SpringCloud- 第八篇 Hystrix熔断机制(五)
1:雪崩效应概述
多个微服务之间调用的时候,假设微服务A调用微服务B和微服务C,微服务B和微服务C又调用其它的微服务,这就是所谓的“扇出”。如果扇出的链路上某个微服务的调用响应时间过长或者不可用,对微服务A的调用就会占用越来越多的系统资源,进而引起系统崩溃,所谓的“雪崩效应”
2:熔断机制概述
熔断机制是应对雪崩效应的一种微服务链路保护机制。当扇出链路的某个微服务不可用或者响应时间太长时,会进行服务的降级,进而熔断该节点微服务的调用,快速返回错误的响应信息。当检测到该节点微服务调用响应正常后,恢复调用链路。 在Spring Cloud框架里,熔断机制通过Hystrix实现。Hystrix会监控微服务间调用的状况,当失败的调用到一定阈值,缺省是5秒内20次调用失败,就会启动熔断机制。熔断机制的注解是@HystrixCommand。
3: 熔断类型
在Hystrix里面,熔断又分为三种情况:半熔断、熔断打开、熔断关闭
- 熔断打开:请求不再进行调用当前服务,内部设置时钟一般为MTTR(平均故障处理时间),当打开时长达到所设时钟则进入半熔断状态
- 半熔断: 部分请求根据规则调用当前服务,如果请求成功且符合规则则认为当前服务恢复正常,关闭熔断
- 熔断关闭: 熔断关闭不会对服务进行熔断
4: 断路器图解
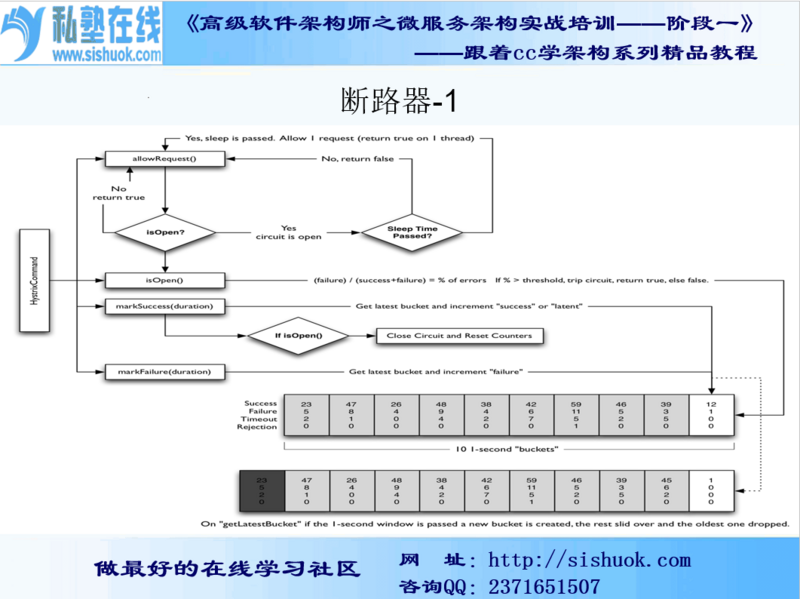
5:断路器在什么情况下开始起作用
涉及到断路器的三个重要参数:快照时间窗、请求总数阀值、错误百分比阀值。
- 快照时间窗:断路器确定是否打开需要统计一些请求和错误数据,而统计的时间范围就是快照时间窗,默认为最近的10秒。
- 请求总数阀值:在快照时间窗内,必须满足请求总数阀值才有资格熔断。默认为20,意味着在10秒内,如果该hystrix命令的调用次数不足20次,即使所有的请求都超时或其他原因失败,断路器都不会打开。
- 错误百分比阀值:当请求总数在快照时间窗内超过了阀值,比如发生了30次调用,如果在这30次调用中,有15次发生了超时异常,也就是超过50%的错误百分比,在默认设定50%阀值情况下,这时候就会将断路器打开。
6:断路器开启或者关闭的条件
- 当满足一定的阀值的时候(默认10秒内超过20个请求次数)
- 当失败率达到一定的时候(默认10秒内超过50%的请求失败)
- 到达以上阀值,断路器将会开启
- 当开启的时候,所有请求都不会进行转发
- 一段时间之后(默认是5秒),这个时候断路器是半开状态,会让其中一个请求进行转发。如果成功,断路器会关闭,若失败,继续开启。重复4和5
7:断路器打开之后
- 再有请求调用的时候,将不会调用主逻辑,而是直接调用降级fallback。通过断路器,实现了自动地发现错误并将降级逻辑切换为主逻辑,减少响应延迟的效果。
- 原来的主逻辑要如何恢复呢?
