor自定义创建线程池,这样可以更加贴切实际的场景使用。
基于构造方法创建线程池
ThreadPoolExecutor提供了以下几个构造方法:
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue); public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, RejectedExecutionHandler handler); public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory); public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler); 复制代码
可以发现,通过原生构造器来构建线程池,是最灵活的。因此,在《阿里巴巴Java开发规范》中也强烈建议采用这种方式来创建线程池。每个参数的含义如下:
| 参数名 | 含义 |
|---|---|
| corePoolSize | 核心线程数 |
| maximumPoolSize | 最大线程数 |
| keepAliveTime | 当线程数大于核心线程数,多余的线程的存活时长,和unit配合使用 |
| unit | 和keepAliveTime配合使用 |
| workQueue | 工作队列。当核心线程数满时,任务会先入队。若无特殊要求,应该尽量选择有界队列!否则当任务激增时,有可能撑爆内存导致性能下降甚至崩溃。 |
| threadFactory | 线程工厂类,用于创建线程。如果没有指定,则采用默认的工厂类 |
| handler | 任务拒绝策略。当线程池不能再接收新的任务时,将执行任务拒绝策略。如果没有指定,则采用默认的拒绝策略。 |
任务拒绝策略
当线程池满了之后,将会执行拒绝策略。线程池提供了4种拒绝策略。如下:
| 拒绝策略 | 说明 |
|---|---|
| AbortPolicy | 当线程池满时,将会拒绝接收新任务,并抛出RejectedExecutionException。如果没有指定拒绝策略,此为默认策略 |
| CallerRunsPolicy | 当线程池满时,将会使用任务提交者所在的线程来执行这个任务。线程池本身会丢弃掉这个任务。 |
| DiscardPolicy | 当线程池满时,将会默默地丢弃掉这个任务。tips:在实际开发当中,如果任务不影响业务,则可以采用此策略,否则断然不可采取这个策略。 |
| DiscardOldestPolicy | 当线程池满时,将会默默地丢弃掉队列最前端的任务。然后执行提交的任务。tips:和以上一样 |
关闭线程池
关闭线程池是很有必要的。当应用程序需要退出时,可以通过注册回调函数来关闭线程池。如果我们暴力关闭应用程序的话,会导致正在执行的任务和队列中的任务丢失。在企业工程中,这一点千万注意。 线程池提供了两种关闭方法:
| 关闭方式 | 说明 |
|---|---|
| shutdown() | 当调用此方法时,线程池状态会变成SHUTDOWN状态,此时线程池将不会再接收新的任务,但以及接收的任务会执行完毕。 |
| shutdownNow() | 当调用此方法时,线程池状态会变成STOP状态,此时线程池将不会再接收新的任务,并且会中断所有正在执行中的任务以及丢弃掉队列中的任务。 |
在实际工程中,具体采取哪种方式,应该根据实际情况来抉择。如果任务对业务有影响,则应当选择shutdown(),否则可以视情况选择shutdownNow()。
线程数的设置策略
在Java应用中,线程属于稀有资源。那么线程数是设置的越大越好么?非也。在计算机体系中,如果想让性能发挥极致,应该是各个子系统之间的合理配置使用。对于线程数而言也是如此。要想合理的设置线程数,就必须首先分析人物的特性。可以从以下几个角度来分析:
- 任务的性质:CPU密集型、IO密集型、混合型。
- 任务的优先级:高、中、低。
- 任务的执行时间:长、中、短。
- 任务的依赖性:是否依赖其他资源,比如数据库连接。
我们可以根据任务的不同特性来综合考虑线程数的设置。一般而言。如果是CPU密集型,则应该分配尽可能小的线程数:通常情况下,可以设置为CPU核数 + 1;如果是IO密集型,则线程并不总是在执行任务,则应该分配尽可能大的线程数:通常情况下,可以设置为2 * CPU核数;如果是混合型,则可以将任务拆分成一个CPU密集型和一个IO密集型,只要两个任务执行的时间不会相差太大,则性能会比串行执行的效率要高,如果拆分后任务执行相差的时间过大,则没有必要拆分。
线程池的监控
通过以上的介绍,如何用好线程池应该不是问题。对于一个完善的应用而言,应当还要有良好的监控能力,以便在任务执行出现问题时,可以快速的定位、分析、解决问题。
ThreadPoolExecutor提供了一些基本且好用的方法来监控线程池的运行情况:
| 方法名 | 说明 |
|---|---|
| getTaskCount() | 线程池队列中需要执行的任务数量 |
| getCompletedTaskCount() | 线程池中已经执行完成的任务数量 |
| getActiveCount() | 线程池中正在执行任务的线程数量 |
如果我们想要更加全面的监控线程池的运行状态以及任务的执行过程。可以继承ThreadPoolExecutor来自定义线程池。
总结
本篇文章围绕ThreadPoolExecutor,系统介绍了线程池的实现;以及实际项目中如何正确的使用线程池。通过本篇文章的写作,自己对于线程池的认识有多了一些不一样的感觉。比如clt变量的设计真的很精妙。像Doug Lea大神致以崇高的敬意!

正文到此结束
热门推荐










相关文章

近期评论
-
不会英语啊。
-
前100名用户会展示特殊的纪念徽章
-
-
https://pplx.ai/floraliu4199466 这个链接打不开是什么原因?
-
-
-
-
来看看,最近更新了一波,顺着友联过来的,几年过去了,网站越搞越好,厉害
-
哥太牛了
-
是呀,看您的IP显示在美国,还以为您移民了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

