QMQ在携程的落地实践
QMQ(Qunar Message Queue)诞生于去哪儿网,初版基于MySQL存储。随着集团业务系统越发倚重消息解耦上下游,业务量的上涨随之带来消息量的增长,MySQL作为存储的瓶颈也越发明显。
比较自然的解决方案有两个:1)分库分表;2)换存储。与业界众多出名的消息队列(Kafka、RocketMQ、Pulsar等)一样,QMQ也走上了基于文件存储的分布式消息系统自研之路(详细设计请关注QMQ开源: https://github.com/qunarcorp/qmq )。后文的介绍, QMQ均指基于文件存储的版本。
在携程落地的过程中,我们主要和两类问题打交道:网络和磁盘IO。
一、网络
网络问题多种多样,因而也诱发了一系列问题,和大家分享5种比较典型的场景。
1.1 OOM
场景来自某台Broker slave机器OOM告警,问题出在堆外内存分配上,图1是堆外内存泄露现场。QMQ网络通信基于netty开发,接收消息时使用堆外内存;拉取消息时,使用FileRegion和少量堆内内存;slave从master同步消息文件,使用FileRegion。FileRegion直接将消息文件写入到发送缓冲区,不会分配堆外内存,排除。接收消息放入Receiver队列,如果消息落磁盘操作阻塞,消息积压在队列(没有回压机制,而channel是auto read的,只要有消息进来,就会不停的放入队列),势必引发堆外内存上涨,但只有master提供消息服务,排除。
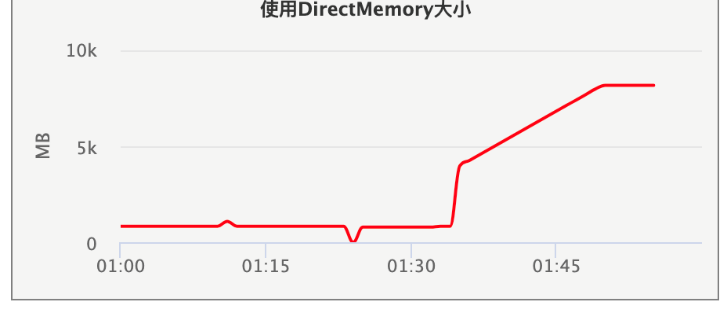
引起关注的是稳定的增长速率:300MB/分钟,即50MB/10秒。50MB是个特殊的数字,我们有一个消息索引备份服务,会实时从slave上拉取消息索引,我们设置了每次拉取的上限。10秒则是索引备份服务请求的超时时间。如果,备份服务的请求抵达slave,slave实时计算了索引、分配了内存,但数据未被备份服务接收,10秒后超时,重试。似乎一切都能解释了,查看了当时的备份服务的日志(图2所示),吻合。

备份服务和slave是tcp单连接通信,备份服务和slave是一对一关系,当slave上tcp连接的发送缓冲区满了后,索引数据的网络写入会感知到失败,我们的服务应该是能感知到才对。原来,FileRegion的操作,不会影响netty的水位线,因而代码中没有做channel.isWritable的判断就直接channel.writeAndFlush了。后面因为需求,增加了slave实时计算索引的功能,复用了以前的代码,导致数据积压在netty的OutboundBuffer中,从而引发了堆外内存泄露。至于备份请求能到slave,响应未能从slave送出去,是网络故障导致。
结论:netty write操作前,须判断isWritable。
1.2 文件句柄耗尽