对于这一问题,hystrix也为我们实现了自动恢复功能。
当断路器打开,对主逻辑进行熔断之后,hystrix会启动一个休眠时间窗,在这个时间窗内,降级逻辑是临时的成为主逻辑,当休眠时间窗到期,断路器将进入半开状态,释放一次请求到原来的主逻辑上,如果此次请求正常返回,那么断路器将继续闭合,主逻辑恢复,如果这次请求依然有问题,断路器继续进入打开状态,休眠时间窗重新计时。
8:线程隔离示意图
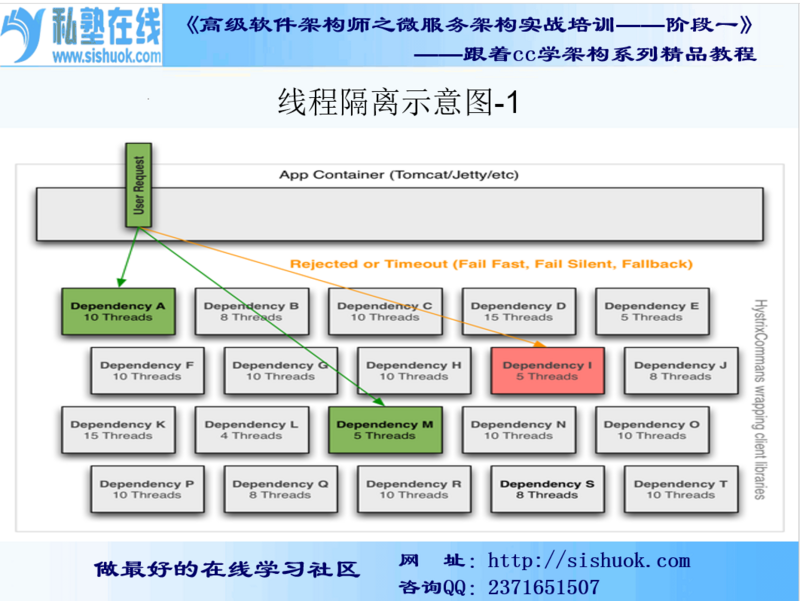
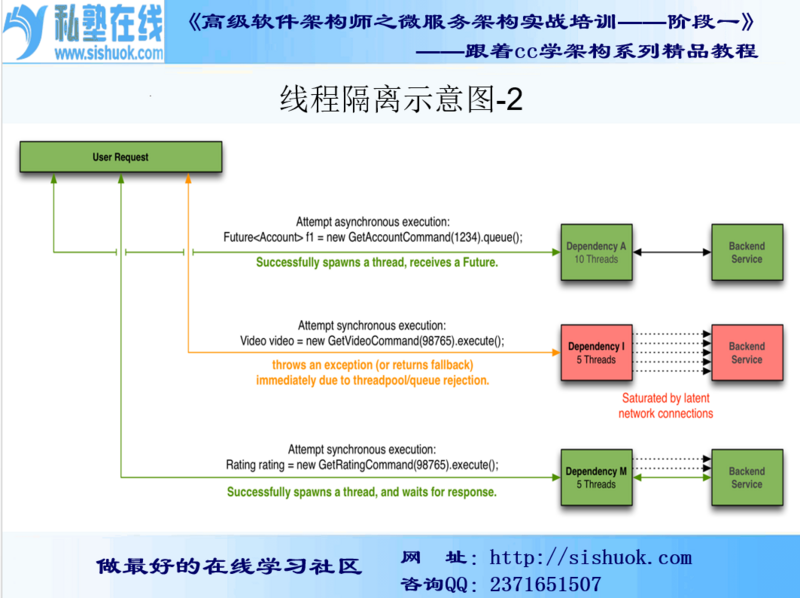
9:依赖隔离
Hystrix提供了两种隔离策略:线程池隔离和信号量隔离,默认采用线程池隔离。
- 线程池隔离
Hystrix使用舱壁模式来实现线程池的隔离,它会为每一个Hystrix命令创建一个独立的线程池,不同服务通过使用不同线程池,彼此间将不受影响,这样就算某个在Hystrix命令包装下的依赖服务出现延迟过高的情况,也只是对该依赖服务的调用产生影响,而不会拖慢其他的服务
这种方式需要为每个依赖的服务申请线程池,有一定的资源消耗;通过线程池大小可以控制并发量,当线程池饱和时可以提前拒绝服务,防止依赖问题扩散。建议线程池不要设置过大,否则大量堵塞线程有可能会拖慢服务器
- 线程池隔离的好处
1:应用自身得到完全的保护,不会受不可控的依赖服务影响。
2:可以有效的降低接入新服务的风险
3:当依赖的服务从失效恢复正常后,它的线程池会被清理并且能够马上恢复健康的服务,相比之下容器级别的清理恢复速度要慢得多。
4:当依赖的服务出现配置错误的时候,线程池会快速的反应出此问题(通过失败次数、延迟、超时、拒绝等指标的增加情况)。同时,可以在不影响应用功能的情况下通过实时的动态属性刷新来处理它。
5:当依赖的服务因实现机制调整等原因造成其性能出现很大变化的时候,此时线程池的监控指标信息会反映出这样的变化。同时,可以通过实时动态刷新自身应用对依赖服务的阈值进行调整以适应依赖方的改变。
10:信号量隔离
- 线程隔离会带来线程开销,有些场景(比如无网络请求场景)可能会因为用开销换隔离得不偿失,为此Hystrix提供了信号量隔离,当服务的并发数大于信号量阈值时将进入fallback。
- 实现方式是使用一个原子计数器(或信号量)来记录当前有多少个线程在运行,请求过来了,先判断计数器的数值,若超过设置的最大线程个数则丢弃该类型的新请求,若不超过则执行计数操作请求来计数器+1。
信号隔离与线程隔离最大不同在于执行依赖代码的线程依然是请求线程;而线程池方式下业务请求线程和执行依赖的服务的线程不是同一个线程
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