场景来自客户端与MetaServer 新建tcp连接失败的告警。图3是某一台MetaServer的网络连接现场。tcp连接是需要分配文件句柄的,机器上设置的最大可用文件句柄为65536,显然tcp建连失败,是因为此机器上的文件句柄耗尽导致。
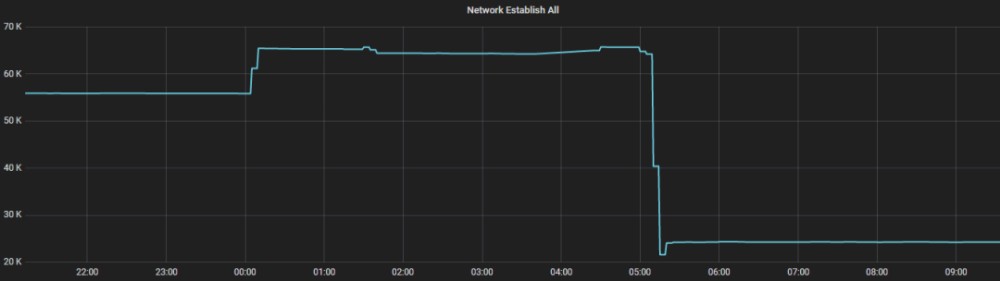
QMQ一个客户端实例(进程)只会与MetaServer创建一个tcp连接,正常情况下不可能出现文件句柄耗尽。为了排查泄露的连接,分别在某台客户端机器和MetaServer机器上执行ss。
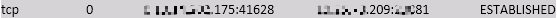

显然,的确发生了泄露。客户端因为某些原因关闭了54026(譬如,机器掉电或者局部网络隔离触发了tcpkeepalive机制等),如果服务端未能感知到客户端54026的关闭,54026就泄露了。客户端与MetaServer通信基于netty,反查代码,MetaServer未设置IdleStateHandler以及ChannelOption.SO_KEEPALIVE,意味着54026非正常关闭后,MetaServer失去了感知手段,泄露成为必然。
结论:客户端和服务端双向idle检测很有必要。
1.3 Broker未被摘除
Broker粘滞在某台MetaServer上定时心跳,当心跳间隔超时后,只能由被粘滞的MetaServer将其状态置为不可读写(NRW),从生产者、消费者路由列表中摘除,如图6所示。
这种去中心化的心跳保活机制有个缺陷:当Broker与被粘滞的MetaServer同时故障或被粘滞的MetaServer与DB局部网络隔离后,Broker不会被摘除,生产者和消费者将引发生产、消费异常,只能依赖客户端熔断机制弥补。在有一次QMQ单边机房演练中(关闭单边机房的QMQ服务)就触发了上述场景。
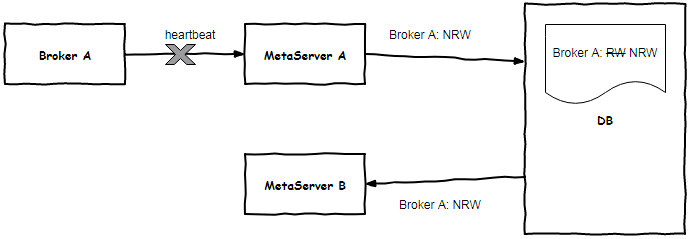
我们重新设计了保活机制,所有MetaServer都定时扫描DB中Broker状态表,一旦发现broker失联,就尝试将其置为NRW。
结论:分布式需要多考虑些网络隔离。
1.4 java.net.SocketTimeoutException: Read timed out
生产者、消费者应用启动时,通过与MetaServer心跳获取路由信息,MetaServer将客户端元数据存储于MySQL。在一次机房断网演练恢复后,仍出现大量线程被挂起情况,堆栈如下图,大约15分钟,抛出java.net.SocketTimeoutException: Read timed out。
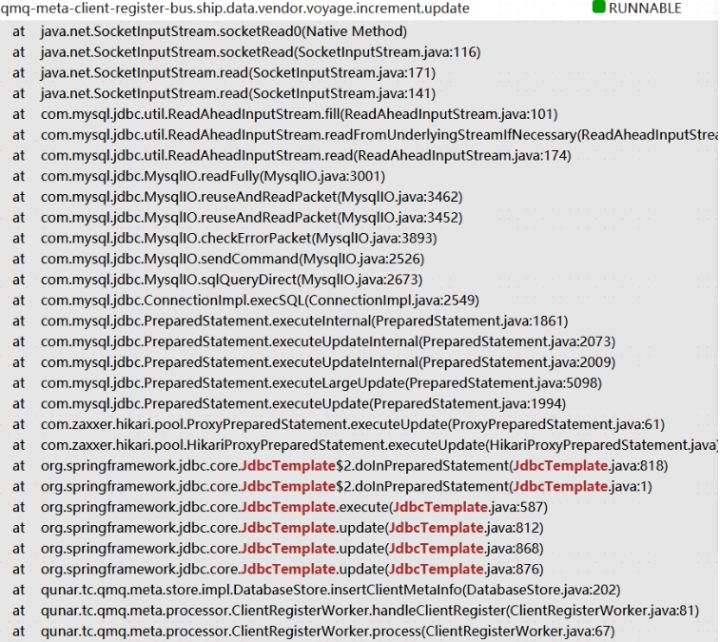
堆栈显示,当前线程阻塞在等待MySQL响应读取上,比较容易联想到是机房断网演练导致,且可能超时设置不合理导致。实际上,我们使用的DataSource并未设置SO_TIMEOUT,意味着无超时时间。可实际现象为何是15分钟,应用层感知到socket timeout?
其实,这是linux tcp中比较常见的一类问题。对于一个ESTABLISHED的tcp连接,发送端将应用层数据写入发送缓冲区,内核tcp协议栈负责保证数据可靠传递到接收端。为了保证可靠,tcp采用超时重传机制,重试间隔根据退避算法计算得出,相关代码位于net/ipv4/tcp_timer.c#tcp_retransmit_timer,截取部分如图8所示。

简言之,tcp重传定时器定时时间是上次rto的两倍,最大不超过TCP_RTO_MAX(120S),最小不能小于TCP_RTO_MIN(200ms),而最终判定是否超时,则与内核参数net.ipv4.tcp_retries2有关,相关代码位于在net/ipv4/tcp_timer.c#retransmits_timed_out,截取部分如图9所示。

默认net.ipv4.tcp_retries2取值15,即代码截图中的boundary,rto_base对于ESTABLISHED状态的连接取值TCP_RTO_MIN(200ms)。当应用层未设置SO_TIMEOUT,即timeout == 0,整个重传耗时大于(((2 << 9) – 1) * 0.2 + (15 -9) * 120)后,约15分钟,将被认定为超时,关闭连接,socketRead0将抛SocketTimeoutException: readtimed out。
结论:DataSource须设置SO_TIMEOUT。
1.5 大流量
某个周六的中午,某台Broker的端到端延迟(从消息生产到被消费的时间差)突然告警,从平时的20ms蹿升到几十秒。将机器拉出解除故障后,着手排查,发现full gc了,图10所示。从日志分析引发fgc是因为堆外内存不足,主动触发了system.gc()。
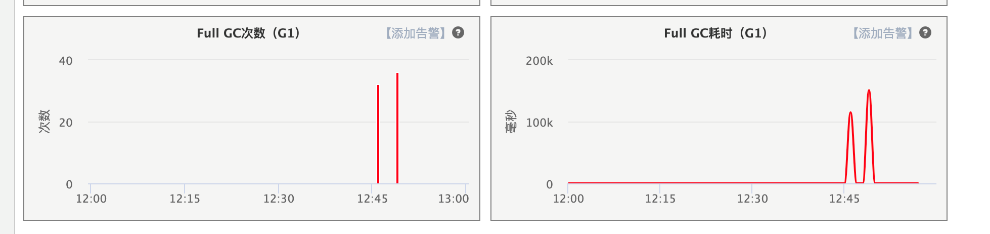

堆外内存耗尽,是由于一波突发生产消息流量导致,而根因是broker的消息接收模型导致。netty decode handler切割出消息(ByteBuf.slice())后,将消息放入一个无界的接收队列,netty的worker线程就返回了,然后由一个单线程的消息处理线程从接收队列中取出消息写入磁盘。最终堆外内存归还到池子中,须待slave消息同步完成。
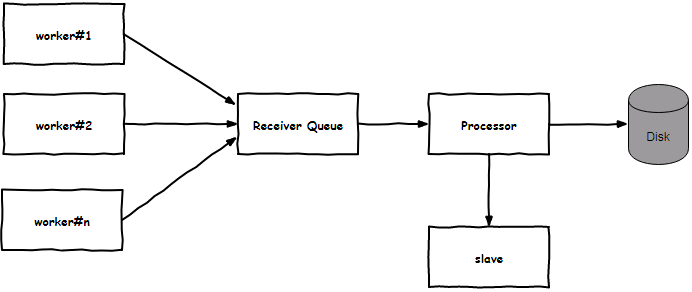
无界接收队列不应该承担全部的责任,其本质还是需要有套回压机制,譬如,当检测到接受队列大小超过阈值后,关闭channel的auto read机制。最终我们从如下几个角度做了针对突发大流量的防御:
1)decode handler中,检测单包请求大小,对于超过阈值的,直接关闭连接。可以有效避免,非法客户端发送超大消息,导致netty分配超大内存;
2)生产、消费限速;
3)限制接收队列大小,限制消息在队列中停留的时间,超时后,直接丢弃,释放内存;
4)监控写io耗时,超过阈值后,暂停接收消息流量。
结论:系统须考虑回压机制。
二、磁盘IO
任何基于文件存储的系统,磁盘IO问题都是不得不考虑的问题。我们的机器未使用SSD,都是基于机械硬盘的存储上的优化,主要介绍两类场景。
2.1 堆积消息拉取
在介绍这个问题前,先介绍一下QMQ的存储模型,如图13所示。所有主题的消息都顺序写入一个文件,然后为每个消息主题构建索引文件,拉取消息的时候,根据消息主题索引文件从而读取到消息。但由于所有消息主题共用一个文件,极限情况,拉取10条消息,可能会读取10次消息文件。
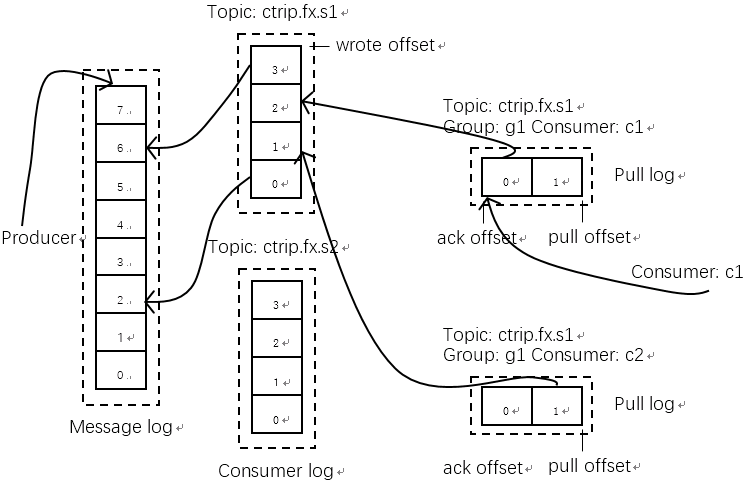
由于linux的page cache机制,对于实时拉取而言,可能读取全部命中page cache,并不会产生读IO事件。但堆积长时间的消息,很大程度上其消息已经换出page cache,而离散的消息,将实实在在的产生多次读IO,影响系统的io util,最终影响整个系统的生产、消费。
QMQ的作者刀刀给出了一种解决方案: 如何用不到两千块大幅度提升QMQ性能 ,即尝试对消息文件进行排序,能缓解堆积消息拉取对系统带来的冲击。本文不做过多介绍,感兴趣的同学可以跳转至刀刀的文章阅读。
除了上述方案,我们还在物理隔离上做了一些尝试。概括来说就是将产生堆积的消费组(一般是大数据job类)从实时集群剥离出来,我们将消息镜像到hbase,消费者通过hbase消费。
结论:冷热分离可以尝试
2.2 大消息
在消息治理的过程中,我们发现有一定比例主题的消息体有超过100KB。如果能减少消息体大小,对系统的IO显然能起到减负效果。于是,我们推出了生产者消息压缩。压缩效率5到8倍,如图14展示了某个主题消息压缩前后的监控数据。
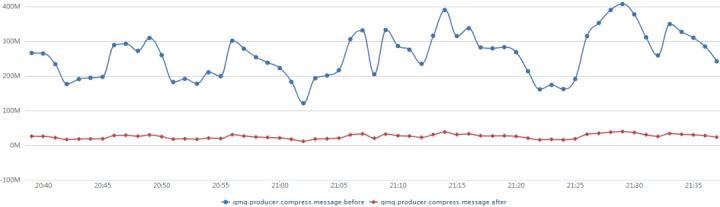
结论:控制写入磁盘量来缓解IO。文件编码优化也不失为一种选择。
三、最后
在实践中会比本文遇到的case更多、更复杂:客户端容器与宿主出现丢包、中间网络设备出现包错乱、客户端堆内存居高不下、服务端TCP重传机制“失效”、服务端IO持续偏高、RAID卡电池异常、RAID卡固件版本过低等,本文旨在抛砖引玉。
后续,我们的工作将从下面几个方面入手:文件编码优化(譬如varint替代定长、timestamp压缩)、page cache使用优化(快手kafka解决方案)、消费者拉取重定向(冷热消息分离,rocketmq重定向到slave,可以考虑HDFS等)、内核升级(引入bcc)排查长尾问题。
【作者简介】
Magiccao,携程软件开发工程师,热衷网络、操作系统相关技术。
正文到此结束
- 本文标签: http tab Master HDFS Full GC 代码 开发 linux message https RocketMQ UI 实例 src 协议 MQ 集群 索引 GitHub 操作系统 Job git 分布式 Region TCP dataSource 备份 IO 进程 本质 Netty 参数 文章 ip id sql 时间 同步 java cache 线程 工程师 大数据 软件 Architect db 服务端 HBase 分布式消息系统 需求 开源 mysql queue 模型 数据 消息队列
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章

近期评论
-
主要用的是AI
-
博主的博客用的什么技术栈,内容都是干货,赞
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
-
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

